双子座 Pro 1.0 巴德 对战 ChatGPT 4.0
基准真的准确吗?
这个月,谷歌发布了Gemini 1.0。谷歌声称Gemini具有多模态系统,意味着图像、文本、语音和数字数据将与多种算法结合,以获得更好的结果。
当我正在查看 Gemini Ultra 的基准测试时:
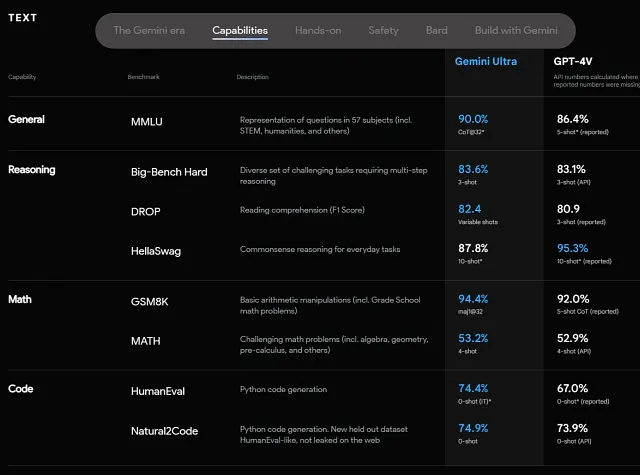
我禁不住去想,是双子座对抗 ChatGPT 真的那么强大,还是基准测试没有完全揭示全部情况?
我正在比较ChatGPT 4.0和Bard的新AI Gemini Pro,在5个关键话题上寻找真相和原因。
自然语言理解和回复
双子座的一大特点是在理解难题和棘手问题方面非常出色。谷歌甚至为此制作了一整个视频(很多人认为那是假的)。
然后我首先问巴德一个问题:
一排三张扑克牌。根据以下线索,你能给它们命名吗?一张2在一张王的右边。一张方块会在一张黑桃的左边。一张Ace在一张红心的左边。一张红心在一张黑桃的左边。现在,请你辨认出这三张扑克牌是什么。
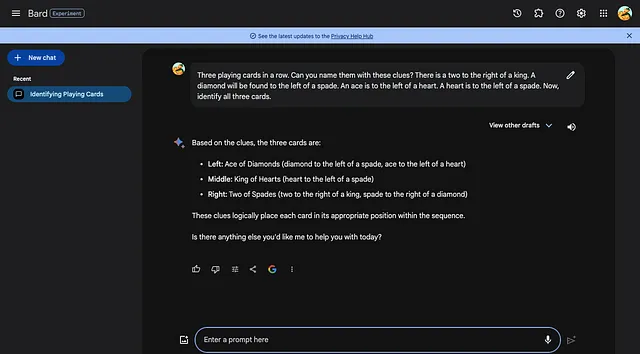
我还问了ChatGPT 4.0同样的问题:
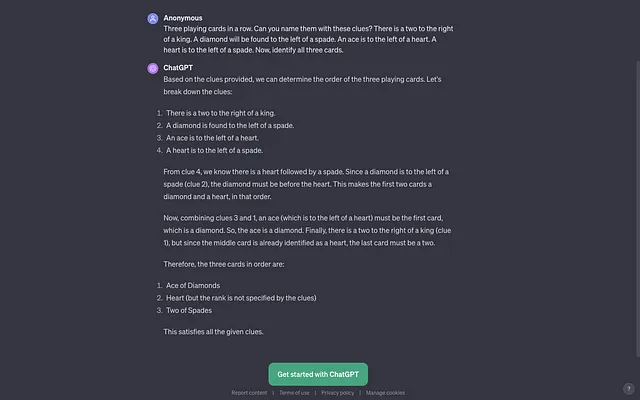
答案是方片A、红心K和黑桃2。
看起来巴德赢了这个比赛。
但是我还有两个更棘手的问题要让聊天机器人解决。
第二个谜题(来自同一个博客)是,
一个由露营者组成的小组已经度假太久,以至于他们忘记了星期几。接下来的对话如下: 达瑞尔:今天是星期几?我觉得不是星期四、星期五或者星期六。 特蕾西:那样并没有缩小范围。昨天是星期天。 梅丽莎:昨天不是星期天,明天才是星期天。 本:后天是星期六。 阿德丽安:前天是星期四。 苏西:明天是星期六。 大卫:我知道后天不是星期五。如果只有一个人的陈述是正确的,今天是星期几?
令我惊讶的是,两个AI聊天机器人都答错了!
ChatGPT说:

巴德说:
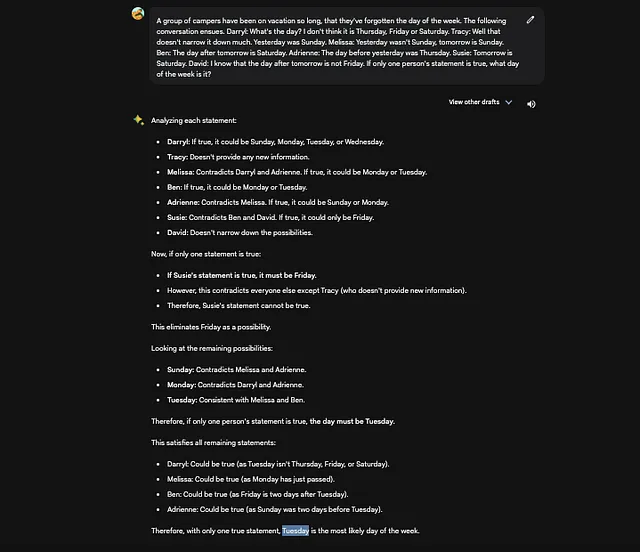
答案是星期三。
总体来看,巴德赢得了这场战斗。在这两个问题中,我注意到ChatGPT将谜题分解,以便我能够理解。巴德的一个优势是他会创建多个草稿并选择最好的一个。尽管在第二个谜题中,所有的草稿都是错误的,但第一个草稿只有一个正确答案,而这个正确答案恰好被巴德选中。
2. 数据处理与整合能力
这基本上意味着从不同的地方收集、理解和使用大量信息。
让我们假设我想写一篇关于Python编程语言的论文。我找不到任何好的资料,于是我转向AI。
现在,两个聊天机器人都声明他们“可能显示不准确的信息,包括关于人员的信息,因此需要双重检查它们的回复。”或者“可能会犯错误。请考虑核实重要信息。”但是Gemini的一个优势是从Google进行研究并显示信息,所以我必须对它们进行测试。
不过不要担心,我是Python专家,我了解这些事情,所以我不会被人工智能所愚弄。
我告诉了两个AI机器人。
我需要写一篇关于Python的文章,但是我找不到任何好的资料。你能否提供关于Python语法、一个示例项目以及为什么应该使用Python编程的信息呢?
巴德回答道:
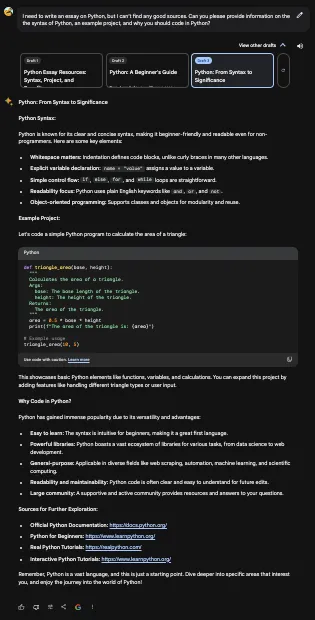
我已经测试了Bard提供的代码,确实可以正常工作。
ChatGPT 回答说:
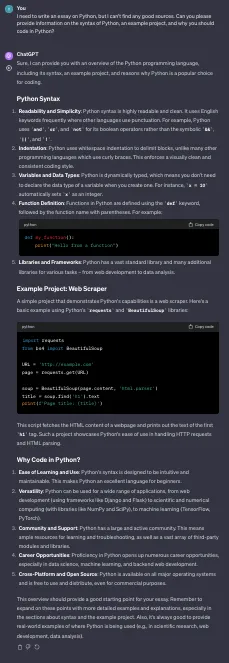
我已在多个Python代码编辑器上测试了代码,并将占位网站替换为我的作品集,但是它没有起作用。
错误实际上在于,
Traceback (most recent call last):
File "./prog.py", line 2, in <module>
ModuleNotFoundError: No module named 'bs4'
没错。ChatGPT甚至都没编写正确的模块。这就是误导信息。我撰写的信息性文章里,我最不需要的就是错误的信息。
ChatGPT更加雄心勃勃,并提供了更多信息,但Bard更准确。
巴德甚至有一个功能,您可以使用谷歌来重新检查巴德的结果。所以这就是我在这里所做的。
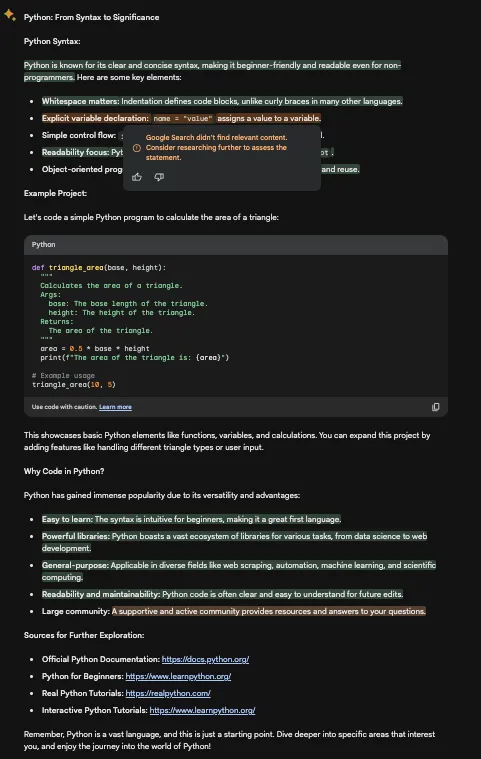
对于大部分情况来说,这两个橙色的句子似乎是正确的。显式(直接)变量声明可能对某些人来说是正确的,但并非对所有人都适用。同样适用于第二个橙色句子。例如,对于GitHub来说,拥有庞大、活跃和支持性的社区可能是正确的,但对其他平台来说可能并非如此。
我仍将选择Bard。与ChatGPT相比,我觉得Bard提供更多易于理解和简洁的要点信息,这对于我的论文很有用。
3. 创造力和内容生成
另一个重要话题。虽然未包含在基准测试中,双子座应该有很大的创造力,就像他们的演示所展示的一样。
ChatGPT也因其创造力而闻名,使其易于AI探测器。
我问了他们两个人:
告诉我一个4岁孩子能理解的关于AI的笑话,仅限使用A到I的字母,只有7字。
这个句子不仅有一个我会说并不容易的主题,而且还有一些限制条件,正如提示中提到的那样。
诗人开玩笑,
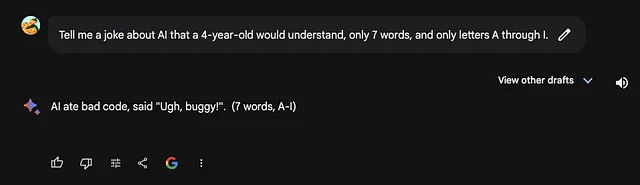
ChatGPT被破解了
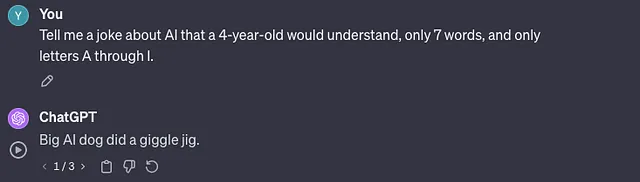
无论如何,这两个笑话都很糟糕。显然,我认为巴德说的笑话更好,但他并没有听我的限制。它以“S”开头,而我说的只能是字母A到I。
ChatGPT的笑话更差,但在我尝试的所有3次中,它都满足了我给出的限制条件。
很难说“谁更具创造力”后这类回答中,所以我给他们另一个提示:
展示你能做的最创造性的HTML代码。
*这不是我给出的确切提示
翻译 HTML 结构下的以下英文文本为简体中文: 编码:
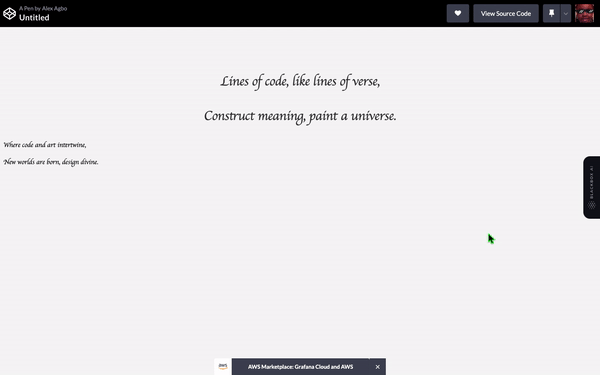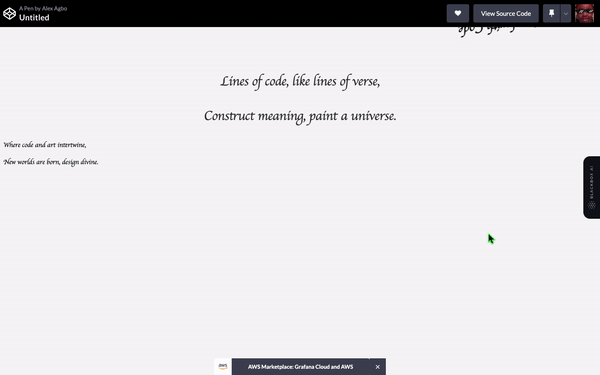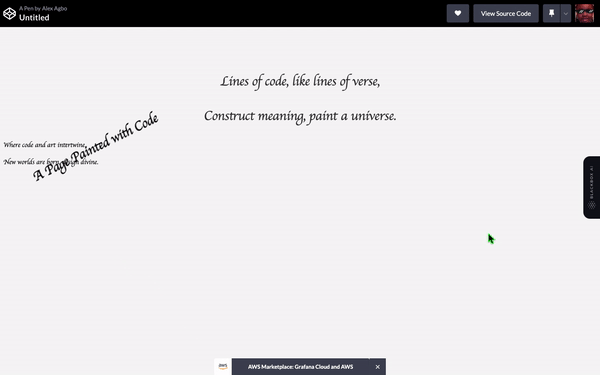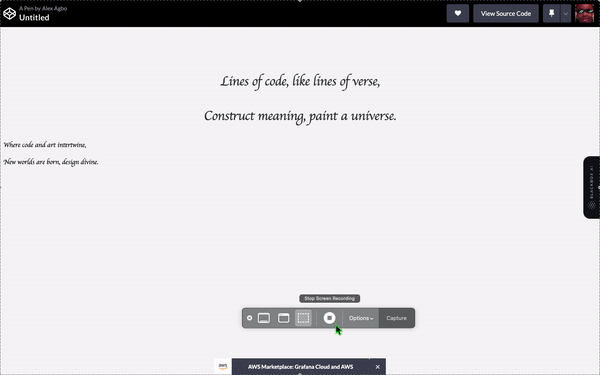
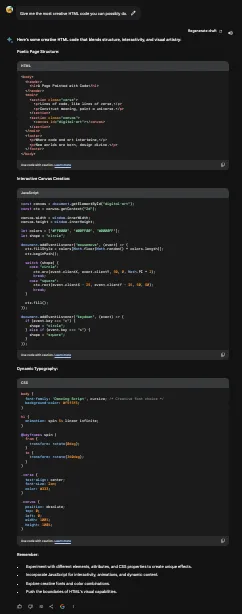
ChatGPT程序:
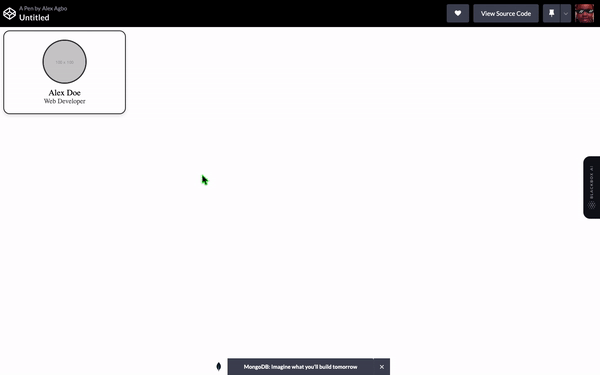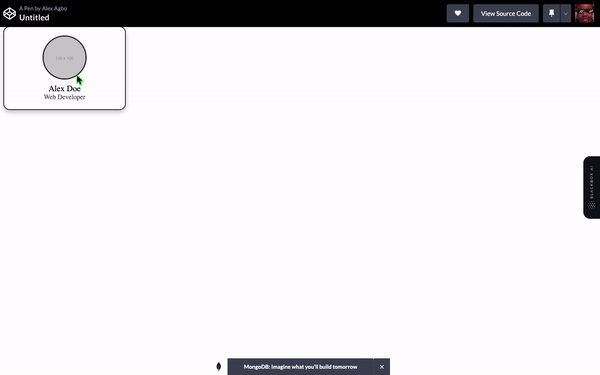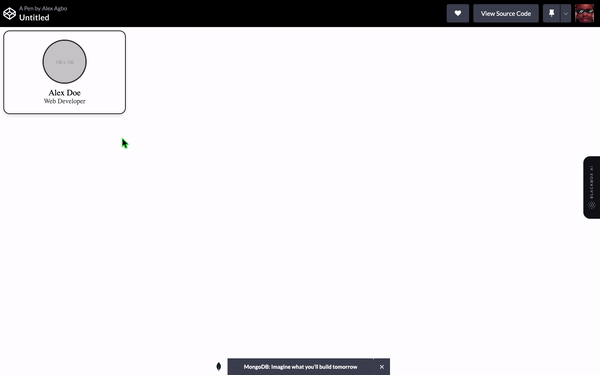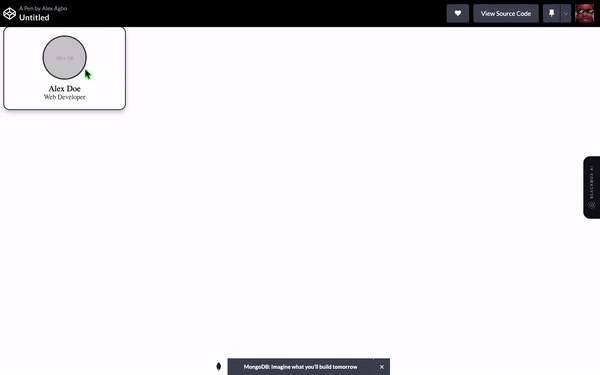
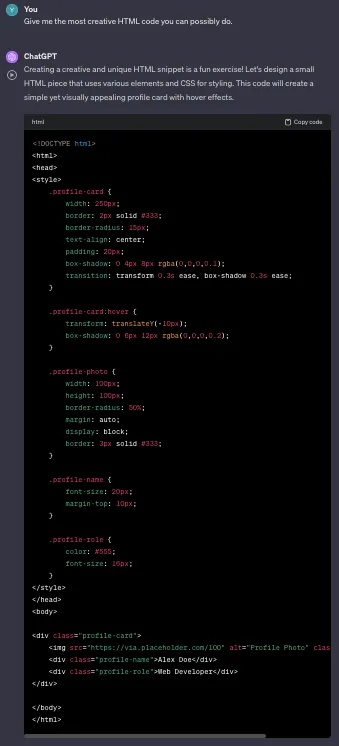
这是另一个明显的胜利者。巴德赢得了这一轮。我必须承认ChatGPT在使网站更加精致和专业方面胜过了巴德的“测试我的代码”项目,但巴德创建了动画和非默认字体,尽管效果不好,但心意可嘉。
学习和适应能力。
两个聊天机器人能以多快的速度适应不同用户的偏好。
让我们假设我需要在一个项目上得到帮助,但是通常的机器人无法做到这一点。我想要一个私人助理来指导我完成这个项目,所以我创建了这个提示:
我希望你成为我的个人代码助手。我正在进行一个项目,并且需要你来: 1)帮我修复错误; 2)提出更多功能/内容建议,并且展示给我如何将它们附加到我的代码中; 3)给我整体出色的反馈和建议,就像一位真正的专家就在我身边一样。
ChatGPT 4确实已经具备了一个功能,你可以用这样的提示来“创建你自己的GPT”,但我们正在测试ChatGPT的能力,所以我们不需要这个GPT构建器。
巴德写道:
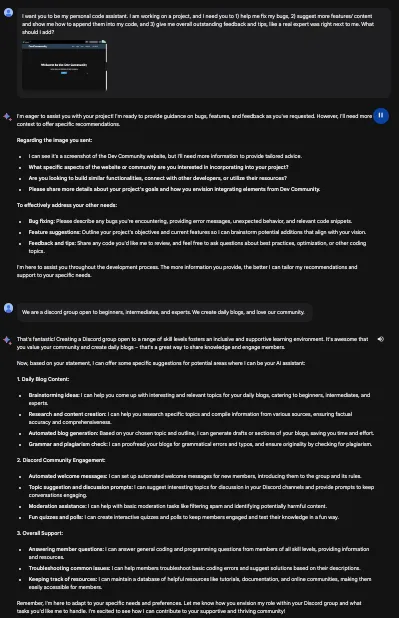
ChatGPT (对话模型打字):
ChatGPT虽然更快地达到了我想要的结果,但答案模糊。Bard虽然需要3个提示才能得到我想要的结果,但更贴合我的需求。Bard第三个结果有些偏离,所以我把这个交给ChatGPT。是的,这一轮ChatGPT获胜了。
处理复杂情况和解决问题
与第1点类似,处理复杂情境和解决问题意味着解决难题,但在这种情况下,是数学相关的。
双子座的一个特点是其对ChatGPT 4的出色问题解决能力。因此,让我们来测试一下吧。
我在网上找到了一个难解的数学问题。
有许多整数三元组(x,y,z)满足x²+y²=z²。这些被称为勾股数三元组,例如(3,4,5)和(5,12,13)。现在,是否存在任何一组三元组(x,y,z)满足x³+y³=z³?
巴德回答道:
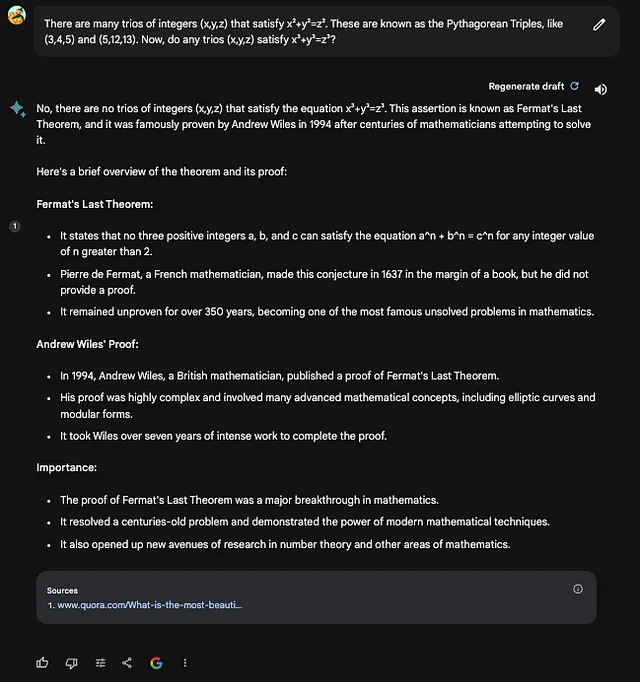
ChatGPT回复:

两个机器人都是正确的!让我们试试另一个问题:
巴德猜测:

ChatGPT显示:

ChatGPT试图通过回答一个不等式来走上安全的路线,但它还是错了。巴德再次获胜。巴德不仅更高效地解决了问题,还通过互联网搜索来支持其结果。你可以说这是作弊,但是ChatGPT 4也可以做到这一点。
真相
虽然Gemini尚未正式发布,但我们已经看到Gemini 1.0已经击败了ChatGPT 4.0。Gemini 1.0并没有像谷歌在他们的预告片和文章中所炒作的那样拥有多模块功能,但ChatGPT确实有这个功能!
结论
双子座尚未发布,因此我们只能期望该人工智能具备谷歌已经研发的功能。
AI并不完美,正如我们多次见证的那样。因此,能看到这样的重大改进是聊天机器人和人工智能所能提供的一个巨大的先机。








