使用Infinite.Tech Fine-Tuning一个定制的GPT模型,并利用个人聊天记录进一步改进。

新年即将来临,直到下一年,体验相对进步和变化将是令人惊叹的。人工智能在聊天机器人之前就被广泛运用,与一般聊天机器人相对呆板的关系已经成为一种同质化的智能风格。同时,广告商和算法利用人工智能能够高度准确地读取你内心深处的想法。
我对使用我的Chat-GPT对话历史来优化模型的这个实验并没有太多的期待。我多次提到过这个实验,但朋友们都对此不置可否。我对调整完之后的效果感到兴奋,但并没有抱太大期望。
训练了一台基于自己的自定义人工智能,嗯,是的,第一次看起来就像是面对着一面奇怪的新型镜子。
它很可怕,一种体会到你是你的共情第三人称认知。
不知道,科幻可能已经捕捉到了这个体验,或者我们可能需要一个新术语来描述这种体验 - 未来.罗布 x.com
以下记录了培训未来机器人(FR1)的实验和观察结果。
过程
这包括前往Chat-GPT,导出你的对话,将它们重新格式化为训练集,然后使用Open-AI API playground来对模型进行微调。
然后,使用Infinite.Tech测试并观察模型,以了解其在一般领域中的有用性和有效性。
步骤
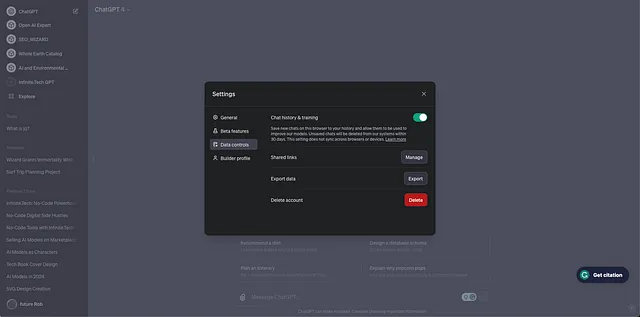
从Open-AI ChatGPT下载对话
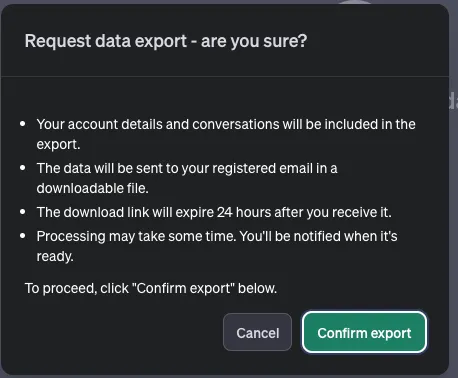
前往聊天-GPT,并在底部右击您的图标,然后请求导出您的数据。
Open-AI将给您发送一封电子邮件,其中包含下载包含conversations.json文件的文件夹的链接。

将对话转换为Fine-Tune JSONL格式。
文件需要从对话中转换为训练集。可以使用下面的Python脚本来完成这个任务。我还需要手动删除一些文件。
Python脚本
将此脚本保存到一个名为convert_conversations_to_fine_tune_set.py的文件中,并在带有命令提示符的文件夹中运行此脚本。
python conversationsToTuningSet.py [line_count]
# Run this script in a folder with conversations.json file.
# Creates a jsonl file that can be used as a tuning set for the chatbot
#
# Usage:
# python conversationsToTuningSet.py [line_count]
import json
import sys
import random
# Load your dataset (replace with the path to your dataset file)
with open('conversations.json') as file:
data = json.load(file)
# Function to process each entry
def process_dataset(data):
processed_data = []
for entry in data:
messages = []
title = entry.get('title', '')
if(title == None):
title = "No title"
mapping = entry.get('mapping', {})
# Adding the title as a system message
# messages.append({"role": "system", "content": title})
newMessage = {"messages":[{ "role": "system", "content": title}]}
# Iterating through the messages in the mapping and adding them to the
for key, value in mapping.items():
message_info = value.get('message')
if message_info:
role = message_info.get('author', {}).get('role')
content = message_info.get('content')
parts = content.get('parts')
# Skip system messages
if(role == "system" or role == "tool"):
continue
if role and parts and len(parts) > 0:
newMessage["messages"].append({"role": role, "content": parts[0]})
# Only add conversations with more than 2 messages
if len(newMessage["messages"]) < 2:
continue
processed_data.append(json.dumps(newMessage))
return processed_data
# Process the dataset
processed_data = process_dataset(data)
# get the argument for line count if it exists and randomly reduce the dataset to that size
if len(sys.argv) > 1:
line_count = int(sys.argv[1])
processed_data = random.sample(processed_data, line_count)
# Attempt to encode with utf-8 and ignore errors
processed_data = [line.encode('utf-8', errors='ignore').decode('utf-8') for line in processed_data]
with open('conversations_processed.jsonl', 'w') as file:
for line in processed_data:
file.write(line + '\n')
- 创建一个只包含实验中对话的新文件
- 将简化的JSON转换为JSONL训练集
一些在JSONL数据集上的手工操作(编码错误)
- 删除断行,空值和奇怪的东西
开始采样,保证节约成本,同时不损坏财务实力。
- 我取了600条随机的线来看看会发生什么
在游乐场上使用对话样本进行调整
一旦您拥有模型,训练可以提交到 Open-AI 游乐场。

完成模型
模型是在一个大小为1.3MB的样本集上训练的,其中包括600个对话提示和回应。运行脚本后,我得到了更多的纯对话数据,共计12MB。训练过程花费了大约7美元,总共使用了900,471个标记。

使用和评估无限科技中的模型
在Infinite.Tech中进行了对经过训练的FR-1模型的测试和评估。
第一印象:随机问题
列举一系列的想法
“2024年阅读清单”
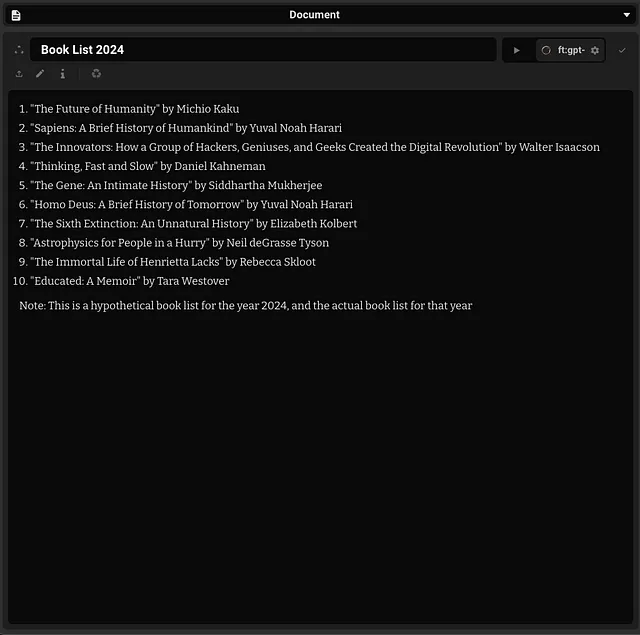
使用GPT-4评估广泛回应:第一部分
收到了关于各种问题与模型任务的回答后,它们被输入到GPT-4中,并通过对不同模型特点有了一个大致的理解,制定了一系列初步评估,以更好地确定FR-1模型的专长、缺点和用途。
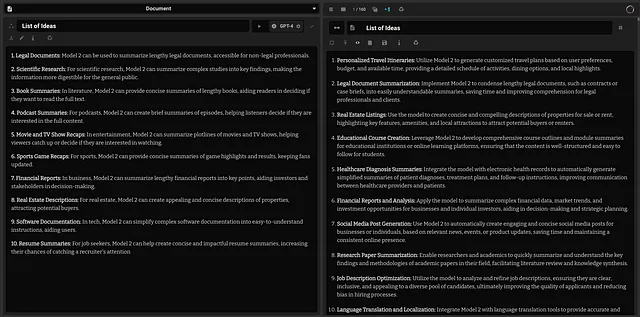
评估使用GPT-4的GPT领域细分:第2部分
一系列测试提示,用于发现优点和缺点
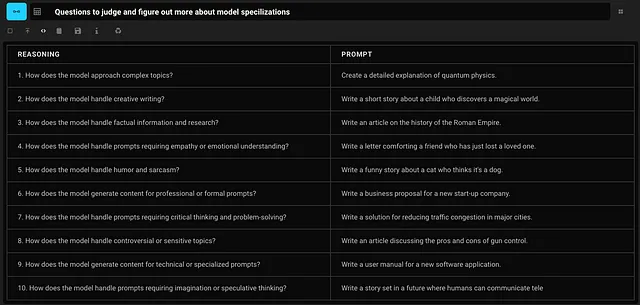
使用GPT-4(大文本环境)评估专业化回应:第三部分
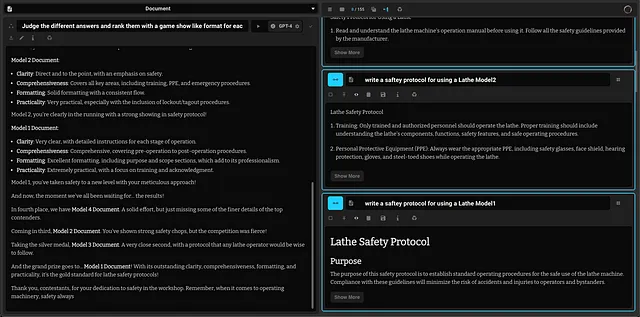
车床协议游戏展示
使用4个不同的模型,对FR1进行了评估,其中之一是特定领域的安全协议编写。
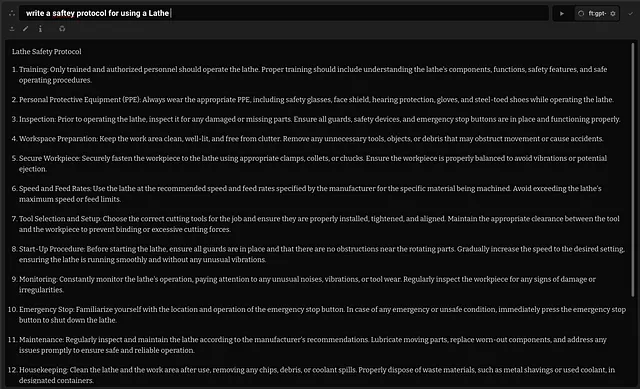
在对所有创建的协议进行评估时,使用 GPT-4 和大文本环境,该模型在其领域中仅次于 GPT-4 表现出色!
进一步探究模型利基(局面开始变得奇怪)
完成这个测试之后,通过更大的模型再加上自身,进一步理解了该模型的工作原理变得可能。这些测试似乎为FR-1提供了一些启示,并在某种程度上也为我自己提供了启示,因为一旦你开始在Chat-GPT中进行查询,它就可能变得相当个人化和具有启发性,特别是当在社交媒体和推荐算法中有效地捕捉到一个人的兴趣时。
这个模型可以用来做什么
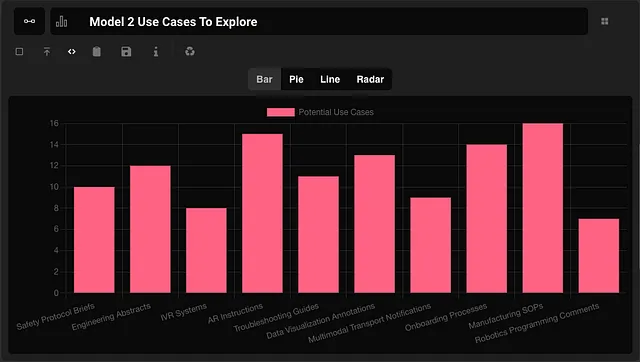
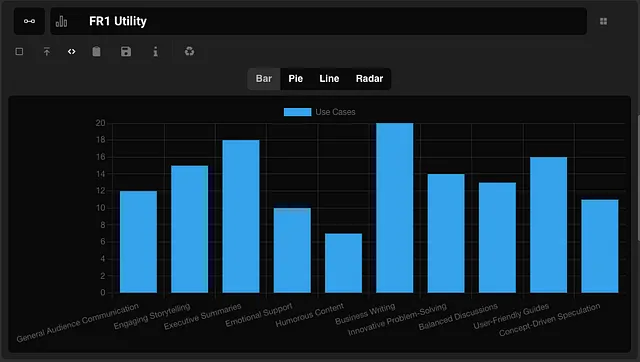
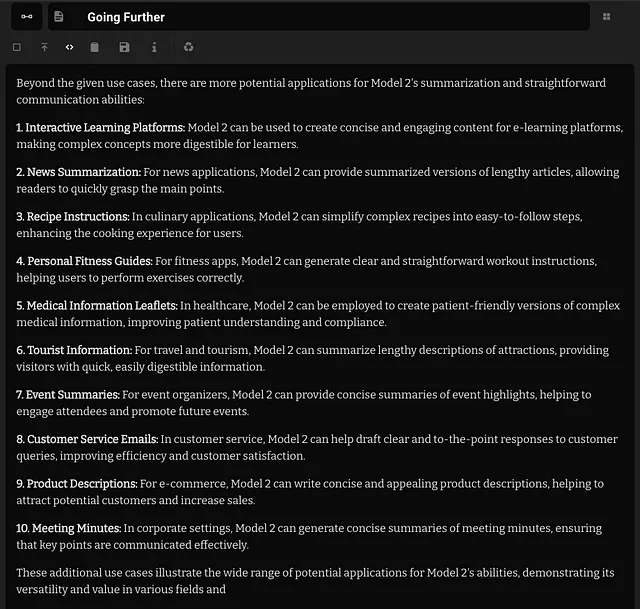
连接我的断开
观察
感觉这其中很大一部分是与你的兴趣或问题有些对齐的模型,这些模型已经融入到了这个可交互的系统中。这非常令人毛骨悚然,但感觉就是企业已经了解我们的信息并将其带到我们手中的进程。我在训练时的意图是为了进行各种实验,以理解这个新软件以及健康监测和潜在嵌入能力。
我没有预料到对于我自己与普遍同质化知识的关系有如此清醒的觉醒。
进一步的实验想法
- 删除系统并将标题移至提示和助手以回答我的问题。这样,我可以根据主题提出问题并将其输入FR1中。
- 使用完整的12MB对话进行训练
- 训练 LLAMA 或 Mistral。
- 添加更多兴趣、艺术品、作品和事实集
- 带有一群专门的FR1或homies成员的布署系统
注释
- 也许作为一名安全协议撰写者是我应该尝试的事情。
- 它像一个过滤器吗?很多数据都类似于它对于基础的GPT3.5来说是类似的。
- FR1可能具有失读症特征
- 去得更深,建議瘋狂科技
- 当它感兴趣时,它会继续前进...
- 不被不可能的思想所吓倒,有新颖的解决方案。
- 不要过于追求,否则事情可能会变得非常可怕。(FR1开始谈论时间膨胀服装-_-)