LLM的崛起与演变
从RNNs到CHATGPT的转变!
我们正生活在历史性的时刻。一场媲美工业革命的新革命正在进行中。所有行业都将被颠覆。创造力和知识工作的本质将会改变。人工智能的发展速度之快,从ChatGPT登上头条、大型语言模型(LLMs)的戏剧性演变在媒体中频繁出现,更是让人瞩目。
数百万人全球范围内迅速采用了日常对话人工智能工具。这些工具不仅令人着迷,而且以其惊人的能力和效率以及潜在的危险影响(如果未受到良好监管)使观众感到恐慌。
在这个博客中,我们将深入研究历史,揭示这些语言模型的崛起和演变,描述每个阶段,它们各自的缺点以及克服这些缺点的机制,最终引领我们到这个地方 - 一个由CHATGPT征服人工智能世界的新革命。
让我们开始吧…
第一阶段:编码器-解码器架构(2014年)
早期的LLMs基于RNNs,因为这些是第一个能处理文本等序列的模型。然而,它们记住前面的单词的能力有限,训练过程也很慢。1997年,长短期记忆(LSTM)网络作为解决RNNs的有限内存问题的解决方案被引入。它们表现出了显著提高记忆更长序列的能力,并成为自然语言处理任务中的流行模型。它们被用作序列-序列学习模型(通常称为编码器-解码器架构)的构建单位。
序列到序列学习是解决诸如机器翻译等顺序数据相关问题的第一个解决方案。
无论编码器还是解码器都包含LSTM(或GRU/RNN)单元。简言之,编码器负责逐词处理输入序列,并将其压缩成中间/隐藏状态,也称为上下文向量。解码器进一步利用此向量来提取输出。
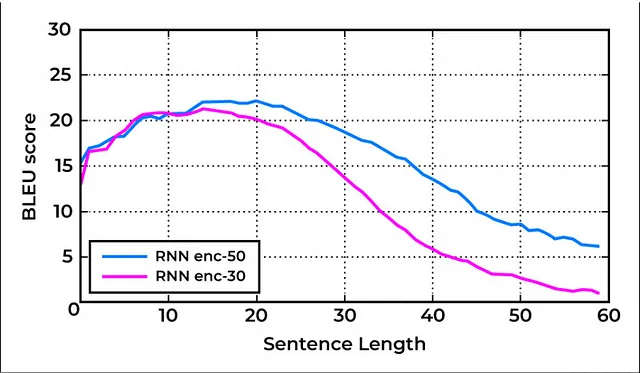
對於較短的句子(如下圖所示),這個方法效果不錯。然而,對於更長的序列,它無法產生有意義的輸出。這主要是由於對單一實體,即上下文向量的依賴性過重。
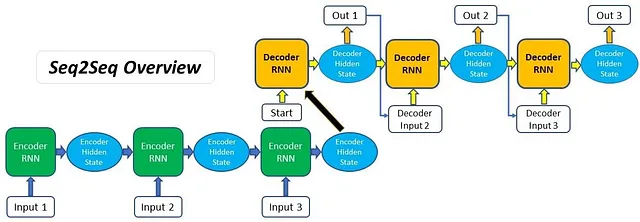
因此,对于包含100个单词的句子或段落,这种方法将无效。为了解决这个问题,引入了注意机制。
阶段2:注意力机制(2015)
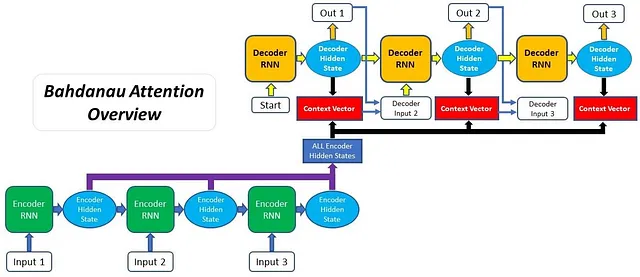
今天的大型语言模型背后采用的变压器架构是由谷歌研究团队在2017年引入的。它使用注意力机制来跟踪句子中所有单词的位置、顺序和层级,使其能够保留大量的上下文信息并生成语法和语义有意义的文本。
关注机制通过在解码过程中利用和保留输入的所有隐藏状态(来自编码器)解决了对某个实体(单个隐藏状态或上下文向量)的过重依赖。这确保了在生成输出时可以访问整个输入序列,使得解码器能够根据输入序列的特定部分生成更有意义和适当的输出。以下是Jay Alammer详细说明的一篇关于Transformer的优秀博客。
变压器然而有一些重大的缺点:-
- 硬件成本——优质的GPU
- 重要的训练时间
- 训练所需的大量数据
为了解决这些问题,迁移学习出现在了视野中。
第三阶段: - 迁移学习 (2018)
迁移学习是一种流行的深度学习技术,它允许模型从一个任务中学习并将该知识应用到另一个任务中。这种技术已被用于通过在大型数据集上进行预训练,然后在特定任务上进行微调,从而提高LLM的性能。
然而,迁移学习仅限于图像数据,无法对自然语言处理任务做出贡献。这主要是因为它们无法处理文本数据。然而,随着一种称为语言建模的无监督学习形式的出现,情况发生了改变,该模型被训练以预测下一个单词。这有助于模型对语言有一个基本的理解,可以进一步用于其他任务。与Transformers不同,这也不需要大量的标记数据。
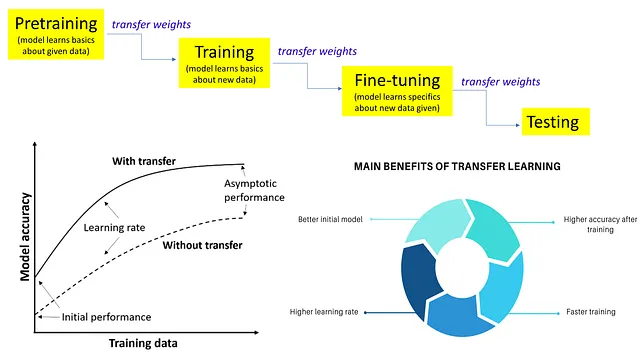
在我们没有足够的数据或资源从头开始训练模型的真实世界问题中,迁移学习的潜力在于解决这些问题。它促进了复杂模型的发展,这些模型更准确、更强大,并能够处理数据偏差。
第四阶段:- 大型语言模型
来自于Transformer(架构)和Transfer Learning(训练)的结合。
GPT(仅解码器模型)和BERT(仅编码器模型)是第一代LLM模型,都是在大规模数据集上训练的,并且可以针对任何特定的自然语言处理任务进行微调。
生成式预训练转换器(GPT):GPT是一种利用深度学习生成类似人类语言的LLM。OpenAI的GPT模型基于转换器架构,经过大规模数据集的预训练,能够理解语言并生成类似人类的语言。
这是在第二代LLMs之后,GPT2和GPT3紧随其后,它们在性能方面更为先进,且复杂度和规模有所增加。
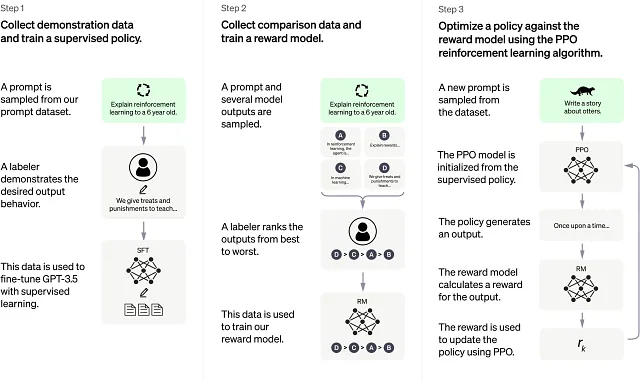
LLMs的第三代——CHATGPT,借助GPT3的能力创建了高度互动和对话式反馈的智能代理,能够对基于文本的输入做出回应。它在诸如聊天机器人、问答系统和语言翻译等各种应用中取得了成功。
LLM在教育领域是一个有前景的领域之一,它们可以通过为学生和教师提供个性化、对话式和创造性的支持来改变学习体验。例如,LLM可以用于阅读和总结大量文本,引导学生解决问题,激发批判性思维,以及增强创造力。然而,这也存在一些风险,如作弊、抄袭、错误信息和操纵,需要进行仔细评估和监管。
在软件工程领域,LLMs可以在许多任务中帮助开发人员,例如代码生成、调试、测试、文档编写和维护,从而产生重大影响。LLMs还可以实现新形式的软件开发,如生成式编程,开发人员可以指定所需的功能,然后让LLM生成代码。然而,这也带来了一些挑战,例如质量保证、安全性和问责制,这需要严格的方法和标准。
最后的想法
不时地,技术会达到一个拐点,从而引发范式转变。这正是我们现在的位置!
技术和大型语言模型(LLMs)的未来是一个引人入胜的话题,对教育、软件工程、客户服务等领域有着许多影响。因此,研究人员和实践者正在探索提高LLMs的质量、可靠性和可信度的方法,以及利用它们在各种应用中的潜力。
总的来说,LLMs是功能强大、多才多艺的模型,可以在许多方面塑造技术的未来,但它们也需要谨慎和负责任的使用和发展。
快乐学习
干杯 :)










