LLM的崛起和发展
一个快速的学习
什么是大型语言模型?
大型语言模型(LLMs)是先进的深度学习模型,具有理解、翻译、生成和分类基于大量真实世界文本数据的能力。在LLMs中,“大型”一词包含三个主要维度。首先,它指的是参数的庞大数量,在模型的训练过程中进行了精细调整的内部值。其次,它涉及到这些模型所依赖的训练数据的广阔性。最后,它包含了训练和有效运行这些模型所需的大量计算资源。丰富的计算能力的提供使得在可行的时间范围内开发出具有庞大数据集和参数的模型成为可能。
基本上,几年前摩尔定律使我们达到了一个临界点,从而使LLM成为可能,现在有一种新的摩尔定律等效,其中更多的数据和参数导致更好的语言模型。
那么我们讨论的是多大的规模?
严重庞大!ChatGPT所依赖的GPT-3.5模型使用了1750亿个参数,需要800GB的存储空间。该模型至少使用了75TB的文本数据进行训练,每台服务器据说配备了8个高端的Nvidia A100 GPU。但是它们甚至可能更庞大,例如,谷歌的PaLM模型拥有5400亿个参数,而WuDao 2.0据说拥有1.75万亿个参数。
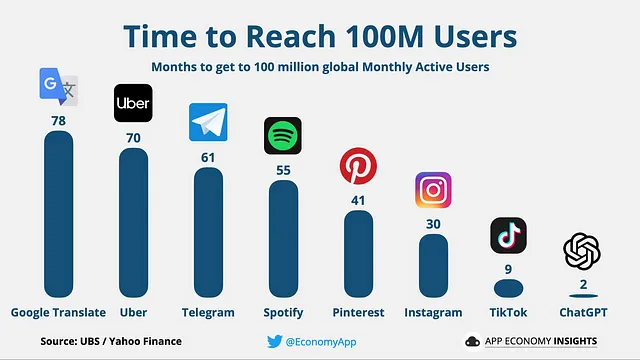
你可以通过下面的图表来想象这些LLM的流行程度,该图表显示达到1亿用户的时间。
让我们深入探讨“LM/LLMs的起源”历史。
这个故事始于 2013 年,由谷歌发布的非常有名的论文《Efficient Estimation of Word Representations in Vector Space》引发,该论文被称为 Word2vec 嵌入,团队在其中介绍了两个新的自然语言处理模型。
Word2Vec-2013
Word2Vec摘要:作者介绍了两种创新的模型架构,即Skip-gram和CBOW,旨在从大规模数据集中生成连续向量表示的词语。通过词语相似性任务评估了这些表示的有效性,并将其性能与依赖于各种神经网络类型的现有技术进行了比较。值得注意的是,作者注意到在准确性方面取得了显著的改进,同时需要较少的计算资源。举例来说,从包含16亿个单词的数据集中获取高质量的词向量的过程现在只需要不到一天的时间。此外,作者还证明了当应用于我们的评估集以评估语法和语义词语相似性时,这些向量能够达到最先进的结果。
在所提到的论文中,作者概述了两个重要方面:包括16亿个单词的庞大训练数据集以及他们对语义词相似性评估的关注。
在“论文目标”标题下,作者阐述了他们的主要目标。他们的首要目标是引入能够从包含数十亿单词、包含数百万个独特词汇的广泛数据集中学习高质量词向量的新方法。他们采用了最近提出的技术来评估所得到的向量表示的质量。他们的期望超越了仅仅相似词之间的近邻关系;他们的目标是证明词汇可以展示不同程度的相似性。
值得注意的是,另一篇相关的论文《词语和短语的分布式表示及其组成性》可能为所讨论论文中提出的工作提供了宝贵的见解或作为参考。
经过一段时间,一个新的英雄出现在舞台上。
2. GloVe:全局词向量表示法- 2013
摘要:最近在学习词向量表示方面的进展在通过向量算法捕捉复杂的语义和句法模式方面取得成功。然而,这些模式背后的基本机制仍然有些模糊不清。作者为了阐明词向量内部出现这种规律性的模式所需的模型特性进行了彻底的分析。
他们调查的结果最终得出了一种新颖的全局对数双线性回归模型。这个模型有效地结合了该领域中两个主要模型族群的优势:全局矩阵分解和局部上下文窗口方法。他们的模型的一个关键优势在于其对统计信息的高效利用。它不是基于整个稀疏矩阵或广阔语料库中的个别上下文窗口进行训练,而是仅关注单词-单词共现矩阵中的非零元素。
作为结果,该模型生成了一个展示有意义子结构的向量空间,其在最近的一个词类比任务中取得了令人印象深刻的75%性能。此外,它在相似性任务和命名实体识别方面超越了可比较模型的性能,验证了其在各种自然语言处理应用中的有效性和实用性。
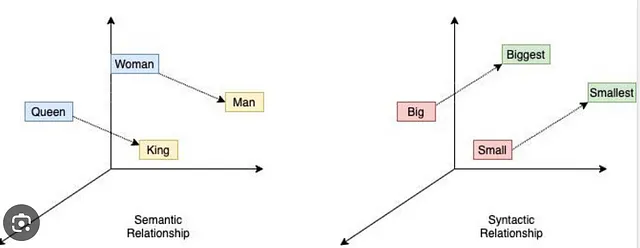
并且这里就来了一个著名的例子——比如类比:“国王对应皇后,就像男人对应女人”应通过向量方程国王 - 皇后 = 男人 - 女人 在向量空间中进行编码。
3. ELMO:深度上下文化的词表示-2018
获得最佳论文奖
摘要:作者们介绍了一种新颖的深度上下文化词表示形式,能够捕捉词语使用的复杂方面,例如语法和语义,以及这些用法在不同语言环境中的变化,解决了多义性问题。这些词向量本质上是从深度双向语言模型(biLM)的内部状态中学习到的函数,最初在大规模文本语料库上进行预训练。
这些上下文化的词表示可以与现有模型无缝集成,证明在各种具有挑战性的自然语言处理(NLP)任务中性能显著提升。这些任务包括问答、文本蕴涵、情感分析等等,为NLP领域的最新技术设定了更高的标杆。
此外,作者们提出了一个关键的分析,强调了揭示预训练网络的深层内部结构的重要性。这种揭示使得下游模型能够有效地融合各种形式的半监督信号,最终有助于模型在多样的自然语言处理问题上取得卓越的性能。

这里是我们的NLP版托尼·斯塔克
截止目前已有90020次引用。 "注意力就是你所需的一切"。
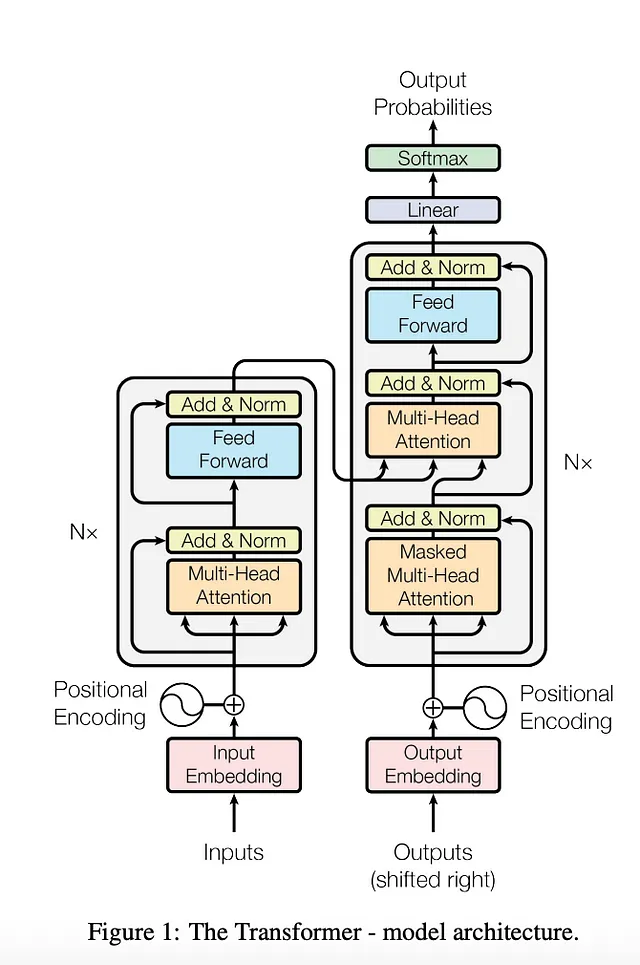
变形金刚- 2017
摘要:目前的序列转换模型依赖于复杂的循环神经网络或卷积神经网络,其中包括编码器和解码器。最有效的模型还融入了注意机制,以连接这些编码器和解码器组件。与此相反,作者们引入了一种称为Transformer的新颖且简化的网络架构。这种创新方法完全基于注意机制,消除了对循环和卷积层的需求。
通过对两个机器翻译任务进行严格的实验,Transformer模型展现出了优越的翻译质量。值得注意的是,它们具有增强的并行能力和显著降低的训练时间的优势。例如,在WMT 2014英德翻译任务中,该模型达到了28.4的BLEU分数,超过了之前最好结果,甚至超过了集合模型的结果2个BLEU点以上。同样,在WMT 2014英法翻译任务中,Transformer模型在仅使用8个GPU进行3.5天的训练后,取得了新的单模型最先进BLEU分数,达到了41.8。这只是现有文献中最佳模型所需训练成本的一部分。
此外,作者的研究结果表明了Transformer卓越的泛化能力,在其他任务上也取得了成功。它已经成功应用于英语短语结构解析,即使在训练数据有限的情况下,也能展现出强大的性能。
培训
本节概述了用于模型的训练过程。
训练数据和分批处理:模型在标准的 WMT 2014 英德数据集上进行训练,该数据集包含大约 450 万个句子对。这些句子使用字节对编码进行了编码,从而得到了一个包含大约 37,000 个标记的共享源-目标词汇表。对于英法数据集,使用了数量较大的 WMT 2014 英法数据集,包含 3600 万个句子。在这种情况下,标记被分割成了一个包含 32,000 个词片段的词汇表。
在训练过程中,句子对根据近似的序列长度被分成批次。每个训练批次包含一组句子对,大约总计有25,000个源语言标记和25,000个目标语言标记。这种分批策略有效地促进了训练过程。
硬件和日程安排
模型是在一台配备8块NVIDIA P100 GPU的单机上进行训练的。对于基准模型,其使用了论文中详细的超参数,每个训练步骤大约需要0.4秒的时间。这些基准模型的训练过程总共包含了100,000个步骤,总计训练时间为12小时。
对于较大的模型,步骤时间延长到1.0秒。因此,大模型的训练时间也更长,需要300,000个步骤,相当于连续训练约3.5天的时间。训练时间和步骤持续时间的变化反映了模型大小和复杂度之间的差异。
下一个英雄获得了78483次引用和最佳论文奖项。
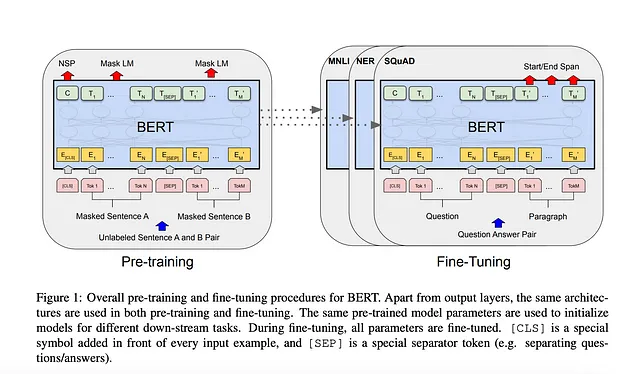
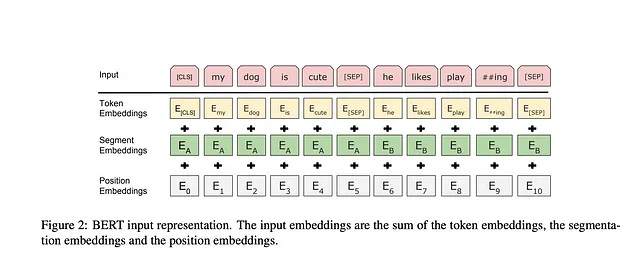
BERT: 深度双向Transformer的语言理解预训练-2018
摘要:
作者们引入了一种开创性的语言表示模型,被称为BERT,即来自Transformer的双向编码表示。与最近的语言模型(如Peters等人,2018a和Radford等人,2018)相比,BERT的独特设计在于从无标签文本中预训练深度双向表示。BERT通过同时考虑所有层中的左侧和右侧上下文来实现这一目标。
这种创新方法使得预训练的BERT模型可以通过仅添加一个额外的输出层进行微调,让它在包括问题回答和语言推理在内的各种任务中表现出色,而无需进行大规模的任务特定架构修改。BERT的概念简单性与其显著的实际表现相匹配。
BERT在十一个不同的自然语言处理任务中取得了新的最先进的结果。值得注意的成就包括将GLUE得分推到80.5%,相比之前大幅提高了7.7%。此外,BERT显著提高了MultiNLI的准确性到86.7%,相对之前有了显著的4.6%的提高。在问答领域,BERT将SQuAD v1.1测试F1值提升到了93.2,相对之前提高了1.5个百分点,同时将SQuAD v2.0测试F1值提升到了83.1,相对之前提高了惊人的5.1个百分点。这些结果突显了BERT在推动自然语言处理领域方面的巨大能力和多功能性。
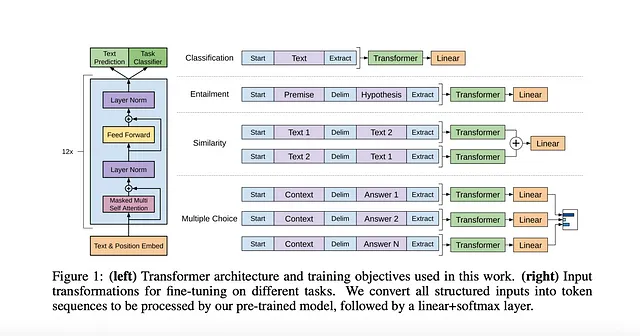
GPT-改进生成式预训练提高语言理解能力-2018
摘要:
自然语言理解领域涵盖了各种各样的任务,包括文本蕴涵、问题回答、语义相似度评估和文档分类。虽然我们可以访问大量的无标签文本数据,但获取这些特定任务的标签数据往往是一项挑战,使得辨别训练模型难以有效地执行。
针对这一挑战,作者们展示了一种极其有效的方法,对这些任务取得了显著的改进。他们的方法首先将语言模型置于多样化未标记文本语料库的生成预训练之下,然后针对每个具体任务进行有差别地微调,其所采用的任务感知输入转换是与以往方法有所不同之处,通过对模型架构进行最小程度的更改实现了鲁棒的迁移学习。
这种方法的有效性已经在自然语言理解的广泛基准中得到证明。他们的通用模型始终胜过针对每个任务明确设计的辨别式训练模型。值得注意的是,这种方法在12个任务中的9个任务中显著地推进了最新技术水平。例如,作者在常识推理(故事填空测试)中取得了显着的8.9%的绝对改进,在问题回答(RACE)中取得了5.7%的改进,在文本蕴涵(MultiNLI)中取得了1.5%的改进,突出了他们的方法所取得的令人印象深刻的性能提升。
GPT-3:语言模型是少样本学习器 2020。
摘要:
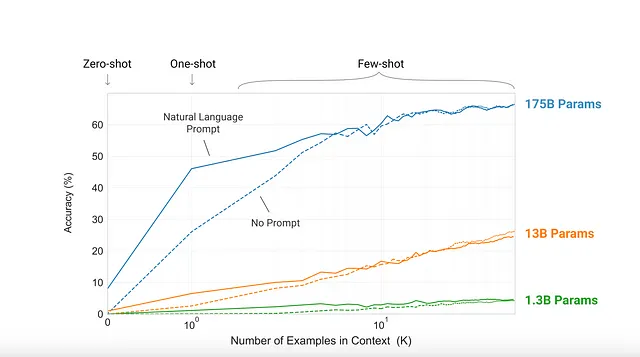
最近自然语言处理(NLP)的进展表明,通过采用两步方法:在大规模文本语料库上进行预训练,然后在特定任务上进行微调,可以在各种任务和基准测试中取得显著的改进。尽管这些模型通常不依赖于特定的架构,但它们仍需要大量的任务特定微调数据集,包含数千甚至数万个示例。相比之下,人类通常可以在只有几个示例或简单指示的情况下执行新的语言任务,而当前的NLP系统难以复制这种能力。
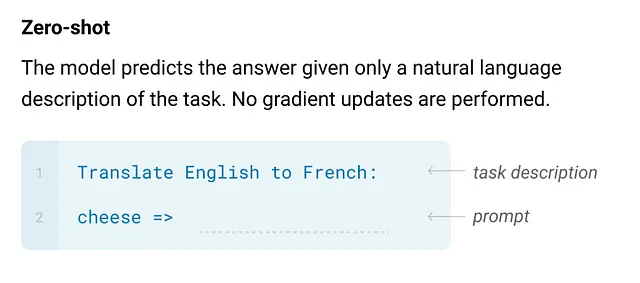
在这项研究中,作者们证明通过增加语言模型的规模可以显著提高无特定任务的少样本性能。在某些情况下,这些模型甚至可以接近或达到先前最先进的微调方法的竞争水平。具体来说,他们训练了GPT-3,这是一个拥有1750亿参数的自回归语言模型,比任何先前的非稀疏语言模型都多十倍。他们在少样本学习环境中评估了GPT-3的性能,这意味着模型在没有任何梯度更新或微调的情况下应用于各种任务。这些任务和少样本演示仅通过与模型的文本交互来指定。
值得一提的是,GPT-3在广泛的自然语言处理数据集上取得了出色的表现,包括翻译、问答、填空任务等。它在需要即时推理或领域适应的任务中表现出色,例如解开单词的乱序,使用新词造句,或进行三位数的算术运算。然而,作者们也发现了一些数据集,GPT-3的少样本学习仍面临挑战,并且由于该模型在大量网络文本上训练,一些数据集出现了方法论问题。
此外,GPT-3表现出生成文本样本的能力,例如新闻文章,这些样本很难被人类评估者与人类撰写的文章区分开来。这一发现引发了对GPT-3及类似模型对社会影响的重要考虑。
本论文提出了三种情境学习的设置。



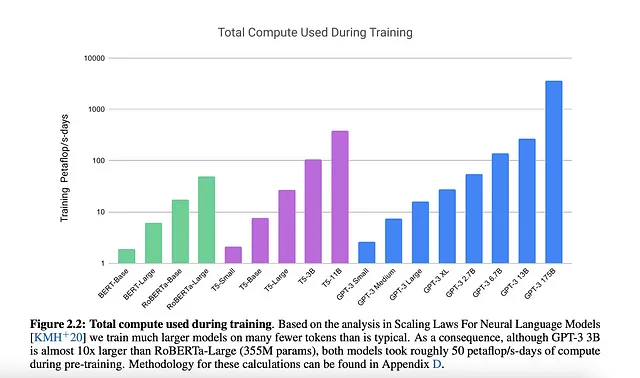
现在让我们来看看模型大小随时间的趋势。

现在有很多开源模型,例如
弗兰 T5/XL/XXL
LLaMA (简化汉字: 羊驼)
猎鹰
这里是Huggingface排行榜链接,你可以查看 https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
额外的内容:
在YouTube上找到斯坦福大学XCS224U视频。
UMass CS685 S23(高级自然语言处理)在Youtube上有视频。
菲尔施密德博客
快乐学习!