使用 ChatGPT 进行自动知识图谱构建
简介
在本篇文章中,我们将介绍如何使用OpenAI的gpt-3.5-turbo从原始文本数据构建知识图谱。语言模型已经在文本生成和问答任务中表现出优秀的性能。检索增强生成(RAG)进一步提高了它们的性能,使其能够访问最新的领域特定知识。我们在本文中的目标是利用语言模型作为信息提取工具,将原始文本转化为可以轻松查询以获取有用见解的事实。但首先,我们需要定义一些关键概念。
什么是知识图谱?
知识图谱是一个语义网络,用于表示和互连现实世界中的实体。这些实体通常对应于人、组织、物体、事件和概念。知识图谱由具有以下结构的三元组组成:
头部 → 关系 → 尾部
或者用语义网络的术语来讲:
主语 → 谓语 → 宾语
网络表示使我们能够提取和分析存在于这些实体之间的复杂关系。
知识图谱通常配有概念、关系及其属性的定义,即本体论。本体论是一种形式规范,定义了目标领域中的概念及其关联,从而为网络提供语义。
本体论被搜索引擎和其他网络自动代理用于理解特定网页的内容意义,以便对其进行索引并正确展示。
案例描述
对于这个用例,我们将使用OpenAI的gpt-3.5-turbo从亚马逊产品数据集中的产品描述创建一个知识图谱。
在Web上有很多用于描述产品的本体论,最流行的是Good Relations本体论和Product Types本体论。这两个本体论都扩展了Schema.org本体论。
Schema.org是一个协作的社区活动,旨在创建、维护和推广互联网上的结构化数据模式。Schema.org词汇可以与多种不同的编码方式一起使用,包括RDFa、Microdata和JSON-LD。
对于手头的任务,我们将使用Schema.org对产品和相关概念的定义,包括它们的关系,从产品描述中提取三元组。
实施
我们将使用Python来实现解决方案。首先,我们需要安装和导入所需的库。
导入库并读取数据
!pip install pandas openai sentence-transformers networkx
import json
import logging
import matplotlib.pyplot as plt
import networkx as nx
from networkx import connected_components
from openai import OpenAI
import pandas as pd
from sentence_transformers import SentenceTransformer, util
现在,我们将把亚马逊产品数据集读取为一个pandas dataframe。
data = pd.read_csv("amazon_products.csv")
我们可以在下图中看到数据集的内容。数据集包含以下列:'PRODUCT_ID'、'TITLE'、'BULLET_POINTS'、'DESCRIPTION'、'PRODUCT_TYPE_ID' 和 'PRODUCT_LENGTH'。我们将把'标题'、'项目符号'和'描述'列合并为一列'text',该列将代表我们将提示ChatGPT从中提取实体和关系的产品规格。

data['text'] = data['TITLE'] + data['BULLET_POINTS'] + data['DESCRIPTION']
信息提取
我们将指示ChatGPT从提供的产品规格中提取实体和关系,并将结果作为JSON对象数组返回。JSON对象必须包含以下键:'head','head_type','relation','tail'和'tail_type'。
‘head’关键字必须包含从用户提示提供的列表中选择的提取实体的文本。‘head_type’关键字必须包含提取头实体的类型,该类型必须是从用户提供的列表中的一个。‘relation’关键字必须包含‘head’和‘tail’之间的关系类型,‘tail’关键字必须表示三元组中的对象,即提取实体的文本,而‘tail_type’关键字必须包含尾实体的类型。
我们将使用下面列出的实体类型和关系类型来激活ChatGPT进行实体关系抽取。我们将把这些实体和关系映射到Schema.org本体中的相应实体和关系。映射中的键表示提供给ChatGPT的实体和关系类型,而值表示来自Schema.org的对象和属性的URLS。
# ENTITY TYPES:
entity_types = {
"product": "https://schema.org/Product",
"rating": "https://schema.org/AggregateRating",
"price": "https://schema.org/Offer",
"characteristic": "https://schema.org/PropertyValue",
"material": "https://schema.org/Text",
"manufacturer": "https://schema.org/Organization",
"brand": "https://schema.org/Brand",
"measurement": "https://schema.org/QuantitativeValue",
"organization": "https://schema.org/Organization",
"color": "https://schema.org/Text",
}
# RELATION TYPES:
relation_types = {
"hasCharacteristic": "https://schema.org/additionalProperty",
"hasColor": "https://schema.org/color",
"hasBrand": "https://schema.org/brand",
"isProducedBy": "https://schema.org/manufacturer",
"hasColor": "https://schema.org/color",
"hasMeasurement": "https://schema.org/hasMeasurement",
"isSimilarTo": "https://schema.org/isSimilarTo",
"madeOfMaterial": "https://schema.org/material",
"hasPrice": "https://schema.org/offers",
"hasRating": "https://schema.org/aggregateRating",
"relatedTo": "https://schema.org/isRelatedTo"
}
为了使用ChatGPT进行信息提取,我们创建了一个OpenAI客户端,并使用聊天完成API为原始产品规范中的每个已识别关系生成JSON对象的输出数组。我们选择默认模型为gpt-3.5-turbo,因为它的性能对于这个简单的演示已经足够好了。
client = OpenAI(api_key="<YOUR_API_KEY>")
def extract_information(text, model="gpt-3.5-turbo"):
completion = client.chat.completions.create(
model=model,
temperature=0,
messages=[
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": user_prompt.format(
entity_types=entity_types,
relation_types=relation_types,
specification=text
)
}
]
)
return completion.choices[0].message.content
提示工程
系统提示变量包含了指导ChatGPT从原始文本中提取实体和关系,并以JSON对象数组的形式返回结果的指令。每个JSON对象都有以下键:'head','head_type','relation','tail'和'tail_type'。
system_prompt = """You are an expert agent specialized in analyzing product specifications in an online retail store.
Your task is to identify the entities and relations requested with the user prompt, from a given product specification.
You must generate the output in a JSON containing a list with JOSN objects having the following keys: "head", "head_type", "relation", "tail", and "tail_type".
The "head" key must contain the text of the extracted entity with one of the types from the provided list in the user prompt, the "head_type"
key must contain the type of the extracted head entity which must be one of the types from the provided user list,
the "relation" key must contain the type of relation between the "head" and the "tail", the "tail" key must represent the text of an
extracted entity which is the tail of the relation, and the "tail_type" key must contain the type of the tail entity. Attempt to extract as
many entities and relations as you can.
"""
user_prompt变量包含了数据集中单个规范的所需输出的单个示例,并提示ChatGPT以相同方式从提供的规范中提取实体和关系。这是使用ChatGPT进行单次学习的一个例子。
user_prompt = """Based on the following example, extract entities and relations from the provided text.
Use the following entity types:
# ENTITY TYPES:
{entity_types}
Use the following relation types:
{relation_types}
--> Beginning of example
# Specification
"YUVORA 3D Brick Wall Stickers | PE Foam Fancy Wallpaper for Walls,
Waterproof & Self Adhesive, White Color 3D Latest Unique Design Wallpaper for Home (70*70 CMT) -40 Tiles
[Made of soft PE foam,Anti Children's Collision,take care of your family.Waterproof, moist-proof and sound insulated. Easy clean and maintenance with wet cloth,economic wall covering material.,Self adhesive peel and stick wallpaper,Easy paste And removement .Easy To cut DIY the shape according to your room area,The embossed 3d wall sticker offers stunning visual impact. the tiles are light, water proof, anti-collision, they can be installed in minutes over a clean and sleek surface without any mess or specialized tools, and never crack with time.,Peel and stick 3d wallpaper is also an economic wall covering material, they will remain on your walls for as long as you wish them to be. The tiles can also be easily installed directly over existing panels or smooth surface.,Usage range: Featured walls,Kitchen,bedroom,living room, dinning room,TV walls,sofa background,office wall decoration,etc. Don't use in shower and rugged wall surface]
Provide high quality foam 3D wall panels self adhesive peel and stick wallpaper, made of soft PE foam,children's collision, waterproof, moist-proof and sound insulated,easy cleaning and maintenance with wet cloth,economic wall covering material, the material of 3D foam wallpaper is SAFE, easy to paste and remove . Easy to cut DIY the shape according to your decor area. Offers best quality products. This wallpaper we are is a real wallpaper with factory done self adhesive backing. You would be glad that you it. Product features High-density foaming technology Total Three production processes Can be use of up to 10 years Surface Treatment: 3D Deep Embossing Damask Pattern."
################
# Output
[
{{
"head": "YUVORA 3D Brick Wall Stickers",
"head_type": "product",
"relation": "isProducedBy",
"tail": "YUVORA",
"tail_type": "manufacturer"
}},
{{
"head": "YUVORA 3D Brick Wall Stickers",
"head_type": "product",
"relation": "hasCharacteristic",
"tail": "Waterproof",
"tail_type": "characteristic"
}},
{{
"head": "YUVORA 3D Brick Wall Stickers",
"head_type": "product",
"relation": "hasCharacteristic",
"tail": "Self Adhesive",
"tail_type": "characteristic"
}},
{{
"head": "YUVORA 3D Brick Wall Stickers",
"head_type": "product",
"relation": "hasColor",
"tail": "White",
"tail_type": "color"
}},
{{
"head": "YUVORA 3D Brick Wall Stickers",
"head_type": "product",
"relation": "hasMeasurement",
"tail": "70*70 CMT",
"tail_type": "measurement"
}},
{{
"head": "YUVORA 3D Brick Wall Stickers",
"head_type": "product",
"relation": "hasMeasurement",
"tail": "40 tiles",
"tail_type": "measurement"
}},
{{
"head": "YUVORA 3D Brick Wall Stickers",
"head_type": "product",
"relation": "hasMeasurement",
"tail": "40 tiles",
"tail_type": "measurement"
}}
]
--> End of example
For the following specification, generate extract entitites and relations as in the provided example.
# Specification
{specification}
################
# Output
"""
现在,我们对数据集中的每个规格都调用extract_information函数,并创建一个包含所有提取的三元组的列表,这将表示我们的知识图谱。为了进行演示,我们将仅使用100个产品规格的子集生成一个知识图谱。
kg = []
for content in data['text'].values[:100]:
try:
extracted_relations = extract_information(content)
extracted_relations = json.loads(extracted_relations)
kg.extend(extracted_relations)
except Exception as e:
logging.error(e)
kg_relations = pd.DataFrame(kg)
信息提取的结果在下方图中显示。
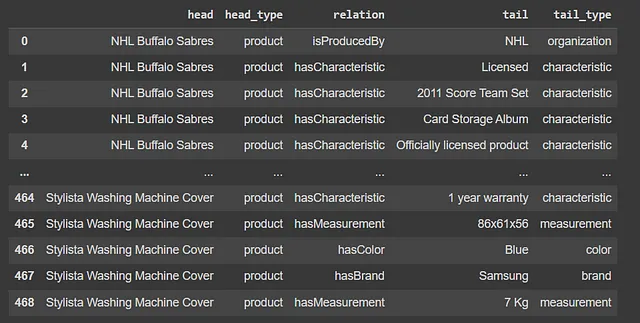
实体解析
实体消解(ER)是将对应于现实世界概念的实体进行消除歧义的过程。在这种情况下,我们将尝试对数据集中的头实体和尾实体执行基本的实体消解。这样做的原因是为了对文本中存在的事实进行更简洁的表示。
我们将使用NLP技术执行实体消解,更具体地说,我们将使用sentence-transformers库为每个头部创建嵌入,并计算头部实体之间的余弦相似度。
我们将使用“全为MiniLM-L6-v2”句子转换器来创建嵌入,因为它是一个快速而相对准确的模型,适用于这个使用案例。对于每对头实体,我们将检查相似度是否大于0.95,如果是,我们将考虑这些实体作为同一实体,并将它们的文本值标准化为相等。尾实体的情况同理。
这个过程将帮助我们实现以下结果。如果我们有两个实体,一个实体值为‘Microsoft’,第二个实体值为‘Microsoft Inc.’,那么这两个实体将被合并为一个。
我们以以下方式加载和使用嵌入模型来计算第一个和第二个头实体之间的相似度。
heads = kg_relations['head'].values
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = embedding_model.encode(heads)
similarity = util.cos_sim(embeddings[0], embeddings[1])
为了在实体解析之后可视化提取的知识图谱,我们使用networkx Python库。首先,我们创建一个空图,并将每个提取的关系添加到图中。
G = nx.Graph()
for _, row in kg_relations.iterrows():
G.add_edge(row['head'], row['tail'], label=row['relation'])
要绘制图表,我们可以使用以下代码:
pos = nx.spring_layout(G, seed=47, k=0.9)
labels = nx.get_edge_attributes(G, 'label')
plt.figure(figsize=(15, 15))
nx.draw(G, pos, with_labels=True, font_size=10, node_size=700, node_color='lightblue', edge_color='gray', alpha=0.6)
nx.draw_networkx_edge_labels(G, pos, edge_labels=labels, font_size=8, label_pos=0.3, verticalalignment='baseline')
plt.title('Product Knowledge Graph')
plt.show()
下图显示了从生成的知识图中提取的子图。
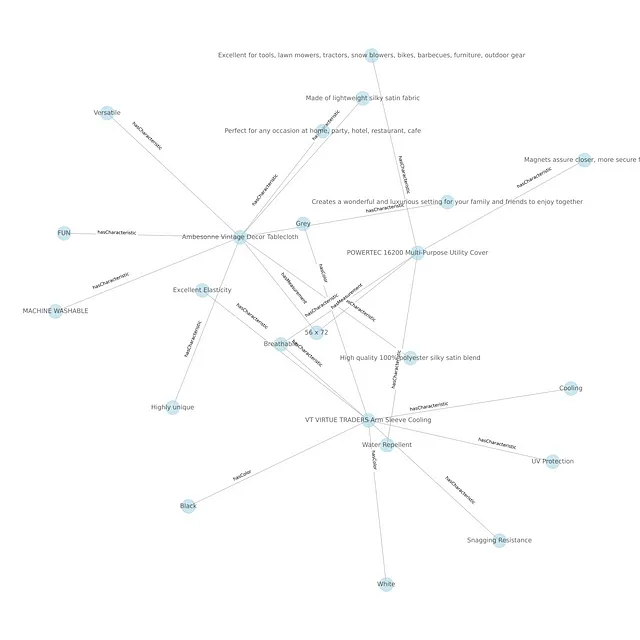
我们可以看到,通过这种方式,我们可以根据它们共享的特征连接多个不同的产品。这对于学习产品之间的共同属性、规范化产品规格、通过使用类似Schema.org的公共模式来描述网络资源,甚至基于产品规格进行产品推荐非常有用。
结论
大多数公司在数据湖中拥有大量未使用的非结构化数据。创建知识图谱来提取这些未使用数据中的洞见,将有助于获取有关未经处理和非结构化文本语料库中被困的信息,并利用这些信息做出更明智的决策。
到目前为止,我们已经看到LLMs可以用于从原始文本数据中提取实体和关系的三元组,并自动构建知识图谱。在下一篇文章中,我们将尝试基于提取的知识图谱创建产品推荐系统。