AI舞会:基础模型 vs. 微调模型
嘿,DJ先生!我应该使用哪个大型语言模型?
由Ezequiel Lanza(英特尔AI开源布道师)主持
在进行任何语言项目的开始阶段,从事人工智能开发的开发人员必须做出一个重要决策。你会使用基础模型还是微调模型?你如何决定?如果你曾经策划过一次派对,这就像选择一个DJ一样。
想象一下,你正在计划一场活动,你需要为晚间娱乐选择一位DJ。你会选择那些一直坚持播放经典曲目的DJ,还是选择那些通过深入了解调控来提供令人震撼、独特体验的DJ呢?你会选择那些播放各种经典曲风的广泛音乐混搭,迎合大众口味的DJ吗?还是会选择那些给DJ Kool Herc都感到嫉妒的嘻哈音乐播放列表的DJ呢?
答案取决于您希望举办的派对类型 - 就像选择正确的语言模型取决于您希望实现的结果类型一样。在本文中,我们将探讨经典训练的基础模型和微调模型之间的差异,以帮助您决定哪种类型的大型语言模型最适合您的项目。
基础模型(FM):LLMs的婚礼DJ
基础模型就像婚礼DJ一样,它们都经过训练,通过消化大量的普通数据(或者在DJ的情况下,从布鲁诺·马尔斯到ABBA再到仙妮亚·特温的音乐)来获得大众的吸引力。基础模型并不是为了解决特定任务而设计的,而是为了从数据中捕捉一般信息,例如语义、语法和基本事实-就像婚礼DJ从广泛的歌曲集合中选择和播放音乐,以满足从新娘到那个你没想到会真的出现的表亲的所有人的喜好。
GPT、LLaMA和Bloom都是基础模型的示例。训练这些模型需要大量的数据,这在数据需求、计算资源(需要大型分布式计算系统)和技术专长方面带来了挑战。由于训练和部署成本高昂,除了像埃隆·马斯克或泰勒·斯威夫特这样的人,大多数个人无法负担得起单独训练基础模型,需要多个利益相关者的帮助。例如,据估计,Meta公司花费了高达1000万美元来训练LLaMA模型,试着在Concur中报销这笔开销吧。
优化模型:完美的播放列表
一个想要专攻某一特定音乐风格的DJ,需要吸收并专注于那个年代的所有热门歌曲,就像一个经过精调的LLM专门训练特定数据集一样。将一个已经研究了各种音乐艺术家、风格和流派的婚礼DJ转变成专攻80年代音乐的DJ所需时间较短,就像对基础模型进行精调的过程比从零开始构建基础模型所需的硬件资源更少,时间更短。
任何具备特定数据集的开发者都可以对基础模型进行微调,以适应从音乐到医学等特定主题的需求。开放源代码社区在Hugging Face上提供了精细调整的模型,使得找到适合特定需求的定制数据库变得容易。举个例子,如果你需要医疗帮助,你可以发现ChatDoctor,它是一个出色的经过精细调整的模型,能够理解患者需求、提供经过深思熟虑的建议,并在医学相关领域提供有价值的帮助。它是基于特定医生与患者互动的数据进行培训的,使用LLaMA作为其基础模型。
然而,并非所有的微调模型都是为了响应特定任务而设计的;有些模型旨在利用更少的参数来减少硬件需求,从而寻找相似的结果。一个很好的例子是最近推出的 Intel Neural Chat(https://huggingface.co/Intel/neural-chat-7b-v3-3),这是一个基于开源基础模型 Mistral 7B(来自 Mistral AI)的微调模型。本文将解释如何使用 Intel® Gaudi® 2 加速器和诸如 Intel® Extension for Transformers 这样的软件优化来微调 Mistral 7B 模型,帮助压缩模型,如量化、蒸馏和修剪等。
基础模型与微调模型的实际应用
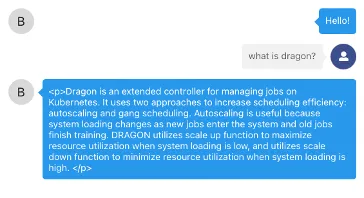
假设我们有一个经过Kubernetes信息微调的模型,并且我们想要使用它来回答领域特定的问题。在我们的情况下,我们想要询问LLM来定义"Dragon",一个用于管理Kubernetes集群中分布式深度学习作业的调度和扩缩容控制器。
让我们问ChatGPT。

现在,让我们询问一个在Kubernetes和容器上进行了优化的模型,“龙”是什么:
所以,你应该使用哪个模型呢?
没有确定的规则来确定哪种模型更好;相反,它取决于与您的特定环境最相符合的是什么。然而,有三个因素可以指导您的决策过程:范围和多样性:
- 基础模型(FMs):当需要一个广泛、多用途的语言模型来完成一般任务,比如情感分析或常见查询时,可选择使用基础模型(FMs)。
- 细调模型(FTMs):根据任务特定要求选择FTMs,定制和在特定领域的专业知识至关重要。
资源效率
- 基础模型(FMs):考虑到训练FMs所需的大量计算资源和成本,以及可访问的选择,无论是免费下载还是付费APIs。
- 精细调校模型(FTMs):评估快速且资源消耗较少的精细调校过程,使其成为具有有限资源的特定应用的实用选择。
定制和隐私
- 基础模型(FMs):考虑到FMs的通用能力和开放性,使其适用于各种应用。在选择像Falcon或Dolly这样的免费可访问模型和像GPT-4这样的独有API之间,评估技术能力和许可问题之间的权衡。
- 精细调整模型(FTMs):利用FTMs进行定制,尤其在需要保护隐私的场景中,如医疗保健。在考虑特定用例相关的隐私影响时,探索在Hugging Face等平台上的预训练模型,以便快速部署。您需要有一定数量的例子来优化您的模型。
既然您已经决定使用哪种大型语言模型,请放松心情,用这个 AI 启发的 80 年代顶级曲目列表来炒热气氛。https://open.spotify.com/playlist/7b8yw4Zw94zpdY4hbIORtQ?si=b2228b493afc4a5b
请在评论中告诉我们您正在使用的型号。
关于作者
Ezequiel Lanza是英特尔开放生态系统团队的开源传播者,他热衷于帮助人们发现令人兴奋的人工智能世界。他还经常参加人工智能会议,并创建了使用案例、教程和指南,帮助开发人员采用诸如TensorFlow和Hugging Face*等开源人工智能工具。在X上找到他的用户名为@eze_lanza。
有关英特尔的更多开源内容,请访问open.intel