使用LangChain和Azure OpenAI与您的SQL数据库进行“交谈”
探索使用LLMs对数据库查询进行自然语言处理的能力。
Langchain是一个开源框架,用于开发能够使用LLMs(大型语言模型)处理自然语言的应用程序。
LangChain的Agent组件是LLM的封装,它根据输入的用户问题决定最佳步骤或行动来解决问题。Agent通常可以访问一组称为工具(或工具包)的函数,并可以根据用户输入决定使用哪种工具。每个Agent可以执行各种自然语言处理(NLP)任务,例如解析、计算、翻译等。
一个代理执行器是代理和其一组工具的可运行接口。代理执行器负责调用代理,并获取动作和动作输入,使用相应的输入调用动作引用的工具,获取工具的输出,然后将所有这些信息传递回代理以获取下一个应该采取的动作。通常这是一个迭代的过程,直到代理达到最终的答案或输出。
在本文中,我将向您展示如何使用LangChain Agent和Azure OpenAI gpt-35-turbo模型,通过自然语言查询您的SQL数据库(完全无需编写任何SQL!)并获得有用的数据洞察。我们将使用SQL数据库工具包和Agent,它可以将用户输入转换为相应的SQL查询,并在数据库中运行以获得答案。
这是一篇探索性文章。它旨在提供当前可用工具的概述,并在过程中确定任何挑战。

需求范围
在这次探索中,我们只会从数据库中读取数据,并避免进行任何插入、更新或删除操作。这是为了保持数据库中的数据完整性。我们的重点是如何使用数据库中的数据回答问题。
然而,SQL代理并不保证不会根据具体问题对您的数据库执行任何DML操作。确保不会发生任何意外的DML操作的一种方法是创建一个仅具有读取权限的数据库用户,并在接下来的代码中使用它。
让我们以电子商务公司的订单和库存系统数据库为例。库存系统跟踪多个类别的产品,例如厨房用品,园艺用品,文具用品,浴室用品等等。订单系统记录了每个产品的购买历史,包括订单状态,交货日期等等。
以下是该应用的最终用户可能提出的一些问题:
- 上个月厨房产品的销量。
- 有多少訂單還沒有發貨?
- 上个月有多少订单是延迟送达的?
- 上个月最畅销的三款产品是什么?
设置
- Python>=3.8 和一个 IDE 用于我们的探索。我使用的是 VS Code。
- 我在这里使用Azure OpenAI gpt-35-turbo作为LLM。这个模型是GPT-3.5系列的一部分,可以理解和生成自然语言和代码。要跟随进行,您需要启用OpenAI服务的Azure订阅。了解更多信息请点击这里。
- 我在这里使用的是Azure SQL数据库。然而,您也可以使用本地SQL数据库。
数据库
我创建了一个名为retailshopdb的数据库,其中包含以下的表格和关系:
- 类别
- 产品
- 订单
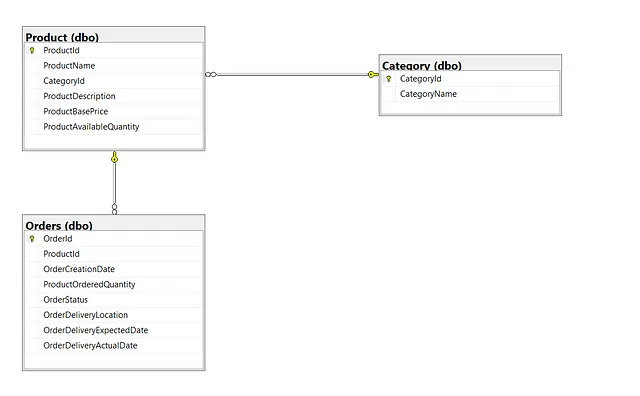
除了每个表中的“Id”列是主键外,表之间还存在外键关系,例如CategoryId是Product表的外键,而ProductId是Orders表的外键。这些关系对于LangChain代理程序根据最终用户的问题构建SQL查询非常重要。
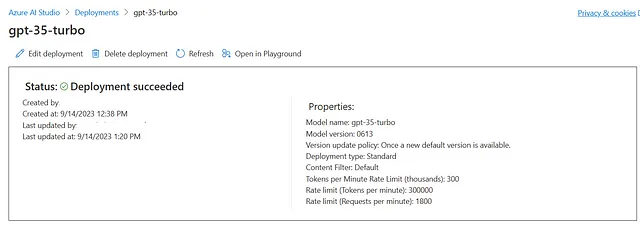
Azure开放式人工智能
如果您在订阅中创建了Azure OpenAI资源,请转到Azure OpenAI工作室。为gpt-35-turbo模型创建一个部署。
代码与输出分析
让我们从一些用于在VS代码Python笔记本中访问LLM的基本代码开始。
- 通过安装所需的库和设置所需的环境变量来初始化笔记本。
%pip install langchain openai sqlalchemyimport os
from dotenv import load_dotenv
os.environ["OPENAI_API_TYPE"]="azure"
os.environ["OPENAI_API_VERSION"]="2023-07-01-preview"
os.environ["OPENAI_API_BASE"]="" # Your Azure OpenAI resource endpoint
os.environ["OPENAI_API_KEY"]="" # Your Azure OpenAI resource key
os.environ["OPENAI_CHAT_MODEL"]="gpt-35-turbo-16k" # Use name of deployment
os.environ["SQL_SERVER"]="" # Your az SQL server name
os.environ["SQL_DB"]="retailshop"
os.environ["SQL_USERNAME"]="" # SQL server username
os.environ["SQL_PWD"]="{<password>}" # SQL server password 2. 连接到数据库。
from sqlalchemy import create_engine
driver = '{ODBC Driver 17 for SQL Server}'
odbc_str = 'mssql+pyodbc:///?odbc_connect=' \
'Driver='+driver+ \
';Server=tcp:' + os.getenv("SQL_SERVER")+'.database.windows.net;PORT=1433' + \
';DATABASE=' + os.getenv("SQL_DB") + \
';Uid=' + os.getenv("SQL_USERNAME")+ \
';Pwd=' + os.getenv("SQL_PWD") + \
';Encrypt=yes;TrustServerCertificate=no;Connection Timeout=30;'
db_engine = create_engine(odbc_str)3. 初始化LangChain chat_model实例,它提供了一个使用chat API调用LLM provider的接口。选择chat model的原因是gpt-35-turbo模型针对聊天进行了优化,因此我们在这里使用AzureChatOpenAI类来初始化这个实例。
from langchain.chat_models import AzureChatOpenAI
llm = AzureChatOpenAI(model=os.getenv("OPENAI_CHAT_MODEL"),
deployment_name=os.getenv("OPENAI_CHAT_MODEL"),
temperature=0)请注意,温度设置为0。温度是控制生成的文本的“创造性”或随机性的参数。较低的温度(0为最低)使输出更“集中”或确定性更强。由于我们在处理数据库,LLM生成的回复务必是事实性的。
4. 创建提示模板。
提示是我们发送给LLM以生成输出的输入。提示还可以被设计成包含指令、背景、示例(一次性或少量样本),这对于生成准确的输出是至关重要的,同时可以设置输出数据的语气和格式。
使用提示模板是一种良好的方式来结构化这些属性,包括最终用户的输入,以供 LLM 使用。我们在这里使用 LangChain 的 ChatPromptTemplate 模块,该模块基于 ChatML(聊天标记语言)。
这是一个基本的提示模板,用于开始。随着时间的推移,我们将根据需要更新这个模板。
from langchain.prompts.chat import ChatPromptTemplate
final_prompt = ChatPromptTemplate.from_messages(
[
("system",
"""
You are a helpful AI assistant expert in querying SQL Database to find answers to user's question about Categories, Products and Orders.
"""
),
("user", "{question}\n ai: "),
]
)现在初始化create_sql_agent,它的设计目的是与SQL数据库进行交互。该代理程序配备了工具包,可以连接到您的SQL数据库,并读取表的元数据和内容。
from langchain.agents import AgentType, create_sql_agent
from langchain.sql_database import SQLDatabase
from langchain.agents.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
db = SQLDatabase(db_engine)
sql_toolkit = SQLDatabaseToolkit(db=db, llm=llm)
sql_toolkit.get_tools()
sqldb_agent = create_sql_agent(
llm=llm,
toolkit=sql_toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)请注意,在agent_type参数的值中,我们使用的是ZERO_SHOT_REACT_DESCRIPTION,这表明该代理程序不使用记忆。
准备好运行我们的测试了
sqldb_agent.run(final_prompt.format(
question="Quantity of kitchen products sold last month?"
))请注意以下单元格输出的LangChain代理执行器如何以迭代的方式使用动作、观察和思考的流程,直到达到最终答案。
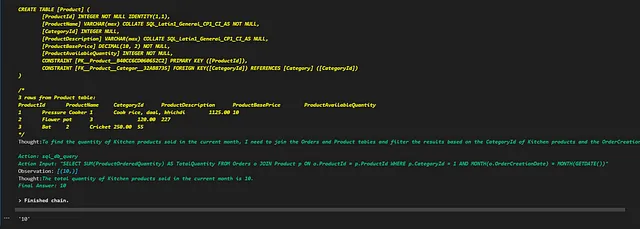
输出:10
这是一个正确的答案。
让我们玩得愉快,好吗?在相同的问题中用“多少”代替“数量”,这应该得到相同的答案。
sqldb_agent.run(final_prompt.format(
question="How many kitchen products were sold last month?"
))但这就是我们得到的——
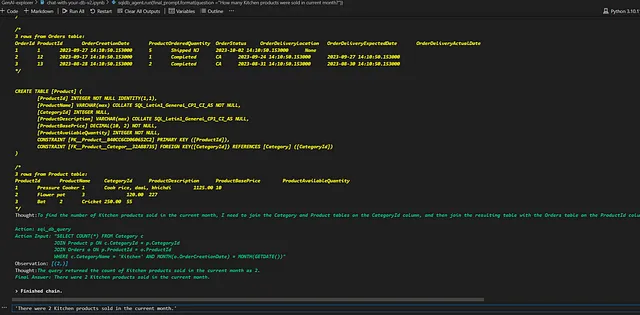
输出:'本月已经销售了2个厨房产品。'
这个输出是不正确的!代理在SQL查询创建中犯了一个错误。它没有使用SUM(ProductOrderedQuantity)来获取输出结果,而是在JOIN结果上进行了COUNT(*),导致输出结果错误。
为什么稍微更改提示输入会产生不同的输出结果?
OpenAI模型是非确定性的,这意味着相同的输入可能会产生不同的输出。将温度设置为0将使输出基本上确定性,但由于GPU浮点数计算的缘故,可能仍会有一小部分的变化。
进行另一次测试,使用不同的输入 -
sqldb_agent.run(final_prompt.format(
question="How many orders have not been shipped yet?"
))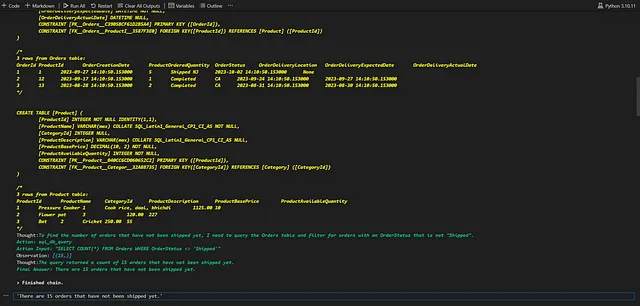
输出:‘有15个订单尚未发货。’
这是再次错误的结果。代理商也考虑了“已完成”的订单,而我们的问题只涉及那些尚未发货的订单。
让我们看看能够进行哪些修改来产生准确的输出。
与 Prompt 工程玩耍
The LangChain代理人可以使用其工具包从SQL数据库中读取表的元数据,并在某种程度上也可以解释列名。但是,在推理方面仍然存在一些差距,我们可以尝试使用提示工程技术来减轻这种差距。
我们从一个基本的提示模板开始,只包含一行指令。为了形成更好的SQL查询,让我们加入一些额外的信息,向LLM提供关于我们用例的更多背景信息。以下是我在系统消息中添加的信息。
- 关于表列的信息
- 订单状态值的‘含义’
- 最具体的信息在结尾处
from langchain.prompts.chat import ChatPromptTemplate
final_prompt = ChatPromptTemplate.from_messages(
[
("system",
"""
You are a helpful AI assistant expert in identifying the relevant topic from user's question about Categories, Products and Orders and then querying SQL Database to find answer.
Use following context to create the SQL query. Context:
Product table contains information about products including product name, description, product price and product category.
Category table contains information about categories including category name and description. Each Product is mapped to a Category.
Orders table contains information about orders placed by customers including
quantity or number of products ordered,
expected delivery date and actual delivery date of the Order in the location and the status of the order.
Order status = 'Processing' means the order is being processed by seller and not yet shipped,
Order status = 'Shipped' means the order is shipped by the seller and is on the way to the customer,
Order status = 'Completed' means the order is delivered to the customer, and
Order status = 'Cancelled' means the order is cancelled by the customer.
If the question is about number of products in an order, then look for column names with 'quantity' in the tables and use 'sum' function to find the total number of products.
"""
),
("user", "{question}\n ai: "),
]
)现在再次运行第一个输入——
sqldb_agent.run(final_prompt.format(
question ="How many Kitchen products were sold in current month?"
))
输出:10
推理能力有所提高!通过为LLM提供额外的语境,我们能够获得准确的输出。
现在测试所有用户输入 —

事后的思考 . . .
所有这些看起来都适合娱乐,但如果我们想要实际构建解决方案并发布给最终用户使用,我们将如何做呢?对于类似在自己的数据库上构建聊天机器人的用例来说,这是一个很好的想法,然而像任何典型的软件开发一样,我们在构建基于LLM系统之前也需要考虑和决定一些关键的设计方面。
可扩展性
在这个例子中,我使用了3个表,总共约30行。连接这3个表以产生输出的平均延迟约为5秒。截至今天,并没有在官方文档中找到关于这个代理程序可以使用的数据库的最大大小的任何信息。然而,我们可以考虑一些参数来确定我们的需求:
- 您的应用程序需要多少延迟?如果您正在构建一个聊天机器人,那么您的预期延迟可能不会超过某个特定数字。
- 您的数据库大小是多少?还要考虑您想用于查询的各个表的大小。
请注意,您无需将整个数据库传递给代理工具包。有选择特定表格与工具包一起使用的选项。一个好的选择是为不同的用例确定表格子集,并创建指向不同表格子集的多个代理。
3. 您的Azure OpenAI资源的速率和配额限制。如果您使用其他LLM提供商,请查看那里的限制/限制。
可靠性
如何确保我们始终获得准确的回应?我们如何确保系统不会产生错觉或生成完全意外的内容?
目前正在进行关于改进LLMs的可靠性和稳健性的研究。通过使用用例特定的提示,我们可以帮助改进我们用例的推理,有时也称为“临时或处境学习”。
记住,我们此处不是在训练LLMs(深度学习语言模型)。从使用预训练LLMs构建产品的角度来看,我们只能在这些LLMs的基础上调整我们的代码、模型参数和提示,但需要有针对性地进行调整。
以迭代的方式进行开发,并且在过程中进行评估,可以使我们朝着开发一个整体工作系统的正确方向前进。
记录和监控
与任何其他典型的软件开发一样,启用LLM应用程序的日志记录和持续监控是一个好的做法。监控不仅可以捕获与系统相关的指标,如性能、延迟、请求-响应速率,还可以捕获系统的输入和输出,这有助于我们确定系统的一致性。从监控中我们可以收集到一些有用的信息,并用于改进我们的系统:
- 经常出现的,类似的问题来自终端用户,并为这些问题生成了输出。
- LLM幻觉率
结论
软件工程界正以LLMs的巨大生成能力迅速变化,而且这个领域中涌现出很多解决方案。我们有机会采用这项技术,并利用它的力量来创造产品,同时也要保持对LLM支持系统可靠性的检查。从小处下手,构建一个概念验证应用程序,并查看它是否符合您的需求,这总是一个好主意。
参考文献:
https://community.openai.com/t/run-same-query-many-times-different-results/140588 保持HTML结构,将以下英文文本翻译为简体中文: https://community.openai.com/t/run-same-query-many-times-different-results/140588
使用OpenAI API进行提示工程的最佳实践
在与OpenAI API一起进行电子邮件撰写、代码生成等任务时,设计良好的提示工程是非常重要的。以下是使用OpenAI API进行提示工程的一些最佳实践:
- 明确任务意图:确保在提示中清楚表达您想要的结果,包括所需的格式、上下文和任何其他细节。
- 设置系统和用户:如果在生成文本时需要提及系统、用户或相关对象,请明确指出它们的特征和属性。
- 限定生成长度:通过使用
max_tokens参数限制生成文本的长度,这对于控制输出的准确性和合理性非常有帮助。 - 多次调用API:如果获取的结果不符合预期,尝试使用不同的提示组合或进行多次API调用来获取更适合的输出。
- 对输出进行过滤和修改:您可以筛选、裁剪或修改生成的文本来满足特定需求。这样可以更好地确保结果的质量和适用性。
- 保护隐私和安全:请注意,在使用OpenAI API时,避免提交可能包含敏感信息的文本。
使用以上的提示工程最佳实践,可以提高与OpenAI API的交互效果。
如需获取更详细的信息,请访问此处。
关于在生产中保证LLMs可靠性的概念
请访问以下链接查看文章:https://mlops.community/concepts-for-reliability-of-llms-in-production/
请跟随我,如果您想阅读更多关于新奇技术的内容。请在评论区留下您的反馈。