3个理由说明生成式人工智能可以像二手车销售员一样

随着生成式人工智能的发展,我们正在以惊人的步伐创造出可以模仿人类行为的机器。然而,就像一个口若悬河的二手车销售员一样,这些人工智能模型经常有一些怪癖和幻觉,让我们质疑它们的可信度。让我们深入探讨这些奇特特征背后的技术原因,并探索微软的Autogen多代理模型等新兴解决方案。
1. 话多但不一定准确的口才之礼
很像一个能够对你讲个没完的二手车销售员一样,生成式人工智能模型可以产生令人印象深刻且啰嗦的内容。然而,这些信息的质量可能会存在问题。以下的三毛巾问题就可以作为一个例子:
“If it takes 3 towels 3 hours to dry on a clothesline how long will it take 9 towels to dry?” 假如三条毛巾在晾衣绳上需要三个小时才能干透,那么九条毛巾需要多长时间才能干透?
现在,如果你曾经用过绳索晾衣物,答案应该是不言而喻且简明扼要的:只要绳索上有空间,无论你有3条还是9条毛巾,它们都会在同一时间干燥。
让我们看看ChatGPT说了什么。
晾晒毛巾的干燥时间可能取决于各种因素,如天气、湿度和风力。然而,如果我们假设所有毛巾的条件相似,你可以使用一个简单的比例来估计9条毛巾干燥所需的时间。
3条毛巾 = 3小时 9条毛巾 = x小时(我们想要找到的)
你可以按照以下方式设置比例:
(3块毛巾/3小时)=(9块毛巾/x小时)
现在,进行交叉相乘并解出x:
3x = 27 3x = 27
将两边都除以3:
x = 9
所以,在类似条件下,大约需要9个小时才能使9条毛巾变干。请记住这只是一个简化的估计,实际的干燥时间可能会有所不同。
哇,即使是我们中成绩优秀的数学课程学生,这个答案可能也会给他们留下深刻的印象。它详细、解释得很好,甚至附带了一个公式来佐证。但是有个问题:它完全是错误的。那么,真正的故事是什么?

技术洞见:语言模型和幻象
一个最具吸引力却又误导的生成式人工智能模型的特点之一就是它们对文本的理解似乎是存在的。很容易认为这些模型确实“理解”它们所阅读或生成的内容,但实际情况要简单得多。从本质上说,这些模型只是将概率用于预测序列中的下一个词,其实它们只是被训练于庞大的数据集,并使用复杂的算法,但它们的“理解”仅仅是数学计算的副产品。这些模型会分析单词之间的上下文关系以及它们可能的后续词,这是基于它们所训练的数据。它们无法像人类一样理解意义、上下文或细微差别(例如:晾衣绳);它们只是简单地通过概率玩“填空”游戏。在这种情况下,缺少的理解是晾衣绳实际上如何促进干燥。真正理解的缺乏是生成式人工智能可能会产生冗长而空洞,甚至完全错误的产出的一个关键因素,就像一个狡猾的二手车销售员做出的承诺一样。
2. 幻术大师: 令人信服但具有误导性
一个二手车销售员知道如何把一辆瑕疵车伪装成宝藏。同样地,AI模型可以产生看似令人信服但最终具有误导性的结果。在一个引人注目的例子中,突显了生成式AI在专业环境中潜在的危害。请考虑罗伯托·马塔与哥伦比亚航空公司之间的法律纠纷案。马塔的律师团队由史蒂文·施瓦茨领导,他们使用ChatGPT进行法律研究以准备法庭文件。然而,ChatGPT却向他们保证存在一些判例,后来发现这些判例完全是虚构的。马塔的律师引用了至少六个其他案例来证明判例的存在,包括Varghese诉中国南方航空公司案和Shaboon诉埃及航空公司案。但是,法院发现这些案例并不存在,而且存在着“虚假的司法决定,包括虚假引用和虚假内部引文”。这些“虚假的司法决定”导致了一种可能会损害职业生涯的情况,引发了联邦制裁,并对在法律实践中使用AI的道德和可靠性提出了质疑。
技术洞察:黑匣子问题
复杂的神经网络结构使得很难理解为什么会生成特定的输出,这种现象常被称为“黑匣子”问题。虽然这些模型可以以非凡的准确性执行任务,但理解它们如何得出具体决策或输出是一项复杂的努力。这种缺乏透明度引发了重大的伦理和实际关切,尤其是在医疗、金融和法律等高风险领域。在这种情况下,ChatGPT不仅理解法律案例的概念,还知道其结构,包括引用和格式。因此,它轻而易举地创建了看似合法的伪造案例文件,甚至能够欺骗经验丰富的律师,直到有人真正试图在法律数据库中查询这些案例。这带来了一个挑战:当出现这样的错误时,改进模型并使其承担责任变得困难。人工智能的黑匣子特性不仅削弱了我们完全信任这些系统的能力,也成为监管合规和人工智能在敏感领域广泛应用的障碍。
3. 个性化但不具人情味
无论是二手车销售人员还是人工智能模型,都希望提供个性化的体验,但往往感觉虚伪并缺乏真正的人性化触感。先进的聊天机器人和客户服务人工智能尽力模仿认知共情。它们被编程以识别暗示用户情感状态的关键词或短语,并根据此生成回复。例如,如果用户输入“我感到沮丧”,人工智能可能回答,“很遗憾听到你有这样的感受。我能如何帮助你?”虽然这给人一种理解的印象,但与真正的情感连结相去甚远。
技术洞察:为何人工智能在临床同理心方面不足
生成式AI模型往往具有预定义的个性,使得它们的交互感觉被剧本化,不够真实。虽然研究正改进这一方面,但人工智能离真正的临床同理心还有很大差距。真正的临床同理心通常需要一种共同的经历,而这是AI无法模拟的。想象一下像戒酒无名会这样的支持团体,成员们以酗酒者的身份互相介绍,以建立共同的基础。这种共同的经历是真正同理心和支持的基石,远远超出了即使是最先进的人工智能的能力范围。
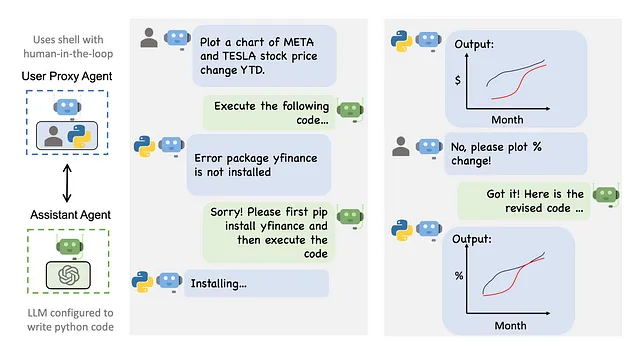
地平线上的解决方案
AI社区正在努力寻找解决这些挑战的方案。一个有希望的发展是微软的Autogen多代理模型,它与传统的生成式人工智能不同。Autogen使用专门的代理,每个代理都有独特的角色,比如作者、编辑、开发者和质量保证测试员。这些代理与合作,创建了一个"审查和平衡"系统,旨在产生更准确可靠的结果。例如,一个"作者"代理可以生成内容,而一个"编辑"代理可以确保其准确性,从而降低产生幻觉的可能性。
随着人工智能的日益复杂,我们必须做好准备,面对这项技术中不可避免的怪癖和错觉。虽然像自动生成(Autogen)这样的进展为我们展示了一个更可靠的未来,但旅程还远未结束。所以,如果你觉得自己好像正在与人工智能版的二手车销售员讨价还价,也别太惊讶。