检索辅助生成(RAG)——超级加速LLM的秘密酱料?🧐⚡️
介绍
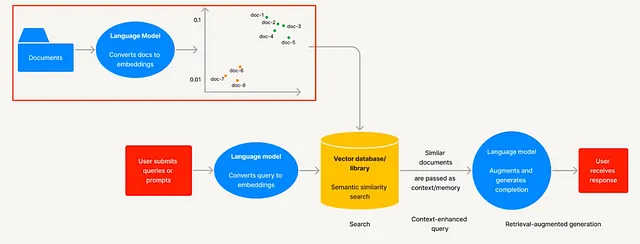
在人工智能日新月异的领域中,大型语言模型(LLMs)已经成为重要基石。然而,它们也面临着一些挑战:产生错误或荒谬信息的幻觉、知识更新滞后和推理过程缺乏透明度。检索增强生成(RAG)应运而生,它将LLMs的深度理解能力与动态的外部数据检索相结合,提供了一个更准确、更及时、更透明的人工智能模型。

什么是RAG,为什么它强大?
检索增强生成(RAG)是自然语言处理和人工智能领域中一种创新的方法,尤其是在大型语言模型(LLM)的范畴内。它有效地结合了两个主要组件:检索机制和生成机制,以增强LLM的能力。以下是它的工作原理的详细解析:
- 检索机制:RAG框架的这一部分负责从大型数据集或知识库中获取相关信息。当模型收到一个查询或提示时,检索机制会通过可用数据进行搜索,以找到与查询最相关的内容。这个过程类似于查找能够帮助制定更明智和准确回答的参考资料。
- 生成机制:一旦相关信息被检索,它就会传递给生成机制。该模型的这一部分通常是一个语言模型,类似于独立的LLM(语言模型)。生成机制使用检索到的信息构建一个回答,这个回答不仅在语境上合适,而且还包含了来自检索数据的详细信息。这使得模型能够提供更准确、详细和最新的回答。
RAG的关键优势在于能够解决传统LLM的一些限制。标准语言模型仅基于它们接受的训练数据生成回复,有时可能导致过时、不准确甚至无意义的回复(被称为“幻觉”现象)。通过整合实时数据检索,RAG模型可以提供更准确、相关和更新的信息。
在实际应用中,RAG在需要及时掌握最新信息的情景下特别有用,比如新闻聚合、研究助手和客户服务机器人。它增强了语言模型提供不仅基于训练数据,还基于最新和相关信息的能力。
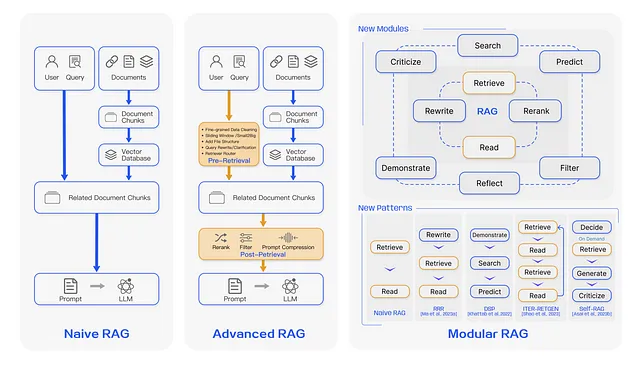
RAG的演变:从天真到模块化
RAG有三种版本:纯正版、高级版和模块化版。
- 天真的RAG是最简单的形式,其中模型从数据集中检索相关信息,然后根据这个检索生成响应。然而,它缺乏处理复杂查询所需的复杂性。
- 高级RAG通过将检索过程与生成更紧密地集成在一起,实现了更细致的理解和回应生成。
- 模块化RAG是最复杂的,提供了可自定义的模块,用于不同类型的数据和查询,使其非常适应特定的需求。
理解这些范式对于销售团队在各种用例中表达RAG的适应性和效率至关重要。
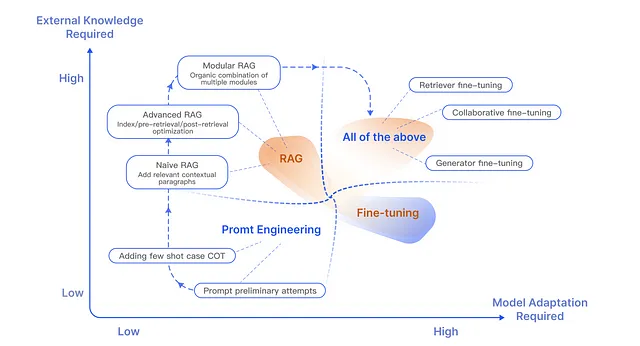
何时真正需要使用RAG?
在人工智能的动态领域中,特别是在大型语言模型(LLM)方面,理解何时采用提示工程、检索增强生成(RAG)或微调是至关重要的。这个决定在很大程度上取决于任务的具体要求,特别是考虑到对外部知识和模型适应的需求。
1. 提示工程:利用现有模型知识
- 何时使用: 当嵌入在LLM中的现有知识足以解决手头任务时,提示工程是最有效的方法。该方法非常适用于模型已经训练过相关数据,只需要指导来有效地提取和呈现信息的情况。
- 应用场景:它在创意写作、生成一般信息或任务涉及到标准查询并且模型可能已经根据其训练数据熟悉的情况下特别有用。
- 优点:这种方法成本低廉且快速,不需要额外的培训或外部数据源。
2. 检索增强生成(RAG):整合外部知识
- 何时使用:当任务需要的信息不包含在模型的原始训练数据中,或者最新信息是至关重要的时候,可以使用RAG。它非常适用于那些准确性和相关性取决于最新数据或模型可能没有训练到的特定知识的情况。
- 应用情景:这种方法在回答当前事件问题、医学或法律等领域的专业查询,或需要详细、具体信息时非常有益。
- 优点:RAG提供了一种在不需要持续重新训练的情况下,保持模型长期相关性的方法。它使模型能够访问广泛的外部数据源,确保回答是时事和详细的。
3. 微调:根据特定需求调整模型
- 何时使用:微调是一种选择的方法,当模型需要适应其原始训练中未充分涵盖的特定领域、语言或样式时。当模型在其预期应用中遇到的数据与其最初训练的数据类型有重大转变时,这一点尤为重要。
- 应用场景:对于需要深入领域专业知识的任务,如法律咨询、技术支持或在小众领域进行深度分析,至关重要。
- 优势:通过精细调整,可以使模型更加贴合特定任务的要求,从而在专门的任务上显著提高性能。
做出正确的选择
这些方法之间的选择取决于:
- 任务性质:了解任务是否需要常规知识(工程加工)、最新/具体信息(RAG),或领域特定的调整(微调)。
- 资源可用性:考虑可用资源,包括时间、计算能力和数据。及时工程需要较少的资源,而RAG和精调需要更多的资源。
- 模型当前的知识:评估LLM当前的知识和能力。如果与任务契合度高,可以选择快速工程。否则,考虑使用RAG或微调技术。
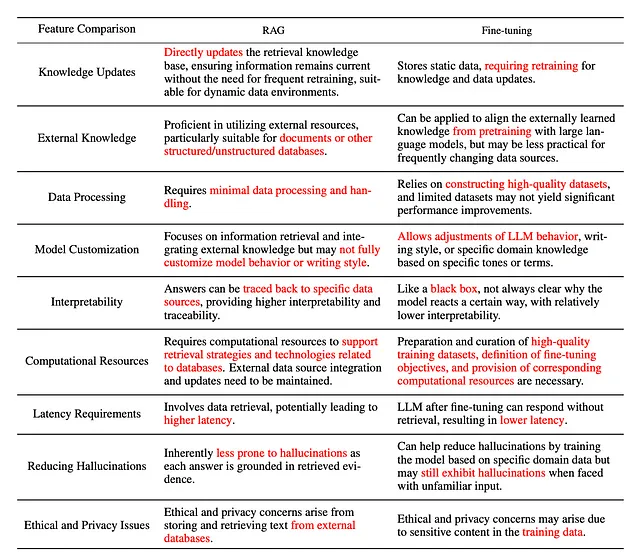
测量RAG的强大程度:评估方法和指标
评估检索辅助生成(RAG)系统的效果是确保其在实际应用中的可靠性和实用性的关键方面。了解用于此目的的各种方法和指标对于希望在工作流程中采用RAG的团队来说是必要的。以下是对测量RAG系统性能的关键方法和指标的详细介绍。
1. 评估方法
独立评估
- 这种方法涉及分别评估检索和生成组件的性能。
- 对于检索组件,评估关注的是对查询的响应中检索到的信息的相关性和准确性。常见的度量指标包括精确度(Precision)、召回率(Recall)和F1值(F1-Score)。
- 对于生成组件,评估通常涉及对所生成文本的相关性、流畅性和连贯性进行评估。这时会使用一些度量指标,如BLEU(双语评估助手)和ROUGE(面向摘要评估的召回导向助手)。
端到端评估
该方法将RAG系统作为一个整体进行评估,考虑到检索和生成组件如何协同工作以产生准确和相关的回答。
人类评价:
涉及人工评委根据准确性、相关性和信息量评估回答的质量。
自动评估
使用诸如BLEU、ROUGE和METEOR(用于评估具有明确排序的翻译质量的指标)的指标来评估生成文本的整体质量。
2. RAG评估的关键指标
- 准确性:衡量RAG系统提供正确信息的频率。在强调事实正确性的应用中至关重要。
- 相关性:评估所检索的信息和生成的回答与查询的相关性。高相关性对用户满意度和系统效果至关重要。
- 流畅性:评估生成文本的可读性和连贯性。对于确保响应易于被最终用户理解而言至关重要。
- 时效性:在需要更新信息的应用程序中至关重要。它衡量了RAG系统提供的信息的当前性。
- 多样性:评估RAG系统产生的回答多样性。该指标对于避免重复或普通的回答非常重要。
RAG的未来:拓展视野
未来的RAG的发展既包括垂直优化(改进模型的特定方面),也包括水平扩展(将模型应用于各种任务)。这种多功能性对于AI生态系统非常重要,因为它使RAG能够适应各种行业和用例,从客户服务到内容创作。检索增强生成(RAG)的未来似乎是一个充满广泛创新和整合的领域,能够显著提升自然语言处理系统的能力。RAG发展的主要方向之一是与日益多样化和动态化数据源的更深度整合。这种整合将使RAG系统能够提供更准确和与上下文相关的回答,尤其是在快速变化的领域,如新闻、科学研究和社交媒体趋势。另一个前景广阔的方向是开发更复杂的检索机制,能够更有效地理解和处理复杂的查询。此外,RAG还可以定制为特定行业,如医疗保健或法律,其中准确性和最新信息至关重要。在技术方面,机器学习算法和计算能力的进步将使RAG系统变得更高效和可扩展,能够轻松处理更大的数据集和更复杂的模型。此外,随着AI伦理和透明度变得越来越重要,RAG系统可能会纳入解释其检索和生成过程的机制,增强信任和可靠性。RAG与其他AI技术的整合,如预测分析和自动化决策系统,可能会开辟新的应用领域,使RAG成为下一代AI解决方案的核心技术。RAG的未来不仅仅是关于技术进步,还涉及创建更符合人类需求、理解和道德考虑的AI系统。
🔖🤓 喜欢这个吗?想要阅读更多吗📚👓
如果你来自一个初创公司或产品公司,你可能会喜欢探索我其他喜爱的文章:
- Gen AI快读#1:软件工程的未来以及CEO可以做些什么来做好准备
- 建立对大型语言模型(LLM)的基本直觉
- 导航技术债务的昂贵迷宫
- 🚀 产品驱动增长 Vs 🤝 销售驱动增长,适用于B2B SaaS产品
- 如何为您的产品用户创造“啊哈!时刻”。
随时欢迎您提供反馈意见或者通过LinkedIn与我联系








