MemGPT: 从多个PDF中整合信息
使用MemGPT进行基于RAG的活动 - 第二部分。
第一部分是很久以前的事,那时候MemGPT还不支持PDF文件。然而,现在它们已经支持了。
所以这就是我们要测试它的方法。
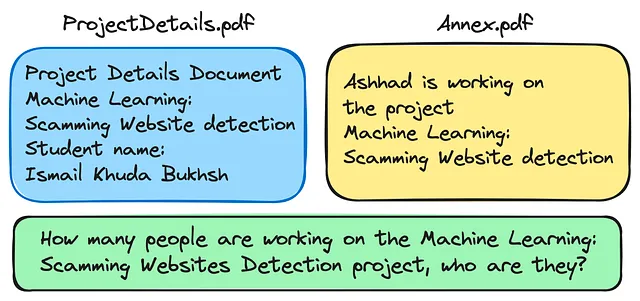
让我们来看看当我们上传这两个文件并问同一个问题时,GPT4的表现如何:
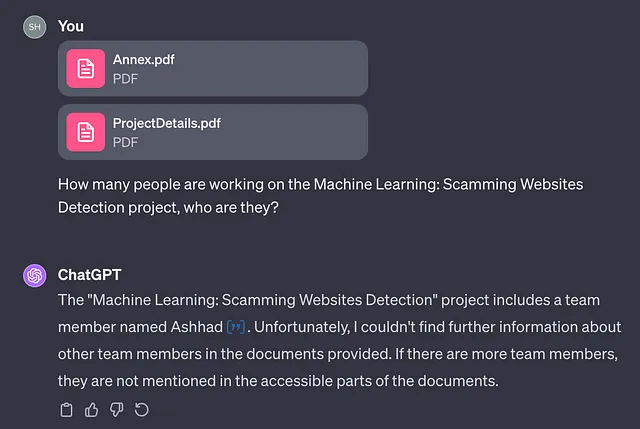
现在让我们看一下MemGPT的表现如何:
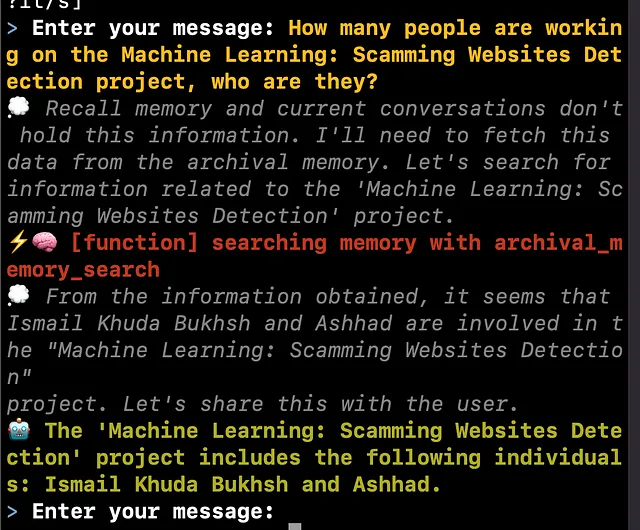
MemGPT在这方面继续表现出色,虽然所提供的示例乍一看似乎琐碎,但却暗示了其能力的更广泛影响。想象一种情况,你拥有分散在多个PDF文件中的组织结构图表,你的目标是找出某个部门的成员。GPT-4能否有效地整合来自不同文件的这些不同信息并提供准确的报告呢?也许可以,也许不行。
保持HTML结构,将以下英文文本翻译成简体中文: 凭借对MemGPT在基于RAG的任务上进行利用的热情,让我们深入了解设置。值得一提的是,为了公正比较,我选择了GPT-4和OpenAI库作为这个实验的后端。然而,值得注意的是,MemGPT也支持本地模型和开源嵌入,这是我们将在未来的一篇文章中探讨的话题。
系统:Macbook Pro 16 GB内存
MemGPT设置:
以下是安装MemGPT的更新步骤。然而,您可以在这里找到它们。
git clone git@github.com:cpacker/MemGPT.git
pip install -e .
这允许我们在命令行中运行MemGPT。
MemGPT配置:
保持您的openAI API密钥便于此步骤。我之前使用的是旧的API密钥,但出现了故障。因此,最好为此实验生成一个新的API密钥。此外,如果您之前使用过MemGPT,可以通过删除主目录中的.memgpt文件夹来清除它。
rm -rf ~/.memgpt
这将清除所有先前的代理和数据源。请谨慎删除。
确保您将openAI API密钥添加到环境变量中,如下所示。
export OPENAI_API_KEY=<your-openai-api-key>
接下来,我们将设置聊天机器人的参数。
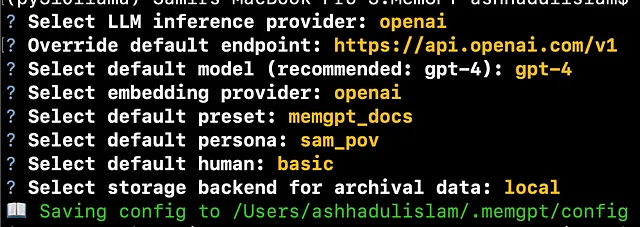
memgpt configure
运行上述命令允许您选择有关聊天机器人的选项。您可以选择默认选项。但请确保选择 default_preset 中的 memgpt_docs。
加载数据
现在我们需要加载数据文件。如果您想使用与我相同的PDF文件进行实验,您可以使用这个和这个。或者您可以使用任何可用的PDF文件(其中包含一些重叠/不重叠信息)。
对我来说,数据文件与项目文件夹(从GitHub下载的文件)相关,具体如下。
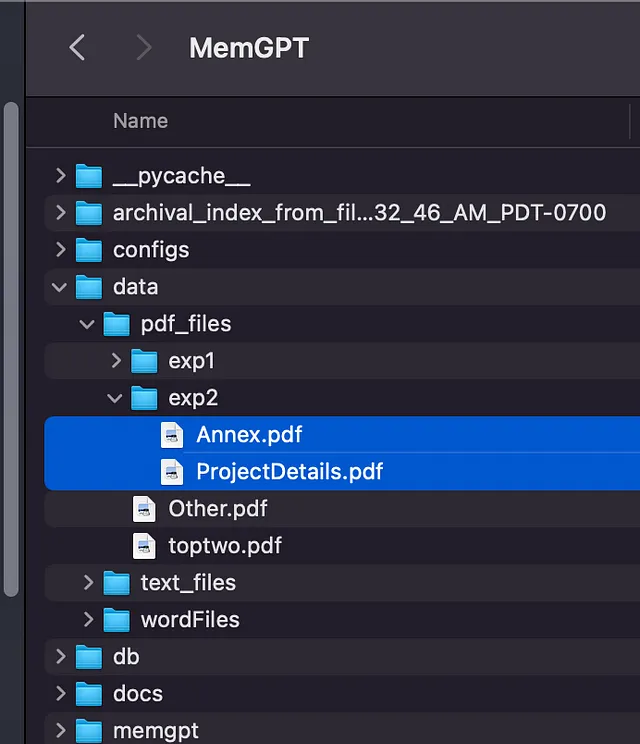
以下命令用于添加文件。
memgpt load directory --name memgpt_data_store --input-files=data/pdf_files/exp2/Annex.pdf
memgpt load directory --name memgpt_data_store --input-files=data/pdf_files/exp2/ProjectDetails.pdf
请注意,所有的文件都将被添加到memgpt_data_store的别名下。这一点很重要,因为我们在与机器人聊天时将使用相同的别名来加载数据的嵌入。
测试聊天机器人
现在我们准备好测试机器人了。
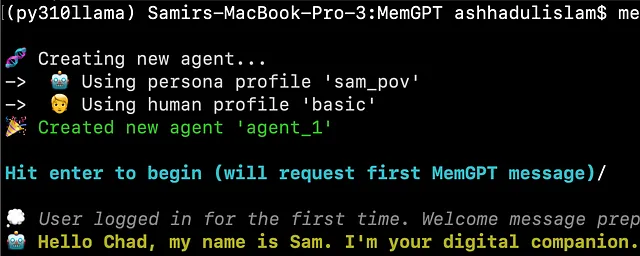
memgpt run
上述命令创建一个新的代理并运行交互式聊天界面。
我们现在要求机器人使用“attach”命令访问文件嵌入。在你需要编写聊天消息的终端中,你需要输入/attach。
/attach
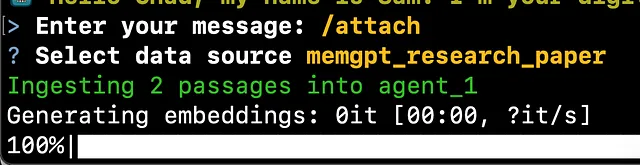
一旦你选择了数据存储并按下回车键,它将加载嵌入并再次给你提供提示来提问。现在你可以用与我们在ChatGPT中询问GPT4的相同问题来测试机器人。
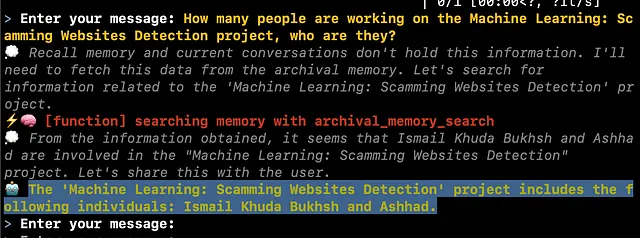
How many people are working on the Machine Learning: Scamming Websites Detection project, who are they?
答案如下:
‘机器学习:识别欺诈网站’项目包括以下个人:伊斯梅尔·胡达·布卡什和阿什哈德。
这是在终端中的样子。
所以,那就是,非常有用的,我相信。还剩下两个事情:
- 增加实验的规模,并观察其信息保留能力如何。
- 尝试本地/开源的LLMs和嵌入。
希望这篇文章对你有所帮助。我正在考虑在通讯形式的新闻简报中推出多个LLMs的教程和案例研究,以提供更加常规的内容。如果你对这样的内容感兴趣,请告诉我。
那就是现在的全部。要冷静不要吹嘘。
以下是我其他基于LLM的文章的链接:
开源LLM
**MemGPT上的文本文件**(请密切关注)
检索增强生成的范式转变:MemGPT [并非真正的开源,因为文章提到了OpenAI的使用] — 这是旧版的MemGPT,仅限于纯文本。
多模态图像聊天
超快速的视觉交流:释放 LLaVA 1.5
与PDF相关
使用LlamaPacks进行高级检索:用更少的代码提升RAG!
超级快速:使用Ollama进行检索增强生成
超快速:使用CPU在公司信息上检索增强生成(RAG)与Llama 2.0
评估基于CPU的低延迟多语言模型在在线使用中的适用性【比较针对RAG活动的三种不同低延迟多语言模型的响应时间】
数据库相关
超快速:在CPU机器上使用LLAMA2从模式生成SQL查询
关闭的源LLM(OpenAI):
PDF相关
聊天机器人文档检索:提问非常规问题
数据库相关
超快速:将ChatGPT连接到PostgreSQL数据库
基本信息:
OpenAI 开发者日:6项公告以及我们 RAGgers 需要担心的原因
超快速:GPT4和开源之间的RAG比较

PlainEnglish.io 🚀
感謝您成為In Plain English社群的一部分!在您離開之前:
- 请务必鼓掌并关注作者️
- 学习如何以简明易懂的语言撰写稿件,也可以为In Plain English️撰写。
- 关注我们:X | 领英 | YouTube | Discord | 通讯简讯
- 访问我们的其他平台:Stackademic | CoFeed | Venture