从理论到代码:深入理解机器学习中的变压器
引言
我非常清楚有很多资源涵盖了Transformer。你可以找到指南讨论研究论文中的重大突破,有些则讲解复杂的数学迷宫,还有一些详细剖析编码方面的内容。但是,有一点需要注意——很多资源都是孤立地讲解这些方面,很难把整个画面完整地呈现出来。
我的指南与众不同。我们将从根源开始,深入探究关键研究论文中呈现的核心概念。在此基础上,我将帮助您以一种清晰的方式解开数学问题,而不仅仅是抽象的方程式。然后,为了归纳概念,我们将深入编写相关代码。
把这个看作你的一站式旅程,连接基础理念和实际编码的点点滴滴。我保证,在整个指南中,你总能感觉到每一个步骤之间的潜在联系。
设置期望(重要免责声明)
不要期望对变压器的每个方面进行详尽深入的探索。相反,把这视为你入门的起点,为你在掌握这一主题的下一步做好基础准备。它的关键在于以清晰、逻辑的方式连接各个要点,以便在深入研究或探索更多资源时,一切都能水乳交融。
先决知识
在我们开始之前,这是我希望你熟悉的内容:
- 神经网络:基础知识,如层和神经元。
- 反向传播:这是我们训练这些网络的方法。
- 一些Pytorch:我们将在示例中使用它。
Transformer架构的概念在2017年的NIPS会议上推出的具有开创性的论文“关注力就是一切”。在该论文的摘要中,明确提到:
我们提出了一种新的简单网络架构,名为Transformer,完全基于注意力机制,完全不涉及循环和卷积。《注意力就是你所需的》,NIPS 2017。
从这个引用中,出现了两个关键的要点。
- 要了解Transformers如何工作,我们需要理解这个“attention”的概念。
- 该论文还提到,传统方法(如循环和卷积)存在一些限制,而注意力机制有助于解决这些限制。
我们将从第二点开始,尽管我们不会深入探讨。我们的目标是澄清并提供学习注意机制的动机,接下来我们将讨论,并随后了解变形金刚如何运作。
"旧"方法(递归和卷积)有什么问题?
截至2023年,我们可能认为循环神经网络(RNN)和长短期记忆(LSTM)是Transformer解决的问题的老派方法。然而,当“注意力全你所需”的论文在NIPS 2017发布时,这些方法是序列建模和传导问题的最先进解决方案——而Transformer正是在解决这些问题。但是,等等,究竟什么是序列建模和传导问题呢?
序列建模:这是一种问题类型,其目标是预测序列中的下一个项目。示例:给定股价为$100、$101、$102,预测下一个可能是$103。
转导问题:转导是指将一个序列转换成另一个序列。一个经典的例子是机器翻译,即将英语句子转译为其对应的法语句子。
使用 HTML 结构,将以下英文文本翻译为简体中文: RNNs 和 LSTMs 的问题
回到我们的RNN和LSTM,以了解它们的限制,下面是论文中的一句引语:
它们通过以前的隐藏状态h(t-1)和位置t的输入作为函数,生成一系列隐藏状态h(t)。这种内在的顺序性质使得在训练样例中无法进行并行化处理,而在较长的序列长度时,这一点变得至关重要,因为内存限制限制了跨样例的批处理。《注意力机制是你所需要的》,NIPS 2017
哇,这真让人咂舌!但简而言之,这告诉我们RNN和LSTM是逐步进行工作的。对于每个新的输入片段,它们会考虑先前步骤的结果。由于它们以这种方式操作,你不能一次处理输入的多个部分。这种逐步的方法会拖慢处理速度,特别是在处理更长的序列时。此外,当序列很长时,由于内存限制,你不能轻易地同时处理很多序列。所以,这主要涉及序列长度和并行处理!
我喜欢将循环神经网络(RNN)阅读书籍(或任何序列)的方式比作逐步阅读单词或句子的方式。RNN从书的第一个单词开始。对于这个第一个单词,它生成一个内部注释(隐藏状态),总结到目前为止“理解”了什么。移动到第二个单词时,RNN同时考虑了这个新单词和之前为第一个单词创建的注释(隐藏状态)。然后,根据这些结合信息,更新其内部注释。RNN继续这个过程,每次阅读一个单词,总是考虑最近的注释(隐藏状态)以及新单词来更新其理解。
这就是记忆问题产生的地方!这是由于循环神经网络(RNNs)的运行方式和计算硬件的实际限制导致的。让我们来分解一下:
- 长序列:如果书(序列)非常长,循环神经网络(RNN)的内部记忆(隐藏状态)需要包含所有先前的信息。对于非常长的序列,保留和管理所有过去细节对于RNN变得具有挑战性。
- 通过时间的反向传播(BPTT):在训练过程中,为了让RNN学习并调整其权重,我们使用BPTT。这个过程需要通过序列的每个元素重新追溯我们的步骤,根据模型的错误来更新权重。序列越长,需要追溯的步骤就越多,这意味着需要更多的计算和内存使用。就像需要更大的空间来存储每个任务步骤的详细信息以供以后查看。
- 批处理:为了提高训练效率,我们通常会一次处理多个序列(批处理)。如果每个序列都很长,并且我们同时尝试处理多个序列,内存使用量就会成倍增加。论文中的引用特别提到了“内存限制限制了跨示例的批处理”。这意味着在处理长序列时,由于内存限制,你无法将过多的序列一起进行批处理,从而减慢了训练过程的速度。
- 梯度消失和爆炸问题:当我们使用BPTT训练一个RNN时,我们计算网络中每个权重相对于误差的变化(这就是梯度告诉我们的内容)。我们利用这些信息来更新权重,使我们的模型变得更好。当序列很长时,这些梯度可能会变得非常小(消失)或非常大(爆炸),因为它们向后沿着序列传播。如果梯度消失,权重不会被更新太多,网络无法学习长距离的依赖关系。这意味着RNN会忘记它在几个步骤前看到的内容。如果梯度爆炸,权重可能会被过于激进地更新,导致学习的不稳定性。
自注意力(暂时忘记变形金刚)
现在,让我们揭开变形金刚的骨干 - 自注意力!而且不仅仅是骨干,可以说它是变形金刚的精髓都不为过。毕竟,论文的标题就是“你只需要关注”!但自注意力并不完全等同于变形金刚!然而,变形金刚作为一个模型完全依赖于自注意力。
据我们所知,Transformer 是第一个完全依赖自我注意力来计算其输入和输出表示的转换模型,而无需使用序列对齐的循环神经网络或卷积。《注意力就是一切》, NIPS 2017
所以,暂时忘记变形金刚吧,让我们学习一下这种注意力,自我关注,内部关注……..!!!! 但是,等等!这些是一样的吗?似乎作者在暗示‘注意力’和‘自我关注’并不完全相同。他们提到自我关注是一种注意机制!!如果是相同的话,那就好像说雨是湿的一样。
自注意力,有时被称为内部注意力,是一种注意力机制,关联单个序列的不同位置,以计算序列的表示。《注意力就是你所需要的》,NIPS 2017。
所以,让我们在高层次上澄清一下:
注意:这是一种机制,让模型在处理另一个序列时专注于某些部分。可以将其想象为模型在处理输出的某个部分时问到:“在工作时我应该关注输入序列的哪些部分?”
自注意力:这是一个序列关注自己的过程。模型不再去查看另一个序列,而是关注同一个序列内的其他位置。这就好像模型在问:“与这个特定部分相关的这个序列的哪些部分是重要的?”
因此,尽管两者都处理着关注相关部分,但关键的区别在于注意力是指向另一个序列(注意力)还是同一个序列内部(自我注意力)。
注意力的支柱:查询、关键词和价值
当我们在自然语言处理(NLP)中处理单词时,我们经常将它们转换成向量,通常被称为词向量。这些向量捕捉了单词本身的语义。例如,单词“apple”将有一个代表它的词向量,无论是用于“apple fruit”还是“Apple Inc.”,它的词向量不会改变。
为了解决这个限制,自注意机制可以提供帮助。它旨在为单词提供一个新的表示,不仅捕捉其固有意义,还反映了它们在给定句子中的上下文。
自注意力机制使用三个主要组件:查询(Q),键(K)和值(V)。它们对于序列中的每个单词或标记都是向量。但是,当我们考虑整个序列或批量序列时,这些向量被组织成矩阵。
什么是Q,K和V?为什么要有它们?
- 这些向量具有独特的作用。查询向量在输入中寻求特定信息。键向量对这些查询进行响应。值向量根据查询向量和键向量之间的对齐,提供我们专注于的内容。
- 将初始嵌入转换为Q、K和V意味着模型不受原始嵌入静态含义的限制。它可以学习更适用于注意机制的表征。
这些Q,V和K是如何形成的?
步骤1:我们从序列的输入表示开始,通常是一个矩阵,其中每一行对应一个单词或标记的嵌入。
对于给定的序列,每个令牌都会获得一个嵌入,即向量表示。假设我们的序列有N个令牌,每个令牌的嵌入维度为d_embed。因此,我们的输入矩阵大小为N x d_embed。
让我们来看看小句子,“我喜欢猫。” 每个单词都有一个初始嵌入(我称之为初始嵌入,因为它们对于句子来说是不变的):
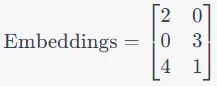
第二步:每个令牌的嵌入经过三个独立的线性变换,生成Q、K和V向量:
Q = 嵌入 x W_Q
K = 嵌入乘以W_K
V = 嵌入 x W_V
在这里,W_Q,W_K和W_V是特定于查询(Queries)、键(Keys)和值(Values)的权重矩阵。假设我们有这些初始权重矩阵,通常这些权重矩阵会随机初始化。
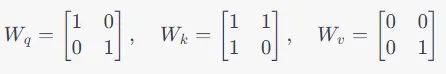

矩阵Q包含所有3个单词的Q向量,矩阵K包含所有3个单词的K向量,矩阵V包含所有3个单词的V向量。
您可能正在思考,如果我们有大量的文本或嵌入向量,这些矩阵会变得非常庞大,您绝对是正确的,欢迎来到L(arge)LMs世界!这就是第二步的结尾。
第三步:然后我们计算所谓的注意力分数。这个注意力分数应该告诉我们每个词在序列中应该如何关注其他每个词。
这是通过将一个词的Q向量与包括自身在内的每个其他词的K向量进行点积运算来实现的(暂时不考虑V矩阵)。
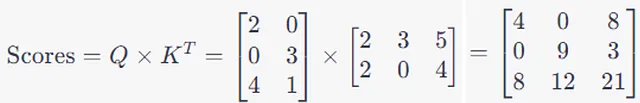
第四步:然后我们应用Softmax,换句话说,对得分矩阵的每一行进行归一化,将其缩放至较小范围。
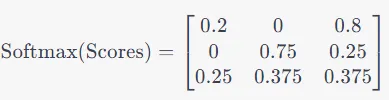
步骤5:最后一步是计算新的嵌入。将softmax分数与V矩阵相乘。

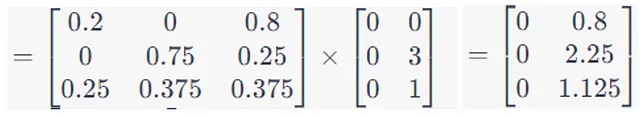
最终输出:生成的矩阵为单词“我”、“爱”和“猫”提供了新的上下文嵌入。这些表示不再仅仅关于单词本身,而是包含了句子中关于它们上下文的信息。
简而言之,在自注意机制中:
- 查询(Q)代表每个单词在句子中的上下文中的“问题”。
- 关键词 (K) 提供了其他单词如何回答这些问题的“索引”。
- 通过对向量Q和向量K进行点积运算,我们计算出注意力分数,确定每个单词应该关注其他单词的程度。
- 将英文文本翻译为简体中文,同时保持HTML结构不变: 值(V)向量然后提供来自被关注词的实际内容或“答案”。
对于我们的句子“I love cats”:
- “爱”通过其Q向量询问其上下文。
- “I”和“cats”的K向量有助于量化它们与“love”的相关性。
- 然后,关注分数会根据“我”和“猫”的V向量权衡来为“爱”创造一个富含上下文的表征。
从本质上讲,Q和K决定了注意力的权重,而V提供了上下文内容。
如果你查阅《全是你需要的关注力》论文,你会发现这在这个图示中有所体现,使用了“缩放点积注意力”这个术语。
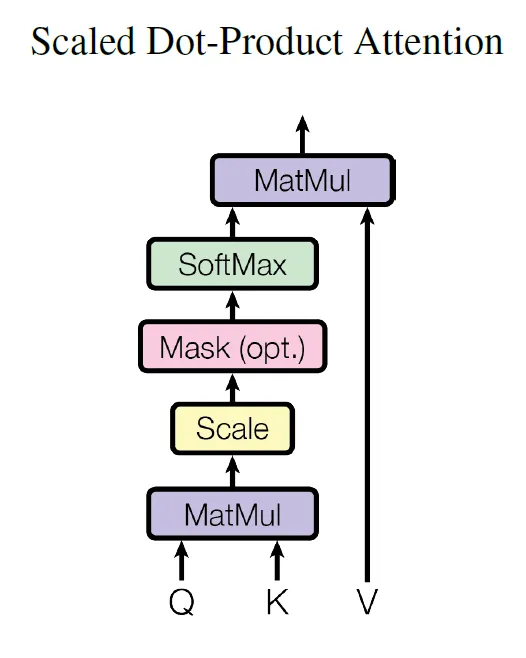
一个非常简单的示例代码,以使它更加清晰明了:
import torch
import torch.nn.functional as F
# Sample embeddings for "I love cats"
word_embeddings = {
"I": [1, 2, 3],
"love": [4, 5, 6],
"cats": [7, 8, 9]
}
# Convert embeddings to PyTorch tensors
sentence = ["I", "love", "cats"]
embeddings = [word_embeddings[word] for word in sentence]
embeddings = torch.tensor(embeddings, dtype=torch.float32)
# Initialize weights for Q, K, V
d_model = 3 # size of embeddings
Wq = torch.randn(d_model, d_model, requires_grad=True)
Wk = torch.randn(d_model, d_model, requires_grad=True)
Wv = torch.randn(d_model, d_model, requires_grad=True)
# Define a simple optimizer
optimizer = torch.optim.SGD([Wq, Wk, Wv], lr=0.01)
# === FORWARD PASS ===
# Compute Q, K, V
Q = embeddings @ Wq
K = embeddings @ Wk
V = embeddings @ Wv
# Compute attention scores
attn_scores = Q @ K.t()
attn_scores = F.softmax(attn_scores, dim=-1)
# Compute weighted V to get contextual embeddings
contextual_embeddings = attn_scores @ V
# Just for this example: synthetic "target" embeddings and loss
# (In a real-world example, you would have some downstream task to generate loss)
target_embeddings = torch.randn(3, 3)
loss = F.mse_loss(contextual_embeddings, target_embeddings)
# === BACKWARD PASS ===
# Backpropagation
loss.backward()
# Gradient Descent
optimizer.step()
print("Updated Wq:", Wq)
print("Updated Wk:", Wk)
print("Updated Wv:", Wv)多头注意力
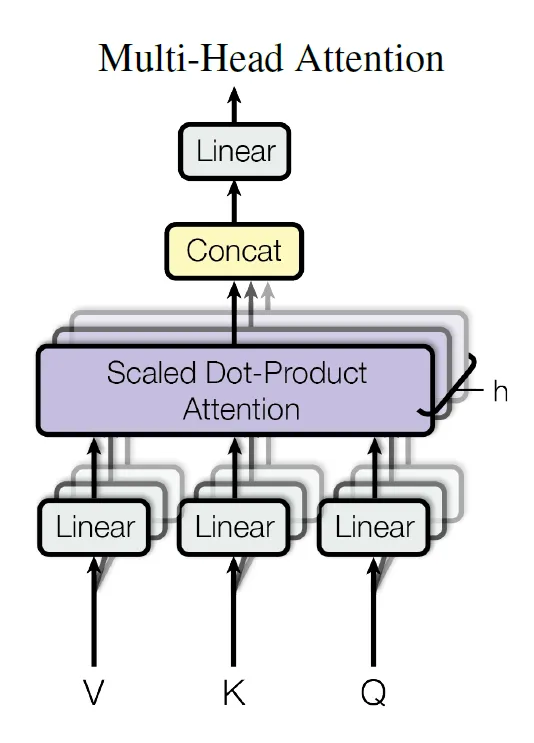
它是标准自注意机制的扩展,使得模型可以同时针对不同任务或目的关注输入的不同部分。多头注意力不同于基本的自注意力,它有多个集合或“头”,而不是只有一个注意力权重集合。
从概念上讲,在“标准”的自注意机制中,我们计算一组查询(Query)、关键(Key)和值(Value)矩阵,并得到一组注意力分数。这个单一的分数可能会聚焦于数据中的某一特定方面或模式。
通过多头注意力,我们并行地多次执行此操作,从而得到多组关注分数。每个头可能会学习专注于数据中不同的模式或方面。
为什么使用多头注意力?它使模型能够同时抓取语言处理中的句法、语义和语调等各个信息方面。
在数学上,对于每个头部,使用不同的权重矩阵:Wq,Wk和Wv。所有头部的注意力输出被连接起来,并经过线性变换用于最终输出。
如何将此多头注意力可视化的作者在下图中展示了。
回到变形金刚!
现在让我们回到我们的Transformers,看看这个注意力机制如何被用来构建Transformer模型。
许多处理序列的顶级模型都采用编码器-解码器设置。在这个设置中,编码器接收一个输入符号序列(如单词)并将其转换为连续的值。解码器然后使用这些值生成一个新的序列,根据先前的输出构建每个部分。
transformer模型,讨论在“Attention Is All You Need”论文中,遵循这个编码器-解码器框架。然而,它通过在两个部分中使用自注意力层和直观的全连接网络而脱颖而出。该结构在论文的图中有所说明,将编码器分割在左侧,解码器分割在右侧。
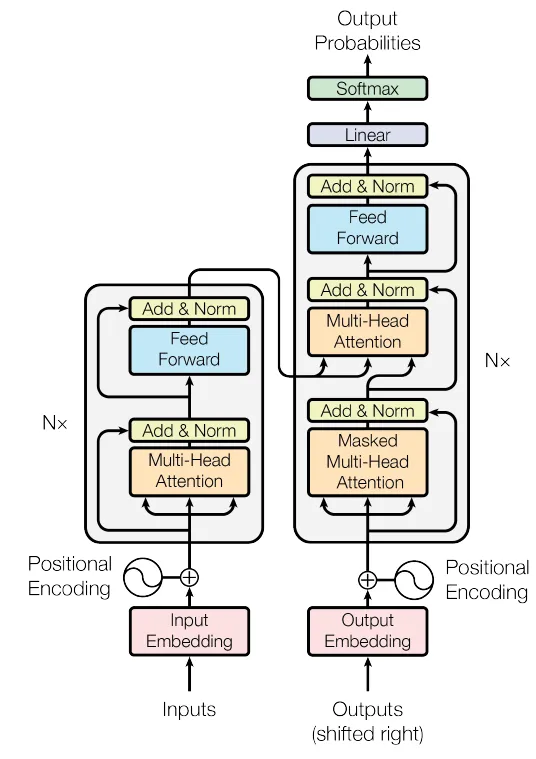
我们真的需要仔细观察这张图片及其中内容。它似乎比我们关于“查询、键、值”和自注意力的讨论更复杂。让我们试着按照论文中的方法来解读它,以便更好地进行解释、提炼直觉和编写代码。
编码器(左半部分)
原始论文中的编码器架构有6个相同的层堆叠在一起。每个层包括两个主要部分: 1. 第一个部分是多头自注意力机制(Multi-Head Self-Attention)。它将输入序列映射到一个更高维度的空间,以便系统可以更好地理解输入之间的关系。 2. 第二个部分是前馈神经网络(Feed-Forward Neural Network)。它接收经过自注意力机制处理的序列,并通过一系列全连接层进行细化和重建,以便提取更有用的特征。
- 多头自注意机制:这使得我们的模型能够同时关注输入的多个重要部分。
- 前馈网络:基础的神经层,进一步处理我们的数据。
为了确保模型在通过层时不会丢失任何数据细节,有一种捷径(称为残差连接)。该连接将原始数据与层的输出进行组合。如果您查看上面的图表,这是由结束于“添加和标准化”块的跳过箭头表示的。在此步骤之后,为了使数据保持一致和平衡,它经过了一个标准化层。
总结一下(编码器部分) ,每一层,包括嵌入层,在特定格式下都提供512维度的输出。有时候看到一个高级代码(这并不是一个可运行的代码!),可以把它看作是一个用Python表示编码器的伪代码。我们可以像这样考虑:
def transformer_encoder(input_sequence, N=6, dmodel=512):
# Initial embeddings (assumed to be provided, can be word embeddings + positional encoding)
x = embedding_layer(input_sequence)
for i in range(N):
x = encoder_layer(x, dmodel)
return x
def encoder_layer(x, dmodel):
# First sub-layer: multi-head self-attention
attention_output = multi_head_self_attention(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + attention_output)
# Second sub-layer: positionwise feed-forward network
feedforward_output = positionwise_feed_forward(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + feedforward_output)
return x
def multi_head_self_attention(x, dmodel):
# This function will compute multi-head self-attention.
# For simplicity, the internal workings are abstracted here.
# It takes in the input sequence x and dmodel and returns the attention output.
...
return attention_output
def positionwise_feed_forward(x, dmodel):
# This function will compute the feed-forward network.
# For simplicity, the internal workings are abstracted here.
# It takes in the input sequence x and dmodel and returns the feed-forward output.
...
return feedforward_output
def layer_norm(input):
# This function applies layer normalization.
# For simplicity, the internal workings are abstracted here.
# It takes in the input and returns the normalized output.
...
return normalized_output
def embedding_layer(input_sequence):
# This function returns the initial embeddings for the input sequence.
# It's assumed that this might be a combination of word embeddings and positional encodings.
...
return embeddingsDecoder(右半部分)
解码器的结构与编码器类似,都有6个相同的层。但是这里有个问题:除了编码器中的两个主要部分(多头自注意力和前馈网络)之外,解码器还有一个第三部分,专注于编码器的输出。
就像在编码器中一样,解码器使用残差连接将原始数据与层的输出相结合。然后使用归一化层使其保持一致。
解码器的一个特殊之处是它的“不能偷看”规则,这不是规则的科学名称,它被称为掩码。这意味着当解码器试图预测某个特定的词时,它不能查看未来的词。换句话说,在任何给定的位置,它只使用先前位置的信息来进行预测。这确保我们的模型不会通过提前查看来作弊!以下是解码器在Python中的高级伪代码表示:
def transformer_decoder(input_sequence, encoder_output, N=6, dmodel=512):
# Initial embeddings (assumed to be provided, which could be word embeddings + positional encoding)
x = embedding_layer(input_sequence)
for i in range(N):
x = decoder_layer(x, encoder_output, dmodel)
return x
def decoder_layer(x, encoder_output, dmodel):
# First sub-layer: masked multi-head self-attention
attention_output = masked_multi_head_self_attention(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + attention_output)
# Second sub-layer: multi-head attention over encoder's output
encoder_attention_output = multi_head_attention(x, encoder_output, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + encoder_attention_output)
# Third sub-layer: positionwise feed-forward network
feedforward_output = positionwise_feed_forward(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + feedforward_output)
return x
def masked_multi_head_self_attention(x, dmodel):
# This function will compute masked multi-head self-attention.
# It ensures that position i can't attend to subsequent positions.
...
return attention_output
def multi_head_attention(x, encoder_output, dmodel):
# This function computes multi-head attention over the encoder's output.
...
return encoder_attention_output
# The remaining functions (layer_norm, positionwise_feed_forward, and embedding_layer) can be
# re-used from the encoder pseudocode provided previously.然后变形器模型应该是这样的:
class Transformer:
def __init__(self):
self.transformer_encoder= Encoder()
self.transformer_decoder= Decoder()
def forward(self, source, target):
encoder_output = self.transformer_encoder.forward(source)
decoder_output = self.transformer_decoder.forward(target, encoder_output)
return decoder_output
# Usage (pseudocode)
transformer = Transformer()
output = transformer(source_data, target_data)关于注意力的回顾问题
那么,在Transformer里,这个注意力是如何/在哪里应用的呢?
以下是我在作者们列出这些应用程序时所理解的内容:
Transformer模型在三个主要方面使用了“多头注意力”:
- 编码器-解码器注意力
- 这是解码器(模型的一部分,用于生成输出)查看编码器(模型的一部分,用于处理输入)处理后的地方。
- 解码器使用来自其最后一层的信息,并与编码器生成的内容结合在一起。
- 这有助于解码器在输出结果时考虑整个输入序列。
2. 编码器自注意力:
- 在这里,编码器查看其自身先前的输出。
- 每个编码器输出的部分可以与其自己输出的前一层的所有其他部分进行检查和比较。
3. 解码器自注意力:
- 就像编码器一样,解码器也会查看自己之前的输出。
- 然而,有一个限制条件:解码器只能查看先前的输出或当前的输出,而不能查看未来的输出。这是为了保持模型中的某个特定属性。
- 为了确保这一点,阻止了一些可能泄露未来信息的连接。
其他组成部分
前馈网络在变压器中
在变压器模型中,无论是在输入部分(编码器)还是输出部分(解码器)的每个层级都具有作者所描述的额外结构。这个结构是一个简单的网络,以相同的方式逐个处理数据的每个部分。可以将其视为对每个数据片段应用相同的小型计算。该网络使用一个涉及两个步骤和一个名为ReLU的特殊操作的函数。
嵌入
作者解释说,变压器将输入和输出的单词或符号转换为称为向量的特殊数列。这种转换有助于计算机理解和处理它们。该模型还使用附加步骤来预测序列中的下一个单词或符号。有趣的是,模型的某些部分使用相同的一组数字,并通过特定值进行调整以获得更好的结果。
位置编码
变压器模型是独特的,因为它不会回头看以前的步骤,也不会像其他模型那样扫描数据。因此,为了理解单词或符号的顺序,作者引入了“位置编码”。这为模型提供了有关每个单词或符号在序列中所处位置的信息。这些位置编码使用基于单词或符号位置的波状函数(正弦和余弦)。作者选择这种方法是因为他们相信这将帮助模型更好地关注相对位置。
他们还测试了另一种方法,即模型自行学习位置信息。两种方法提供了几乎相同的结果。然而,作者更喜欢波动函数,因为它们可能使模型能够在比其训练时序列更长的情况下工作。
代码
到目前为止,我们了解到变压器不仅仅是一个自注意机制,而是一个完整的架构。其多功能性使其可以在许多应用中使用。在文本分类和情感分析等任务中,我们可以看到它的易用性的一个典型例子。
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
# Self-attention mechanism
def __init__(self, k):
super(SelfAttention, self).__init__()
# k: Dimension of the model embeddings
# Linear layers for query, key, and value of size (k, k)
self.key = nn.Linear(k, k)
self.query = nn.Linear(k, k)
self.value = nn.Linear(k, k)
def forward(self, x):
# x: Input tensor of shape (batch_size, seq_length, k)
# Applying linear transformations
key = self.key(x)
query = self.query(x)
value = self.value(x)
# Compute attention scores as dot products
scores = torch.bmm(query, key.transpose(1, 2)) / (key.size(-1) ** 0.5)
# Convert scores to probabilities using softmax
attn_probs = F.softmax(scores, dim=-1)
# Weight values using attention probabilities
weighted = torch.bmm(attn_probs, value)
return weighted
class EncoderBlock(nn.Module):
def __init__(self, k):
super(EncoderBlock, self).__init__()
# Self-attention mechanism
self.attention = SelfAttention(k)
# Layer normalization layers of size (k)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
# Feed-forward network with input and output of size (k)
self.ff = nn.Sequential(
nn.Linear(k, 4*k),
nn.ReLU(),
nn.Linear(4*k, k)
)
def forward(self, x):
# x: Input tensor of shape (batch_size, seq_length, k)
# Apply self-attention
attended = self.attention(x)
x = self.norm1(attended + x)
x = self.norm2(self.ff(x) + x)
return x
class DecoderBlock(nn.Module):
def __init__(self, k):
super(DecoderBlock, self).__init__()
# Self-attention mechanism
self.attention = SelfAttention(k)
# Layer normalization of size (k)
self.norm = nn.LayerNorm(k)
# Feed-forward network
self.ff = nn.Sequential(
nn.Linear(k, 4*k),
nn.ReLU(),
nn.Linear(4*k, k)
)
def forward(self, x):
# Apply self-attention and feed-forward network
attended = self.attention(x)
x = self.norm(attended + x)
x = self.ff(x)
return x
class Transformer(nn.Module):
def __init__(self, k, depth, seq_length, num_tokens, num_classes):
super(Transformer, self).__init__()
# Token embedding: Converts token indices to vectors of size k
self.token_emb = nn.Embedding(num_tokens, k)
# Positional embedding: Gives the model a sense of token order
self.pos_emb = nn.Embedding(seq_length, k)
# Encoder and decoder blocks
self.encoder = nn.Sequential(*[EncoderBlock(k) for _ in range(depth)])
self.decoder = nn.Sequential(*[DecoderBlock(k) for _ in range(depth)])
# Final linear layer: Converts vectors of size k to class probabilities
self.to_probs = nn.Linear(k, num_classes)
def forward(self, x):
# x: Input tensor of shape (batch_size, seq_length)
# Convert token indices to vectors
tokens = self.token_emb(x)
positions = torch.arange(len(x)).unsqueeze(1)
x = tokens + self.pos_emb(positions)
# Pass input through encoder and decoder
x = self.encoder(x)
x = self.decoder(x)
# Convert the output to class probabilities
x = self.to_probs(x.mean(dim=1))
return F.log_softmax(x, dim=1)结论
我们一起涵盖了很多内容,探索了广阔的Transformer世界。Transformer世界,就像机器学习的所有领域一样,是广阔而不断发展的。将这份指南作为基础,进一步提出更多问题,并继续学习。潜力巨大,你在掌握Transformer方面的旅程才刚刚开始。投入其中,进行实验,让好奇心引导你的道路。