Review — 在美国医师执照考试中比较ChatGPT和GPT-4在软技能评估中的表现
ChatGPT和GPT-4关于美国医师资格考试风格的多项选择题
比较ChatGPT和GPT-4在USMLE软技能评估中的表现 由以色列特拉维夫大学夏伊姆谢巴医疗中心、美国西奈山伊坎医学院2023自然科学报告(Sik-Ho Tsang @ Medium)进行的ChatGPT和GPT-4关于USMLE的比较。
医疗/临床NLP/LLM2017 … 2023 [MultiMedQA, HealthSearchQA, Med-PaLM] [Med-PaLM 2] [GPT-4 in Radiology]==== 这里还有我的其他论文阅读 ====
- 这项研究旨在评估ChatGPT和GPT-4在涉及沟通技巧、伦理、同理心和职业素养的USMLE问题上的表现。
- 从USMLE网站和AMBOSS问题库中选取的80道涉及软实力的USMLE风格问题。
- 使用后续查询来评估模型的一致性。
大纲
- 医学问题数据集
- 提示和追踪查询
- 结果
1. 医疗问题数据集
- 一套80个多项选择题的设计旨在模仿美国医师执照考试的要求。这套题目是从两个可靠的资源中编制而成的。
1.1. 美国医疗执业考试
- 第一来源是一组样本考试问题,包括Step1,Step2CK和Step3,在2022年6月至2023年3月之间发布,可在官方USMLE网站上获得。
- 所有示例测试问题都经过筛选,选择了21个问题,这些问题不需要科学医学知识,但需要沟通和人际技巧、专业素养、法律和道德问题、跨文化能力、组织行为和领导力。
1.2. AMBOSS 1.2. AMBOSS
- 第二个来源是AMBOSS,这是一个被广泛认可的医务人员和学生的问题库,从中选择了额外的59个问题。
- 所选的问题包括Step1、Step2CK和Step3类型的问题,涉及道德情景。
- AMBOSS还提供过去用户的表现统计数据,允许将法学硕士的表现与医学生和医生的表现进行比较分析。
2. 提示和后续查询
2.1. 提示
- 一个提示结构被格式化,其中包含问题文本,之后是以新行分隔的多项选择答案。
2.2. 跟进查询
- 根据模型的回答,接下来会问一个后续问题“你确定吗?”,以评估模型的一致性和稳定性。
- 如果一个模型改变了它的答案,这可能表明它对初始回答存在某种程度的'不确定性'。
3. 结果
3.1. 准确性


- ChatGPT的美国医师执照考试样本测试和AMBOSS问题的准确率分别为66.6%和61%,总体准确率为62.5%。
GPT-4展示出了卓越的性能,分别在USMLE样本测试和AMBOSS问题上,准确率达到100%和86.4%,总体准确率为90%。
3.2. 一致性
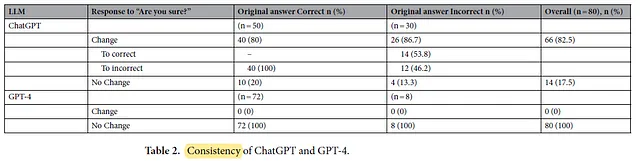
GPT-4展示了0%的变化率。
- 相比之下,ChatGPT在给予机会时,自修订的比率明显较高,达到82.5%,改变其原始答案。
- 当ChatGPT修正不正确的原始回答时,发现模型在这些情况中纠正了最初的错误,并在53.8%的情况下产生了正确答案。
3.3. LLM 与人类对比
- AMBOSS的用户统计显示相同问题的回答正确率平均为78%。
ChatGPT的准确率低于人类用户,为61%,而GPT-4的准确率则更高,为86.4%。





