多模态RAG流水线与LlamaIndex和Neo4j
检索和整合文本和图像信息,生成多模式LLMs模型的准确响应。

AI和大型语言模型领域正在迅速发展。一年前,没有人会使用语言模型来提高工作效率。如今,大多数人无法想象在没有或没有将一些次要任务交给语言模型的情况下工作。由于大量的研究和兴趣,语言模型的能力正在日益提高和增长。不仅如此,它们的理解能力也开始跨越多种形式。随着GPT-4-Vision以及后续的其他语言模型的问世,如今的语言模型似乎能够很好地处理和理解图像。以下是一个ChatGPT描述图片内容的示例。
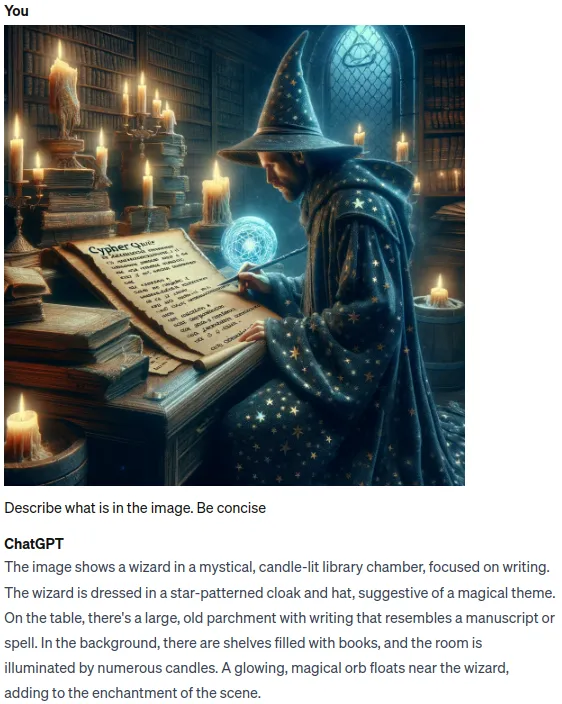
正如您可以观察到的那样,ChatGPT在理解和描述图像方面非常出色。我们可以利用其理解图像的能力来在RAG应用程序中使用,不再仅依靠文本生成准确和实时的答案,现在我们可以结合文本和图片信息来生成比以往更准确的答案。使用LlamaIndex,实施多模态RAG管道变得非常简单。受到他们的多模态食谱示例的启发,我决定尝试使用Neo4j作为数据库来实施多模态RAG应用程序。
要使用LlamaIndex实现一个多模态RAG流水线,您只需实例化两个向量存储,一个用于图像,另一个用于文本,然后查询它们以检索相关信息以生成最终答案。
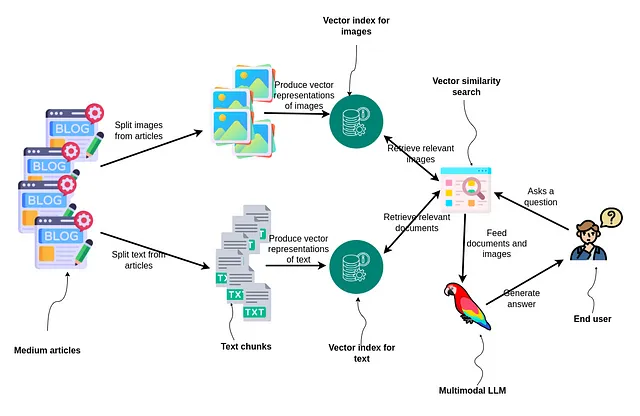
文章首先被分成图像和文本。然后,这些元素被转换为矢量表示,并分别进行索引。对于文本,我们将使用ada-002文本嵌入模型,而对于图像,我们将使用双编码器模型CLIP,该模型可以将文本和图像嵌入到同一嵌入空间中。当用户提出问题时,会进行两次矢量相似性搜索;一次用于查找相关图像,另一次用于查找文档。结果将输入到一个多模态LLM中,该模型为用户生成答案,展示了一种处理和利用混合媒体进行信息检索和响应生成的综合方法。
这段代码可以在GitHub上找到。
数据预处理
我们将使用我在2022年和2023年写的Medium文章作为一个RAG应用的基础数据集。这些文章包含有关Neo4j图数据科学库以及将Neo4j与LLM框架结合使用的广泛信息。当你从Medium下载你自己的文章时,它们以HTML格式提供。因此,我们需要使用一些编码来分别提取文本和图像。
def process_html_file(file_path):
with open(file_path, "r", encoding="utf-8") as file:
soup = BeautifulSoup(file, "html.parser")
# Find the required section
content_section = soup.find("section", {"data-field": "body", "class": "e-content"})
if not content_section:
return "Section not found."
sections = []
current_section = {"header": "", "content": "", "source": file_path.split("/")[-1]}
images = []
header_found = False
for element in content_section.find_all(recursive=True):
if element.name in ["h1", "h2", "h3", "h4"]:
if header_found and (current_section["content"].strip()):
sections.append(current_section)
current_section = {
"header": element.get_text(),
"content": "",
"source": file_path.split("/")[-1],
}
header_found = True
elif header_found:
if element.name == "pre":
current_section["content"] += f"```{element.get_text().strip()}```\n"
elif element.name == "img":
img_src = element.get("src")
img_caption = element.find_next("figcaption")
caption_text = img_caption.get_text().strip() if img_caption else ""
images.append(ImageDocument(image_url=img_src))
elif element.name in ["p", "span", "a"]:
current_section["content"] += element.get_text().strip() + "\n"
if current_section["content"].strip():
sections.append(current_section)
return images, sections
我不会详细介绍解析代码,但我们根据h1-h4标题分隔文本,并提取图像链接。然后,我们只需通过这个函数运行所有文章,提取所有相关信息。
all_documents = []
all_images = []
# Directory to search in (current working directory)
directory = os.getcwd()
# Walking through the directory
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith(".html"):
# Update the file path to be relative to the current directory
images, documents = process_html_file(os.path.join(root, file))
all_documents.extend(documents)
all_images.extend(images)
text_docs = [Document(text=el.pop("content"), metadata=el) for el in all_documents]
print(f"Text document count: {len(text_docs)}") # Text document count: 252
print(f"Image document count: {len(all_images)}") # Image document count: 328
我们获得了252个文本块和328张图片。我创造了这么多照片有点令人惊讶,但我知道其中一些只是表格结果的图片。我们可以使用视觉模型来筛选掉无关的照片,但我在这里跳过了这一步。
索引数据向量
如上所述,我们需要实例化两个矢量存储,一个用于图像,另一个用于文本。CLIP嵌入模型的维度为512,而ada-002的维度为1536。
text_store = Neo4jVectorStore(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name="text_collection",
node_label="Chunk",
embedding_dimension=1536
)
image_store = Neo4jVectorStore(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name="image_collection",
node_label="Image",
embedding_dimension=512
)
storage_context = StorageContext.from_defaults(vector_store=text_store)
现在向量存储已经初始化完成,我们使用MultiModalVectorStoreIndex索引我们拥有的所有信息的多个模态。
# Takes 10 min without GPU / 1 min with GPU on Google collab
index = MultiModalVectorStoreIndex.from_documents(
text_docs + all_images, storage_context=storage_context, image_vector_store=image_store
)
在内部,MultiModalVectorStoreIndex使用文本和图像嵌入模型来计算嵌入并在Neo4j中存储和索引结果。仅存储图像的URL,而不存储实际的base64或其他图像表示形式。
多模式RAG管道
这段代码是直接从LlamaIndex多模态菜谱复制过来的。我们首先定义一个多模态LLM和提示模板,然后将所有内容合并为一个查询引擎。
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", max_new_tokens=1500
)
qa_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_tmpl = PromptTemplate(qa_tmpl_str)
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm, text_qa_template=qa_tmpl
)
现在我们可以继续进行测试,看它的表现如何。
query_str = "How do vector RAG application work?"
response = query_engine.query(query_str)
print(response)
回应

我们还可以可视化检索获取的图像,并用来帮助提供最终答案的信息。
LLM获取了两个相同的图像作为输入,这只是展示我重用了一些图表的事实。然而,令我惊喜的是CLIP嵌入能够从集合中提取出最相关的图像。在更实际的情况下,您可能希望清理和删除重复的图像,但这超出了本文的范围。
结论
LLM的发展速度比我们历史上所习惯的要快,而且跨越了多种模态。我坚信,在明年年底之前,LLM将很快能够理解视频,并因此能够在与您交谈时捕捉非语言线索。另一方面,我们可以将图像用作输入到RAG管道,并增强传递给LLM的信息的多样性,使回答更好,更准确。使用LlamaIndex和Neo4j实现多模态的RAG管道非常简单。
代码可在GitHub上获得。








