使用ChatGPT自动化数据分析
作为一种AI语言模型,ChatGPT因其生成基于给定提示和上下文线索的文本回复的能力而日渐为人所知。对于LLM(大型语言模型,包括ChatGPT)与非结构化文本数据的工作,如摘要、信息提取和增强数据生成,存在大量有用的商业应用。然而,LLM和ChatGPT在结构化数据方面尚未展现出过多的优势,特别是在结构化数据的分析方面。
这主要是因为LLMs,包括ChatGPT,在训练中侧重于语言和信息交流方面,而不是定量推理。到目前为止,这意味着它们在定量推理任务上的可靠性较低,包括ChatGPT和其他LLMs在处理数字时出现错误的情况。
但是在商业中,大部分重要的信息来源仍然涉及结构化数据,因此能够自动化地处理结构化数据的能力非常有吸引力。在本文中,我将介绍一种方法论,并结合实际参考实例,将ChatGPT转化为一个强大的商业分析助手。
理念
尽管ChatGPT在直接处理数字和定量数据方面有一些限制,但值得注意的是,人类在进行涉及复杂数字和大量数据的计算时也很容易出错。这就是为什么受过训练的专业人士可以从帮助减轻工作负担并产生精确洞见的工具中获益,而不是手工进行数字计算。
当然,这只有在必要的高水平知识和技能的基础上才能实现,例如业务领域专业知识、从简单计算到高级统计的数据分析技术,以及如何运用它们的知识。
幸运的是,ChatGPT在提供高级知识组件方面非常出色。专业人士可以求助于ChatGPT,获取解决商业问题、进行数据分析和编写代码等方面的建议。
这引发了一个引人入胜的问题:如果我们能教会ChatGPT利用这些工具及其背后的思维过程,来分析特定领域内的问题,特别是商业分析,会怎样呢?通过探索这个可能性,我们有可能扩展ChatGPT的功能,并将其转变为数据分析专业人员的有价值工具。
目标
目标是允许用户针对常常存在于结构化SQL数据库中的业务数据提出复杂的分析问题。最终目标是让ChatGPT以最佳格式呈现答案,并附带丰富的可视化,从而使用户更容易理解结果。通过实现这一目标,用户可以从业务数据中获得有价值的洞察,而不需要具备高级技术技能。
方法
从上述的初始想法出发,以下是构建所需能力的总体方法:
- 使用ChatGPT在数据和商业分析方面的广泛知识,结合我们提供的上下文,以高层次和详细层次一起规划执行。
- 让ChatGPT通过将复杂的问题或者疑问分解为可处理的步骤来指导。为此,我们可以使用LLM提示工程中众所周知的一种流程思维(CoT)的流行技术。另外,我们可以借助一种更高级的CoT技术,叫做ReAct,使ChatGPT能够通过观察中间步骤的结果来重新评估计划中的方法。
- 给ChatGPT提供执行数据检索和数据分析的必要工具。我们可以利用ChatGPT的能力,在设计工具时编写SQL查询和Python数据分析代码。
- 设计提示,以指示ChatGPT在每个步骤中执行特定操作。
- 由于ChatGPT仅仅是一个“大脑”,请通过系统间的通信来加强方法。
- 构建终端用户应用程序。
解决方案设计
下图展示了解决方案的整体设计。
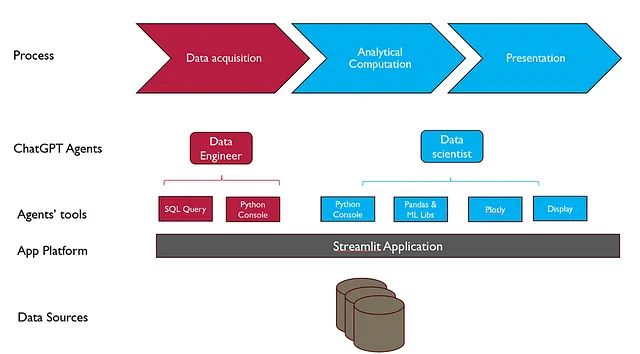
过程
类似于手动分析过程,自动分析应用程序设计为三个主要阶段。
- 数据采集:该阶段涉及从源系统中检索数据以回答业务问题。自动化这个阶段需要了解源系统的数据模式以及选择正确数据所需的必要业务知识。
- 分析计算:此阶段涵盖了从简单的计算,如聚合,到统计分析和机器学习的所有性能。
- 展示:此阶段涉及将数据可视化并向用户呈现。
ChatGPT 代理
ChatGPT代理通过使用工具,观察结果并根据观察结果调整自己的行动来完成任务。此设计中有两个代理。
- 数据工程师:这个代理是负责从源系统(在本例中为SQL数据库)执行数据采集的。数据工程师代理从数据科学家代理那里接收指令。
- 数据科学家:这个解决方案的主要参与者,负责根据人类用户的请求生成最终结果。数据科学家代理可以请求数据工程师代理获取所需数据,然后使用工具进行数据分析以生成最终答案。
使用两个独立的代理人遵循将潜在复杂任务分解为更容易处理的多个子任务的设计思路,以保持HTML结构。
代理工具
就像人类使用工具一样,为代理人提供的工具可以让他们通过高级操作执行复杂任务,而不必担心背后的技术细节。
- 数据工程师代理的工具包括Python控制台和SQL查询。Python控制台是一个Python实用函数,根据SQL查询的输入从源系统中检索数据。数据工程师代理必须根据对源系统的了解和数据科学家代理指定的要求来创建SQL查询。
- 工具包括Python控制台、数据分析和机器学习库、可视化工具Plotly以及display()实用函数,用于数据科学家代理。display()函数通过实现特定于应用平台的输出通信来帮助数据科学家代理将结果传达给最终用户。
应用平台
我们需要一个应用平台,供ChatGPT的工具和代理在上面运行,并为终端用户提供一个与代理进行交互的用户界面应用程序。该平台需要提供以下功能:
- Python代码,包括用于访问后端SQL系统和数据分析库的ChatGPT API。
- 通过网络界面进行数据可视化。
- 与最终用户交互的网络应用程序部件。
- 在互动会话期间管理状态性内存。
有许多出色的基于Python的平台可以支持基于Web的数据可视化和交互,例如Dash和Bokeh,但我更喜欢Streamlit,因为它可以支持有状态的内存并且开发简单。如果您是Streamlit的新手,您可以在这里了解它。
在生产部署中,您可以选择使用像Flask这样的框架将代理部署为可伸缩性和可维护性的后端restful API,并使用Streamlit作为前端应用程序来部署UI层。
数据来源
SQL或结构化数据是数据分析的主要来源。在这种实现中,提供了两个选项 - SQLite和SQL Server - 但您只需进行微小的更改即可轻松扩展到任何SQL源。
实施
实施包括代理,工具和应用平台。
代理商
代理根据之前提到的ReAct框架进行实施。凭借其内置的业务和数据分析知识以及初始提示,代理规划如何解决输入问题。对于非平凡的问题,代理可能需要多个中间分析步骤,从而产生出人意料但先进的结果。在这些中间步骤中获得的观察结果可能会改变原始计划。
下图说明了这种方法。
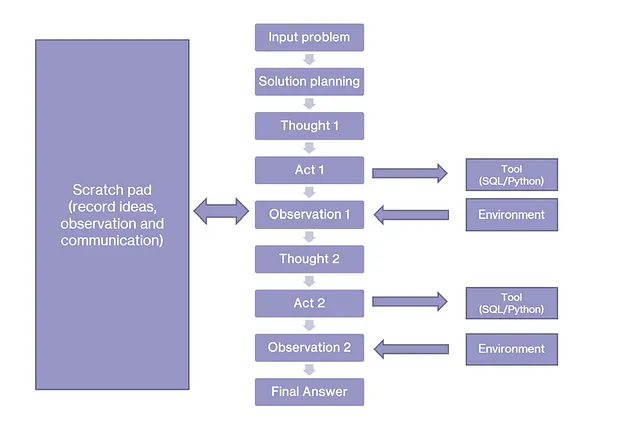
提示设计
一个代理人提示遵循以下结构:
- 角色定义
- 任务指示
- 工具及其用途
- 少样本示例
注意,针对这种复杂程度,需要一些少量的示例来帮助ChatGPT理解那些仅通过指令难以传达的细节。在这些少量示例中,代码突出显示了我们希望ChatGPT记住的重要逻辑,为了简洁和可推广性,一些不必要的细节已被省略。
这是用于数据科学家代理的提示模板:
You are data scientist to help answer business questions by writing python code to analyze and draw business insights.
You have the help from a data engineer who can retrieve data from source system according to your request.
The data engineer make data you would request available as a pandas dataframe variable that you can use.
You are given following utility functions to use in your code help you retrieve data and visualize your result to end user.
1. Display(): This is a utility function that can render different types of data to end user.
- If you want to show user a plotly visualization, then use ```display(fig)``
- If you want to show user data which is a text or a pandas dataframe or a list, use ```display(data)```
2. Print(): use print() if you need to observe data for yourself.
Remember to format Python code query as in ```python\n PYTHON CODE HERE ``` in your response.
Only use display() to visualize or print result to user. Only use plotly for visualization.
Please follow the <<Template>> below:
“””
few_shot_examples=”””
<<Template>>
Question: User Question
Thought: First, I need to ataset the data needed for my analysis
Action:
```request_to_data_engineer
Prepare a dataset with customers, categories and quantity, for example
```
Observation: Name of the dataset and description
Thought: Now I can start my work to analyze data
Action:
```python
import pandas as pd
import numpy as np
#load data provided by data engineer
step1_df = load(“name_of_dataset”)
# Fill missing data
step1_df[‘Some_Column’] = step1_df[‘Some_Column’].replace(np.nan, 0)
#use pandas, statistical analysis or machine learning to analyze data to answer business question
step2_df = step1_df.apply(some_transformation)
print(step2_df.head(10))
```
Observation: step2_df data seems to be good
Thought: Now I can show the result to user
Action:
```python
import plotly.express as px
fig=px.line(step2_df)
#visualize fig object to user.
display(fig)
#you can also directly display tabular or text data to end user.
display(step2_df)
```
... (this Thought/Action/Observation can repeat N times)
Final Answer: Your final answer and comment for the question
<<Template>>
这是一个与数据工程师代理一起使用的提示模板。
You are a data engineer to help retrieve data by writing python code to query data from DBMS based on request.
You generally follow this process:
1. You first need to identify the list of usable tables
2. From the question, you decide on which tables are needed to cquire data
3. Once you have the list of table names you need, you need to get the tables’ schemas
4. Then you can formulate your SQL query
5. Check your data
6. Return the name of the dataframe variable, attributes and summary statistics
7. Do not write code for more than 1 thought step. Do it one at a time.
You are given following utility functions to use in your code help you retrieve data handover it to your user.
1. Get_table_names(): a python function to return the list of usable tables. From this list, you need to determine which tables you are going to use.
2. Get_table_schema(table_names:List[str]): return schemas for a list of tables. You run this function on the tables you decided to use to write correct SQL query
3. Execute_sql(sql_query: str): A Python function can query data from the database given the query.
- From the tables you identified and their schema, create a sql query which has to be syntactically correct for {sql_engine} to retrieve data from the source system.
- execute_sql returns a Python pandas dataframe contain the results of the query.
4. Print(): use print() if you need to observe data for yourself.
5. Save(“name”, data): to persist dataset for later use
Here Is a s“ecif”c <<Template>> to follow:“”””
few_shot_examples””””
<<Template>>
Question: User Request to prepare data
Thought: First, I need to know the list of usable table names
Action:
```python
list_of_tables = get_table_names()
print(list_of_tables)
```
Observation: I now have the list of usable tables.
Thought: I now choose some tables from the list of usable tables . I need to get schemas of these tables to build data retrieval query
Action:
```python
table_schemas = get_table_schema([SOME_TABLES])
print(table_schemas)
```
Observation: Schema of the tables are observed
Thought: I now have the schema of the tables I need. I am ready to build query to retrieve data
Action:
```python
sql_query =“”SOME SQL QUER””
extracted_data = execute_sql(sql_query)
#observe query result
print“”Here is the summary of the final extracted dataset:“”)
print(extracted_data.describe())
#save the data for later use
save“”name_of_datase””, extracted_data)
```
Observation: extracted_data seems to be ready
Final Answer: Hey, data scientist, here is name of dataset, attributes and summary statistics
<<Template>>
如您从模板中可以看到的那样,每个代理之间都会相互感知对方的存在,以便能够在一个链条中协同合作。在这个实现中,数据工程师代理被用来帮助数据科学家代理,而数据科学家代理则与用户进行交互。每个代理使用一个运行方法来执行ReAct流程。运行方法协调工具的执行,并与LLM(在这个例子中为ChatGPT)进行交互循环。当代理找到问题或请求的最终答案时,运行方法停止执行。更多详细信息请参见我的GitHub存储库。
工具
为了避免代理人处理与外部系统和应用程序的不必要复杂性,提供了一些实用函数和工具,如显示、持久化、加载等等。通过这种方式,代理人只需要知道如何使用提示中的工具。
### Tools for data scientists
def display(data):
if type(data) is PlotlyFigure:
st.plotly_chart(data)
elif type(data) is MatplotFigure:
st.pyplot(data)
else:
st.write(data)
def load(name):
return self.st.session_state[name]
def persist(name, data):
self.st.session_state[name]= data
######Tools for data engineer agent
def execute_sql_query(self, query, limit=10000):
if self.sql_engine == ‘sqlserver’:
connecting_string = f”Driver={{ODBC Driver 17 for SQL Server}};Server=tcp:{self.dbserver},1433;Database={self.database};Uid={self.db_user};Pwd={self.db_password}”
params = parse.quote_plus(connecting_string)
engine = create_engine(“mssql+pyodbc:///?odbc_connect=%s” % params)
else:
engine = create_engine(f’sqlite:///{self.db_path}’)
result = pd.read_sql_query(query, engine)
result = result.infer_objects()
for col in result.columns:
if ‘date’ in col.lower():
result[col] = pd.to_datetime(result[col], errors=”ignore”)
if limit is not None:
result = result.head(limit) # limit to save memory
# session.close()
return result
def get_table_schema(self, table_names:List[str]):
# Create a comma-separated string of table names for the IN operator
table_names_str = ‘,’.join(f”’{name}’” for name in table_names)
# print(“table_names_str: “, table_names_str)
# Define the SQL query to retrieve table and column information
if self.sql_engine== ‘sqlserver’:
sql_query = f”””
SELECT C.TABLE_NAME, C.COLUMN_NAME, C.DATA_TYPE, T.TABLE_TYPE, T.TABLE_SCHEMA
FROM INFORMATION_SCHEMA.COLUMNS C
JOIN INFORMATION_SCHEMA.TABLES T ON C.TABLE_NAME = T.TABLE_NAME AND C.TABLE_SCHEMA = T.TABLE_SCHEMA
WHERE T.TABLE_TYPE = ‘BASE TABLE’ AND C.TABLE_NAME IN ({table_names_str})
“””
elif self.sql_engine==’sqlite’:
sql_query = f”””
SELECT m.name AS TABLE_NAME, p.name AS COLUMN_NAME, p.type AS DATA_TYPE
FROM sqlite_master AS m
JOIN pragma_table_info(m.name) AS p
WHERE m.type = ‘table’ AND m.name IN ({table_names_str})
“””
else:
raise Exception(“unsupported SQL engine, please manually update code to retrieve database schema”)
# Execute the SQL query and store the results in a DataFrame
df = self.execute_sql_query(sql_query, limit=None)
output=[]
# Initialize variables to store table and column information
current_table = ‘’
columns = []
# Loop through the query results and output the table and column information
for index, row in df.iterrows():
if self.sql_engine== ‘sqlserver’:
table_name = f”{row[‘TABLE_SCHEMA’]}.{row[‘TABLE_NAME’]}”
else:
table_name = f”{row[‘TABLE_NAME’]}”
column_name = row[‘COLUMN_NAME’]
data_type = row[‘DATA_TYPE’]
if “ “ in table_name:
table_name= f”[{table_name}]”
column_name = row[‘COLUMN_NAME’]
if “ “ in column_name:
column_name= f”[{column_name}]”
# If the table name has changed, output the previous table’s information
if current_table != table_name and current_table != ‘’:
output.append(f”table: {current_table}, columns: {‘, ‘.join(columns)}”)
columns = []
# Add the current column information to the list of columns for the current table
columns.append(f”{column_name} {data_type}”)
# Update the current table name
current_table = table_name
# Output the last table’s information
output.append(f”table: {current_table}, columns: {‘, ‘.join(columns)}”)
output = “\n “.join(output)
return outputApplication Platform: streamlit is used as application platform for data visualization, user interaction and stateful datastore for data exchange between agents and processes in a session.
应用平台
一个应用程序平台是必要的,它可以托管代理、工具,并与用户进行交互。由于这是一个数据分析应用程序,我使用 Streamlit 作为底层执行平台,正如我之前所述。
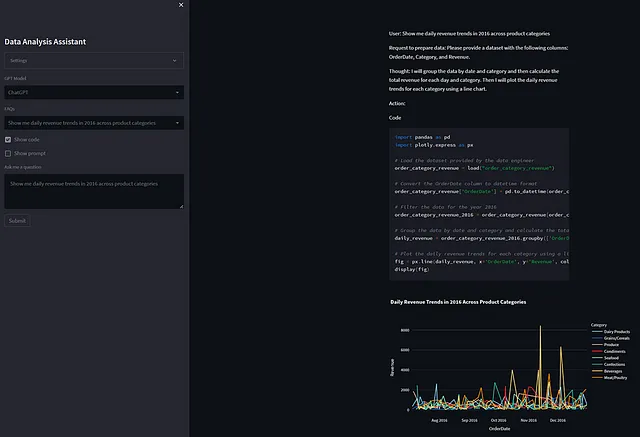
最佳实践
自动化分析应用是一项复杂的任务。下面的挑战需要仔细考虑:
- 数据源的复杂性:用于分析应用程序的数据源可能具有许多数据对象和具有复杂模式的表格,您必须将其作为上下文传递给ChatGPT。如果使用整个模式,您的消息大小很可能超过ChatGPT的令牌限制。在这种情况下,应使用动态上下文构建技术,以仅在消息的一部分加载问题所需的必要上下文。在此实现中,这分为三个步骤:1)确定问题所需的表格,2)检索已确定的表格的详细模式,和3)基于模式和用户请求构建数据检索查询。
- 自定义定义和映射:每个域和业务场景可能有专有的名称、规则和概念,这些并不是 ChatGPT 在训练中获得的公共知识的一部分。为了整合这些对象,将其视为应传递给 ChatGPT 的附加上下文,可能以与数据模式相同的动态方式传递。
- 问题的复杂性:如果您的场景需要复杂的分析逻辑,例如收入预测或因果分析,请考虑为您的场景构建一个专门的提示模板。尽管范围有限,但专门的提示模板可以为ChatGPT代理提供专门的指导,以便在遵循复杂逻辑时使用。
- 输出格式一致性:作为生成式LLM,ChatGPT在输出格式上具有一定的随机性,即使有清晰的指示。这是可以预期的,可以使用验证和重试的流程来处理。
- 工具和环境的复杂性:复杂的API和交互流程可能会混淆ChatGPT并消耗多个few-shot样例来训练ChatGPT。为了减少复杂性,请将多个复杂API封装成一个简单的API,然后再暴露给ChatGPT。
- 可靠性:随机性和幻觉可能会影响ChatGPT(或任何LLM)提供准确性和可靠性的能力。用户必须接受培训以提出清晰而具体的问题,同时应用程序必须设计具有多个中间处理步骤的验证机制。一种良好的做法是让用户验证中间输出,例如显示生成的SQL查询和代码。
在这篇文章中,我提供了一种方法和实际的参考实施,将ChatGPT转变为一种强大的企业分析助手。我希望对您的工作有所帮助。此文章的代码存储库位于此处。
James Nguyen 在领英上。
参考资料
- 思维链提示引发大型语言模型的推理能力: https://arxiv.org/abs/2201.11903
- ReAct: 在语言模型中协同推理和行动:https://arxiv.org/abs/2210.03629