从穿孔卡片到ChatGPT
我的祖父瞥见生成人工智能
我外公史凯普在我眼中一直是个农民。可悲的是,在我1988年出生后的一个月,我母亲因白血病去世了。作为家族的第一个孙子,我和史凯普关系非常亲近。小时候,我整天都骑在拖拉机和联合收割机的扶手上,参与每年的小麦收割工作。当我成为十几岁的青少年时,我自己也在农场工作,作为一个暑期工作。
然而,Skip之前的生活与我所知道的农业世界大相径庭。在我出现之前,他深入学术界,在1972年完成了在德克萨斯农工大学站的统计学博士课程。不久之后,他拥抱了马里兰大学的教授职位,并在1974年完成了他的论文。他的开创性研究旨在预测和确定工业环境中的安全和材料风险。这项伟大的任务需要多年的努力。他不得不手动收集来自各个公司的十年事故报告,手动处理统计数据,然后将这些洞见转化为大学计算机系统的穿孔卡指令。获得计算机时间并不是立即可行的,需要提前数周甚至数月预订。一个单一的编码错误可能意味着从头开始,可能会使他的研究停滞数个月。
他在1980年代离开那种生活,回到了东德克萨斯州的家庭农场,并开始从事创业。但作为一个农夫,他在一切所做的事情中都希望利用统计推断,只是我当时还不明白。在我孩童的眼中,Skip在做他所称的“办公工作”,但实际上他利用信息技术进行预测和融资,以满足运营费用,优化化肥中的化学成分以提高农作物产量,制定策略通过芝加哥商品交易所的期货交易来减少现金流的不确定性,而这一切都是在他在Radio Shack购买的带有16 KB内存的TRS 80计算机上连接点阵打印机完成的。农业可能是一个利润非常低的行业,而Skip的赌注是他可以利用统计学来稍微扭转局面。
多年来,农场没有经受住时间的考验。原来,代际农业在被迫跳过一代时并不太好 —— 如今的投入成本比以往任何时候都更加无情 —— 规模经济成为唯一盈利的竞争方式 —— 所以,大多数来自Skip一代的小中型农场主被收购并合并 —— 但这是逐渐发生的 —— 一点一点地(至少对我们来说是这样)。
当然,我逐渐开始欣赏统计学与农业之间的紧密联系。我仍然记得美国农业部每年仔细地对农作物产量进行抽样调查(包括我们的农场),作为他们国家农业统计服务的一部分。在我看来,这是历史上一项伟大而未被赞扬的持续数据项目,帮助一代又一代的农民做出"数据驱动"的决策 - 尽早在这成为热门话题之前。但是,数十年后,当我开始我的分析和数据科学事业时,我对Skip所做的一切感到更加欣赏 - 这是我在30多岁时作为美国陆军官员度过20多岁的第二幕。我经常通过电话与他重新联系,询问他过去是如何进行回归分析、模拟或如何控制随机抽样"过去那个时代"。偶尔,我会告诉他现在他们是如何做的,以了解他对我描述的机器学习、深度学习、强化学习等概念的兴奋程度 - 对他来说,这有点像科幻小说,但他很喜欢听 - 尽管现在对他来说这还不完全是现实。

进入实验。
我在周末决定采用实际行动而非言辞来表达。我希望Skip亲自体验这项新技术,而不仅仅是听我谈论它。如果我们能在不到40分钟内制定一个虚构的新农场的业务计划,该有多好呢?我可以使用启用了高级数据分析功能的ChatGPT 4,在屏幕共享到他的iPhone上完成,并且我们将共同合作来建设它。
我们简要讨论了我们的假设:
- 我们在东得克萨斯州有1,000英亩的农田。
- 我们有100万美元的初始资金用于购买设备。
- 我们需要从银行获得第一年运营费用的信用额度,以便开始运营。
- 我们对种植小麦和大豆(当时 Skip 实际耕种的作物)很感兴趣。
我们从简单开始:
提示1: "为我写一份关于在东得克萨斯开始一个新农场种植小麦和大豆的商业计划大纲"。
Skip对长篇结果印象深刻。但是等等,我们才刚刚开始...
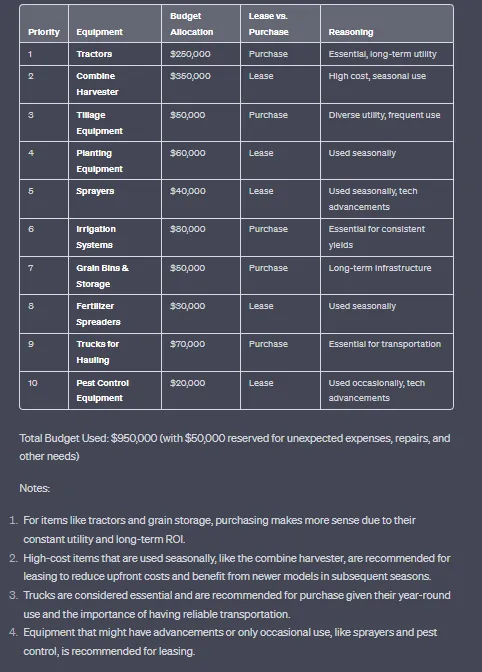
提示2:给我一份我需要开始的设备清单 提示3:将其放入表格中,并按照最迫切需求到最不迫切进行数字优先排序 提示4:现在为预算分配创建一列,假设我将使用租赁和购买的组合,请创建一列来推荐租赁还是购买,并假设我有100万美元的初始资金。
(已过去4分钟的时间)
结果:
提醒5:在变动成本(种子、肥料、劳动力等)方面,我应该留出多少资金向信贷额度(假设为1000英亩)提出申请?请创建一张新表。
结果:
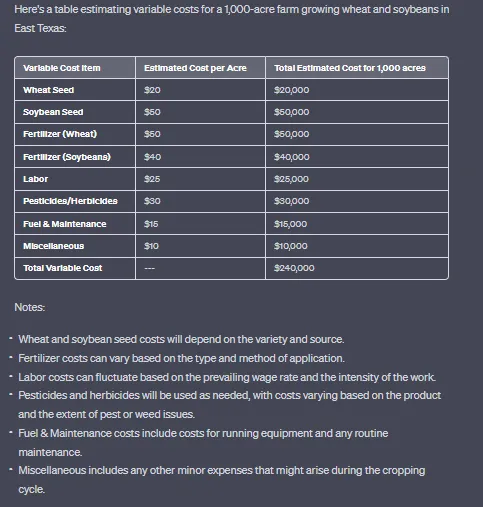
到这一点,我感觉像跳跃刚刚再次目睹了阿波罗11号。他几乎无法控制自己的激动。但我们还没有完成...
提示 6:请为我编写一个蒙特卡洛模拟,我可以调整输入假设,并测试对我的预算的结果。
结果:
import numpy as np
import matplotlib.pyplot as plt
# Define number of simulations
n_simulations = 10000
# Assumptions with [mean, std deviation]
wheat_seed_cost = [20, 2] # Cost per acre
soybean_seed_cost = [50, 5]
fertilizer_wheat_cost = [50, 5]
fertilizer_soybean_cost = [40, 4]
labor_cost = [25, 3]
pesticide_cost = [30, 3]
fuel_maintenance_cost = [15, 2]
miscellaneous_cost = [10, 1]
def simulate_farm_costs():
wheat_seed = np.random.normal(wheat_seed_cost[0], wheat_seed_cost[1])
soybean_seed = np.random.normal(soybean_seed_cost[0], soybean_seed_cost[1])
fertilizer_wheat = np.random.normal(fertilizer_wheat_cost[0], fertilizer_wheat_cost[1])
fertilizer_soybean = np.random.normal(fertilizer_soybean_cost[0], fertilizer_soybean_cost[1])
labor = np.random.normal(labor_cost[0], labor_cost[1])
pesticide = np.random.normal(pesticide_cost[0], pesticide_cost[1])
fuel_maintenance = np.random.normal(fuel_maintenance_cost[0], fuel_maintenance_cost[1])
miscellaneous = np.random.normal(miscellaneous_cost[0], miscellaneous_cost[1])
total_cost = (wheat_seed + soybean_seed + fertilizer_wheat + fertilizer_soybean +
labor + pesticide + fuel_maintenance + miscellaneous) * 1000 # for 1000 acres
return total_cost
results = [simulate_farm_costs() for _ in range(n_simulations)]
# Visualization
plt.hist(results, bins=50, edgecolor='black', alpha=0.7)
plt.title('Distribution of Total Farm Costs')
plt.xlabel('Total Cost')
plt.ylabel('Frequency')
plt.grid(True, alpha=0.2)
plt.show()
现在是真相的时刻 - 代码将会运行吗?我们跳转到Jupyter笔记本以运行代码。然后在第一次尝试中,它成功运行了。
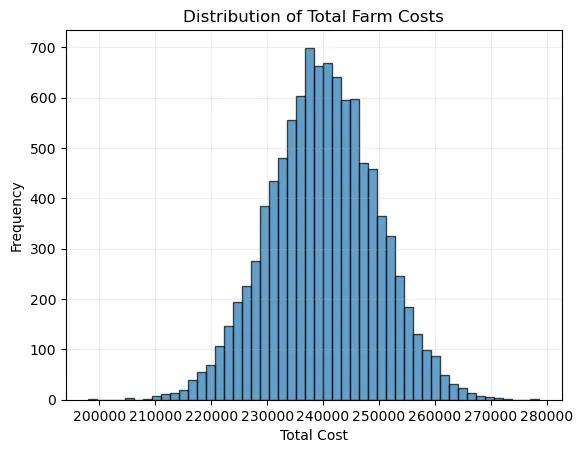
到目前为止,我们只进行了10到15分钟。还有一些时间,我们能让它变得交互吗?
我们需要创建一个参数列表,允许用户通过滑块动态调整假设。再次,我们将依据之前建立的蒙特卡洛方法,请ChatGPT提供这些参数的建议。
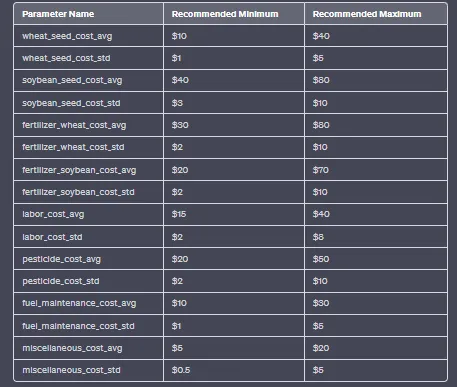
一旦我们建立了参数列表,我们在Power BI中创建一个与16个选择器可视化工具相关联的“度量”表,允许用户手动选择他们的输入并动态更新蒙特卡罗模拟。为此,我们在Power BI中创建一个“Python可视化”工具,将所有的度量指标拖放进去,然后按照以下方式更新代码。
# The following code to create a dataframe and remove duplicated rows is always executed and acts as a preamble for your script:
# dataset = pandas.DataFrame(fertilizer_soybean_cost_avg Value, fertilizer_soybean_cost_std Value, fertilizer_wheat_cost_avg Value, fertilizer_wheat_cost_std Value, fuel_maintenance_cost_avg Value, fuel_maintenance_cost_std Value, labor_cost_avg Value, labor_cost_std Value, miscellaneous_cost_avg Value, miscellaneous_cost_std Value, pesticide_cost_avg Value, pesticide_cost_std Value, soybean_seed_cost_avg Value, wheat_seed_cost_avg Value, wheat_seed_cost_std Value)
# dataset = dataset.drop_duplicates()
# Paste or type your script code here:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Assuming the data from Power BI is passed as 'dataset'
df = dataset
# Fetch values from the dataset
wheat_seed_cost_avg = df['wheat_seed_cost_avg Value'].iloc[0]
wheat_seed_cost_std = df['wheat_seed_cost_std Value'].iloc[0]
soybean_seed_cost_avg = df['soybean_seed_cost_avg Value'].iloc[0]
soybean_seed_cost_std = df['soybean_seed_cost_std Value'].iloc[0]
fertilizer_wheat_cost_avg = df['fertilizer_wheat_cost_avg Value'].iloc[0]
fertilizer_wheat_cost_std = df['fertilizer_wheat_cost_std Value'].iloc[0]
fertilizer_soybean_cost_avg = df['fertilizer_soybean_cost_avg Value'].iloc[0]
fertilizer_soybean_cost_std = df['fertilizer_soybean_cost_std Value'].iloc[0]
labor_cost_avg = df['labor_cost_avg Value'].iloc[0]
labor_cost_std = df['labor_cost_std Value'].iloc[0]
pesticide_cost_avg = df['pesticide_cost_avg Value'].iloc[0]
pesticide_cost_std = df['pesticide_cost_std Value'].iloc[0]
fuel_maintenance_cost_avg = df['fuel_maintenance_cost_avg Value'].iloc[0]
fuel_maintenance_cost_std = df['fuel_maintenance_cost_std Value'].iloc[0]
miscellaneous_cost_avg = df['miscellaneous_cost_avg Value'].iloc[0]
miscellaneous_cost_std = df['miscellaneous_cost_std Value'].iloc[0]
# Define number of simulations
n_simulations = 10000
# Assumptions with [mean, std deviation]
wheat_seed_cost = [wheat_seed_cost_avg, wheat_seed_cost_std]
soybean_seed_cost = [soybean_seed_cost_avg, soybean_seed_cost_std]
fertilizer_wheat_cost = [fertilizer_wheat_cost_avg, fertilizer_wheat_cost_std]
fertilizer_soybean_cost = [fertilizer_soybean_cost_avg, fertilizer_soybean_cost_std]
labor_cost = [labor_cost_avg, labor_cost_std]
pesticide_cost = [pesticide_cost_avg, pesticide_cost_std]
fuel_maintenance_cost = [fuel_maintenance_cost_avg, fuel_maintenance_cost_std]
miscellaneous_cost = [miscellaneous_cost_avg, miscellaneous_cost_std]
def simulate_farm_costs():
wheat_seed = np.random.normal(wheat_seed_cost[0], wheat_seed_cost[1])
soybean_seed = np.random.normal(soybean_seed_cost[0], soybean_seed_cost[1])
fertilizer_wheat = np.random.normal(fertilizer_wheat_cost[0], fertilizer_wheat_cost[1])
fertilizer_soybean = np.random.normal(fertilizer_soybean_cost[0], fertilizer_soybean_cost[1])
labor = np.random.normal(labor_cost[0], labor_cost[1])
pesticide = np.random.normal(pesticide_cost[0], pesticide_cost[1])
fuel_maintenance = np.random.normal(fuel_maintenance_cost[0], fuel_maintenance_cost[1])
miscellaneous = np.random.normal(miscellaneous_cost[0], miscellaneous_cost[1])
total_cost = (wheat_seed + soybean_seed + fertilizer_wheat + fertilizer_soybean +
labor + pesticide + fuel_maintenance + miscellaneous) * 1000 # for 1000 acres
return total_cost
results = [simulate_farm_costs() for _ in range(n_simulations)]
# Convert results into a dataframe
df_simulated_results = pd.DataFrame(results, columns=['Total Cost'])
# Calculate the Interquartile Range (IQR)
Q1 = df_simulated_results['Total Cost'].quantile(0.25)
Q3 = df_simulated_results['Total Cost'].quantile(0.75)
# Plotting the histogram
plt.figure(figsize=(10, 6))
n, bins, patches = plt.hist(df_simulated_results['Total Cost'], bins=50, color='blue', edgecolor='black', alpha=0.7)
plt.title('Distribution of Year 1 Variable Farm Costs from Simulation')
plt.xlabel('Year 1 Variable Cost')
plt.ylabel('Frequency')
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
# Shade the IQR
for i in range(len(bins)):
if bins[i] > Q1 and bins[i] < Q3:
patches[i].set_facecolor('green')
plt.axvline(Q1, color='red', linestyle='dashed', linewidth=1)
plt.axvline(Q3, color='red', linestyle='dashed', linewidth=1)
plt.tight_layout()
plt.savefig('simulated_costs_histogram.png') # This will save the figure as an image file
plt.show()
只是出于好玩,我们提示ChatGPT定义了四分位数间距(IQR)并将其标记为不同的颜色,我们还手动更新了图表标签和X轴。剩下的工作只是在Power BI中稍微清理一下视觉效果,使其更加用户友好。最终结果是:
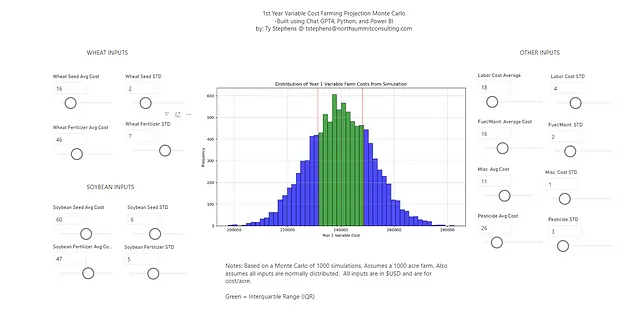
现在我们有一个动态蒙特卡洛模拟,可以根据不同的输入成本假设进行试验,并预测我们开始农业项目所需的可变运营费用。利用ChatGPT 4,我们几乎没有编写代码,只是稍作调整,大部分工作都是通过iPhone屏幕共享完成的,最后在Power BI桌面版上构建了最后一部分,并通过Power BI iPhone应用程序进行了屏幕共享。所有这些工作只用了大约30-40分钟。
我的祖父的结论是什么? "我们在40分钟内完成了他过去独自需要2年才能完成的事情。" 是的,我意识到我们还可以做得更多-而且"模拟"远非完美。(例如,我们没有区分用于大豆和小麦的农作物百分比。) 但是在40分钟内?即使是我也感到印象深刻。这就是通用人工智能的承诺-民主化数据科学,鼓励实验,并加快开发速度,全部掌握在你的手中。让一个祖父和他的孙子有机会通过一些统计数据连接,并以新的意想不到的方式利用技术。