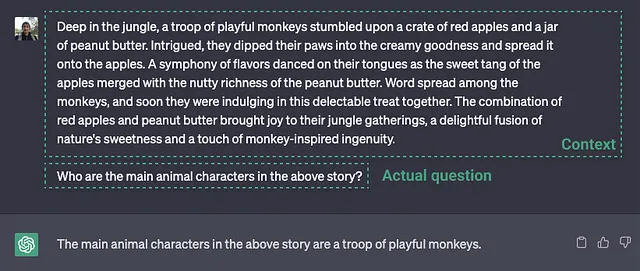
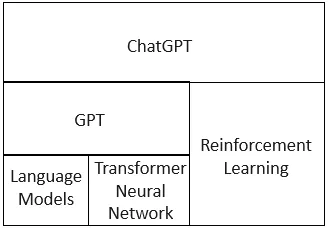
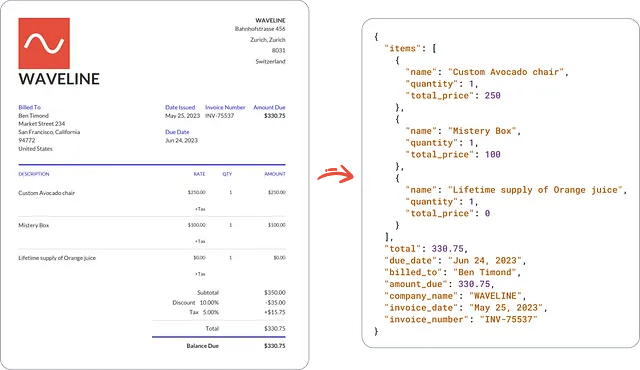
什么是LLaVA? 比LLM的更好吗?
尽管在多模态领域中,这种方法受到的关注较少,但利用机器生成的指令跟随数据来对大型语言模型(LLMs)进行指令调整,已经增强了对新任务的零-shot能力。
由于每个单独的渠道在代表和传递特定的世界概念方面有着独特的优势,并且作为结果可以更好地理解世界,人类通过多种渠道与世界进行交互,如视觉和语言。人工智能的主要目标之一是创建一个通用助手,能够遵循与人类意图一致的多模式视觉和口头命令,从而在各种野外工作中执行各种任务。
LLaVA:大规模语言和视觉助手,是一个端到端训练的大型多模态模型,连接了视觉编码器和LLM以便于通用的视觉和语言理解。该模型是通过生成的数据进行训练,并使用指令调整。我们的初步研究发现,LLaVA展现出优秀的多模态对话能力,偶尔在未见过的图像或指令上展示出多模态GPT-4的行为,并在合成多模态指导数据集上与GPT-4相比获得了85.1%的相对分数。LLaVA和GPT-4的结合在科学问答任务上进行调整后,取得了92.53%的新纪录准确率。该模型及其代码基可公开共享,并且视觉指令调整是在GPT-4生成的数据上完成的。

一个更近期的文献综述可在论文《野外计算机视觉》中找到。在这一研究领域中,每个任务都由一个单一的大型视觉模型独立解决,模型设计过程中隐含考虑了任务规范。此外,语言仅用于描述图像的内容。LLaVA模型使语言在将视觉信号映射到语义上起到了重要作用,这是人类交流的典型方式,但它导致模型通常具有固定的接口,几乎没有交互能力,也无法对用户的命令做出响应。
另一方面,大型语言模型(LLM)已经证明语言可以扮演更多的角色。角色:作为通用助手的普遍接口,允许明确地使用不同任务指令的语言表示来指导端到端训练的神经助手进行下一个任务的解决,这是一个有趣的任务。例如,ChatGPT和GPT-4当前的成功证明了对齐的LLM在遵循人类指令方面的有效性,并激发了对创建开源LLM的浓厚兴趣。

为了展示LLaVA的图像解释和对话技能,创建了一个聊天机器人原型,以更好地了解LLaVA如何处理视觉信息以及它如何遵循指示。原始的GPT-4示例已经被利用。这个挑战需要深入理解图片。为了比较,使用多模态GPT-4的提示和回应,我们查询BLIP-2和OpenFlamingo模型的检查点以获取它们的回应。

一个方法已经被采用,用于在GPT-4无法提供解决方案时,通过LLaVA方法进行预测。该方法的准确率达到90.97%,几乎与仅使用LLaVA方法作为判断依据的GPT-4相等。当GPT-4和LLaVA得出不同结论时,我们会再次提醒GPT-4,并要求根据问题和两个结果提供自己的结论。
虽然CoT从另一个模型获取了外部知识,但其精神是相似的。令人惊讶的是,GPT-4实现了92.53%的新的SoTA准确率,并在所有问题类别上持续改进。相信这是首次利用GPT-4进行模型组装。希望未来能对更高效地使用LLM进行模型集成进行进一步研究,并取得令人鼓舞的结果。