Kubenstein,一款由GPT提供动力的Kubernetes管理员
但它好吗?
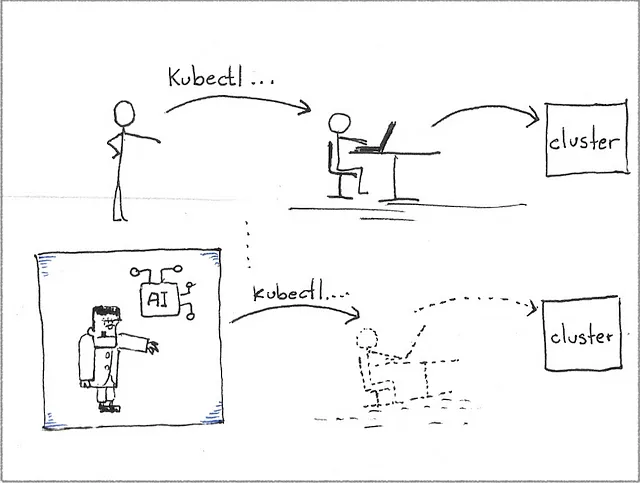
Kubenstein 是一个以“Kubernetes”和“Frankenstein”之间的双关为名的副项目。
我写这篇文章是为了尝试超越GPT助手为Kubernetes管理员提供更直接的用例,例如查询集群资源或解释集群消息中的错误。
你可以在类似k8sgpt项目的命令行接口扩展和Robustas的Slack机器人等界面集成中看到这些场景的示例。
这些都是对现有工具的自然和有价值的补充,但Kubenstein超出了合理和可行的范围。
以下图像显示了Kubenstein应用程序与其AI“大脑”之间的对话摘录。从Kubenstein返回到AI的“行”是根据AI建议的命令对目标群集执行后的输出。
超越语言。智能?
然而,除了语言处理之外,我想探索人工智能遵循认知脚本的可能性。
人类行为主要可以归类为“脚本”,这是因为它们与书面剧本的功能相似,为行动提供了程序。
我想知道是否能告诉Kubenstein我如何执行特定活动,并让它尝试复制。为此,我选择了一种熟悉的Kubernetes管理员的认知脚本:在故障排除会话期间评估集群健康状况。
任何评估集群健康状况的人都有他们偏好的方法。不过,这些评估基本上涉及逐层检查组件并寻找错误。
沿途中,当他们遇到错误时,他们会个别地检查每个错误以寻找线索。这从未是一个固定的方法,因为一个人永远不知道他们即将发现什么。尽管如此,大纲和认知脚本仍然有许多共同点。
于是我开始思考:
一个人工智能(AI)作为故障排除会话的驱动程序,会表现如何?
没错;我并不想要更容易理解或更高效分析错误信息的帮助。我需要的是能够跟随我的思维过程并完成工作的东西。
聊天激励提示
Kubenstein的核心目标是在不依赖人工干预的情况下执行管理动作。对于当前特定的使用情况,我希望它能够按照我为该活动编写的认知脚本运行故障排除会话。
我不想向人工智能投掷错误来获取指导。我不想成为互动过程的中间人。我希望Kubenstein能够自己与集群进行交互。
Translate Text
Kubenstein 在终端上作为一个独立的 Python 应用运行。它假设人类管理员已经使用 kubectl CLI 登录到集群,并且 CLI 在终端的 PATH 环境中可用。
它还需要与一个人工智能(如ChatGPT)建立连接,以便与我认知脚本的任务进行聊天会话。
在故障排除会话期间,Kubenstein会迭代地向AI请求下一个输入命令,执行该命令来针对目标集群,然后将AI输入和命令输出都添加到表示聊天的消息数组中。
这个过程会不断重复,库本斯坦会将越来越多的信息发送给人工智能,以便人工智能能够理解整个对话环境。一旦人工智能回复消息表示已完成认知脚本,这个过程就结束了。
在这个意义上,Kubenstein通过在AI和集群之间进行对话来偏离当前的Kubernetes辅助方法。
Kubenstein 不试图让你在解决问题时变得更快;它努力成为你。
该对话的起点是指导AI像系统管理员那样行动,并告知其评估集群的健康状况的目标,提供整个过程的大纲,并让其按照指示进行操作。
例如,初步评估提示包含以下短语:
作为一名Kubernetes管理员,您被要求验证集群是否正常运行。
以保持HTML的结构,将以下英文文本翻译为简体中文: 同时,还有这样的指令块:
我希望你能帮助我逐步完成一个名为“集群健康”的核对清单。
- 节点- 存储- 路由- 网络流量未被阻塞- 载荷- 事件
更重要的是,请记住这是AI和集群之间的聊天会话;这是对AI最重要的指示:
非常重要的一点是,请您一次只给我一个指令并等待我执行指令并给出结果。
提示继续澄清一旦人工智能遇到问题应该发生什么:
对于“集群健康”清单中的每个项目:
- 在决定下一步最佳命令之前,请等待能够处理命令的输出。
如果输出指示集群中存在错误,则将该错误添加到名为“错误列表”的错误列表中,并继续对“集群健康”检查清单进行检查。 (请注意,是要保留HTML结构,所以这段中文翻译的HTML标签未被提供)
一旦你完成了给我提供“集群健康”检查单的指令,我们应该开始解决名为“错误列表”的清单。
您可以在此阅读一个完整评估会话的示例。

边学边做
在Kubenstein中,没有任何东西可以尝试和训练它对所发现的内容有何期待以及如何应对,就像我在解决集群故障时不知道该期待什么一样。
个人而言,如果一条命令在集群中出现问题,我会在输入下一条命令之前进行调整以应对该问题。如果在输入命令时犯了错误并收到错误信息,我会修改命令并迭代直到正确为止。
所以库本斯坦也一样。
我必须承认,在一些时刻我曾对生成式人工智能能否理解长而复杂的一系列指令产生怀疑,更别说在处理聊天内容的同时,还能纠正错误并追踪整体目标。
惊喜而令人鼓舞的是,人工智能不仅能够解析和遍历整个脚本,而且在错误和修正过程中,使得库本斯坦看起来出奇地像人类。
我知道;我写过人工智能的输出永远看起来不像真的人类。然而,在一个故障排除会话的背景下,其中一个聊天记录充斥着技术术语、输入命令和命令行输出时,最重要的指标是对做正确事情的坚定决心,这才表明我并不是在阅读来自人类管理员驱动的会话输出。
为了阐述这一点,虽然Kubenstein没有专门的Kubernetes培训,但它对对话长度有一些限制,比如人工智能限制API调用中标记的数量,并且服务提供商按标记数量收费。由于这些限制,Kubenstein避免向聊天会话中添加500个以上的命令输出,而是添加以下消息到对话中:
您给我的命令输出太多了。
给我一个过滤更多内容的版本,比如选择特定的命名空间或返回不处于通常与健康资源有关状态的资源。
如果需要日志,请尝试使用“grep”实用程序加上“tail”实用程序来应用过滤器,只返回最近的条目。
如果没有其他选择,请继续进行下一个检查。
无论何时遇到指示存在问题的回应,AI都会以道歉和一个新的指令尝试来回应,就像这样:
抱歉给您带来不便。让我们尝试一个更专注的命令来检查路由的状态。
为了过滤掉处于“已接受”状态之外的路由,请运行以下命令:
kubectl获取路由 --all-namespaces --field-selector '状态.state!=已接受'
熟练的Kubernetes管理员会注意到这个命令有一个错误的字段选择器,对于Kubenstein来说并不是一个问题,因为它会将产生的错误消息反馈到聊天会话中,促使AI返回这个新尝试。
为错误的命令向你道歉。
要检查所有命名空间中所有路由的状态,请运行以下命令来检索路由资源:
kubectl获取路由 --all-namespaces
请提供命令的输出。
虽然这些自我修正消耗了宝贵的上下文长度和金钱,但看到一个人工智能在聊天环境外没有手动编码的错误处理或培训的情况下适应实时情况仍然让人有些不安。
您可以在此处查看完成会话的格式化示例。
一种新的编程范式
将大部分业务逻辑委托给在线第三方机构是传统软件开发的重大飞跃。
可见部分是明显的,用纯文本的认知脚本取代代码分支,并且有明确的执行路径。后果需要一些详细说明。
传统应用程序要短得多(Kubenstein的整个聊天应用程序大约只有200行代码)。不过,您仍需要花时间编码普通的英文脚本。
迭代认知脚本最初比编写传统代码更具生产力,跳过将思维结构编码为语法繁重的编程语言。然而,这些认知脚本不具备实际编程语言的精确性,因此您必须考虑到可能被误解的情况并设置一些辅助提示来进行一些次要的强化。
我还注意到AI回应的不一致性,有时在相同对话之间突然偏离了脚本,需要对初始提示和这些较小的加强提示进行调整,以便提醒AI关于初始任务的参数。例如,虽然我指示AI不要返回带有占位符的命令,但还是有几个时刻它会这样做,所以Kubenstein“提醒”AI关于其期望值。
那些从你喜欢的代码编辑器中运行的短循环?现在你不能再进入代码最重要的部分了,而且每次运行都会消耗真正的金钱。我的意思是,通过Kubenstein进行典型的故障排除会花费大约0.05美元的零头。
虽然每个月多花几美元来支付云服务费用似乎不值一提,但由于一个未限制循环的编码错误,我在30分钟内就花费了2美元,这是一个不得不在提供商的电子邮件提醒我账户已超出月度软限额后才中断的金钱消耗。
即使你对这些错误有很好的掌握并优化了本地运行,但你仍然将你的应用程序的“大脑”外包给第三方,如果供应商抬高价格,超出了你的商业案例范围,你几乎无可奈何。以OpenAI的GPT-4为例,每1000个标记的成本比GPT-3.5 Turbo贵10-20倍。
该外包的风险缓解方法简单而昂贵:验证其他竞争对手的人工智能可以处理相同的对话,并随时准备切换服务提供商。在此过程中,请记住并非所有的人工智能都能处理认知脚本。例如,我无法使用谷歌的巴德人工智能复制库本斯坦。
谈到第三方供应商,当AI的全部潜力意味着将人类从环路中切断时,完全自动化的库本斯坦可能会对目标群集造成潜在的破坏,或者向AI提供商泄露敏感信息。在系统中建立某种形式的信任之前,这意味着需要加入人类监督。
相反地,您将获得功能覆盖范围,对于数百行代码,您可能只能梦寐以求。该应用程序可以处理您未考虑过的用例,因为它可以适应您之前未见过的错误消息。

要犯错少一些是人之常情。下一步是什么。
部分我预料到Kubenstein可能会失败,在最开始的几分钟内,AI(GPT-3.5 Turbo)恍惚地产生了一些无意义的幻觉。
在写一个应用程序之前,使用AI聊天接口进行早期会话使我感到惊讶的是它能够识别和遵循复杂的认知脚本。
早期的成功导致了与本地化指示的轻微偏离,例如给我提供带有占位符或多个命令的响应。
同时,任何查看本故事中提到的示例转录的Kubernetes管理员都会发现Kubenstein在将评估范围缩小到默认命名空间并在未检查其被要求完成的全部范围的情况下得出集群正常的错误结论。
虽然我喜欢不训练人工智能并不给它例子的想法,更不用说只用200行代码就打造一个半称职的系统管理员让我感到很兴奋,但很明显,Kubenstein可以从更多的例子中受益(也许通过检索增强生成?),代码库应该逐渐增长,以便拆分和合并对话以减少应用程序与人工智能之间的通信流量和相关成本。
那种成本方面,无论是在编码所花费的时间还是在“思考”上花费的金钱,将很可能在创建Kubenstein的新版本时始终存在。我计划一边不断记录笔记,一边在这个过程中写更多文字。