现在7B模型能否掌握AI代理?看看快手最新的LLM开源发布情况。
快手最近开源了快手代理系统,这是一个令人印象深刻的系统,当被问及如何计划周末的滑雪之旅时,不仅会找到一个场地,还会考虑当天的天气情况 — 简直是非常周全!
- 技术报告:https://arxiv.org/abs/2312.04889
- 项目主页:https://github.com/KwaiKEG/KwaiAgents
这是常识,大型语言模型(LLMs)通过语言建模获取大量的知识,并具备一定的认知和推理能力。然而,即使拥有最新最先进的模型如GPT-4,单独使用它可能导致一些真实世界交互上的怪异现象。人工智能代理是解决这个问题的一条途径,利用大型模型的能力进行任务规划、反思和工具利用,从而通过使用真实世界工具提高生成内容的准确性,甚至解决复杂问题。这次,Kwai与哈尔滨工业大学合作开发了KwaiAgents,提升了“更小”的大型模型如7B/13B的能力,超越了GPT-3.5的性能。而且他们将所有内容都开源了:系统、模型、数据和基准!
从KwaiAgents GitHub页面,开源内容包括:
- 系统(KAgentSys-Lite):一个配备有基于事实和时间敏感的工具集的轻型人工智能代理系统。
- 模型(KAgentLMs):一系列经过元代理调整(MAT)的具有广义代理能力的大型模型,以及它们的训练数据(部分人工编辑)。
- 评估(KAgentBench):一种适用于自动评估智能代理能力和人工评估结果的即插即用基准。
系统
KAgentSys是基于一个大型模型认知核心的自动化系统,配备有记忆机制和工具库。它包括:
- 记忆机制:依靠混合向量和关键词搜索的检索框架,系统在每个规划阶段中找到所需的信息,并保留有关知识、对话和任务历史的记忆。
- 工具库:包括一个增强现实工具集,具有从网页、维基百科和视频百科全书收集知识的异构搜索和浏览机制;以及一个带有日历、假期、时差和天气信息的时间感知工具集。
- Agent Loop:在一轮对话中,用户提出问题,作为外部知识和额外的人设设定进行分类。它更新和检索内存,调用大模型进行任务规划,如有必要,使用工具,或者进入结论阶段,在这个阶段,模型综合历史信息以提供预期的回答。
模型
为了避免在训练过程中对单一模板过度拟合的问题,团队提出了一种元代理调试(MAT)方法,通过向训练数据中引入多种代理提示模板来增强大型模型在代理能力方面的广泛性和有效性。
MAT由两个阶段组成:
(1)模板生成阶段:设计元代理以生成特定问题集的实例化代理提示模板,并使用LLL顺序分数与开源模板的结果进行比较,选择高质量的模板。
(2) 指令微调阶段:基于数万个模板,已经构建了超过20万条代理指令微调数据,并经过人工部分编辑。团队已经微调了像Qwen-7B和Baichuan2-13B这样受欢迎的开源模型以供公众使用,并将继续发布其他模型。
评估
KAgentBench允许我们通过一个命令行评估大型模型在不同模板中的智能代理能力,感谢成千上万个手工标注的数据点。
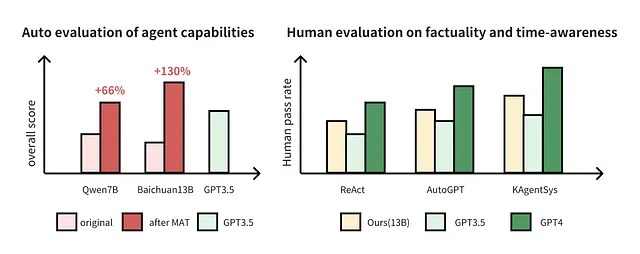
下表显示了7B-13B型号在MAT调整后各项能力的改进情况,超越了GPT-3.5的性能。
此外,人类标注员在不同的大型模型和代理系统上评估了200个事实和时间敏感问题(例如:“今年Andy Lau多少岁?”),结果显示在KAgentSys系统和模型中,在MAT之后有显著的改进(数字前的百分比表示准确率,括号中的数字表示在5分制度上的平均得分)。
传统搜索引擎在处理长尾问题或热门问题时存在局限性。例如,如下图所示,当查询安东内拉和梅西的年龄差异时,会出现两个问题:(1)关于“梅西和妻子”的热度导致搜索结果偏向与用户无关的新闻文章,如两人的关系时间线;(2)该问题与他们各自的出生日期有关(一个不太常见的细节),属于“长尾”搜索查询。单一的大型语言模型(LLM)在处理这个问题时会遇到困难,因为它们可能记得梅西的出生日期,但会忘记安东内拉的。将LLM与搜索引擎结合也不足够,因为浮出的信息虽然相关,但无法准确回答问题。KwaiAgents通过整合实体链接和从维基百科等资源中提取相关细节来克服这些障碍。具体来说,该系统首先获取梅西和他妻子的出生日期,然后利用时间差工具准确计算出时间差异,从而正确回答提出的问题。
人工智能代理领域呈现出重要的潜在发展路径,我们希望像快手代理这样的项目能够持续为整个社区注入新鲜活力。