使用ChatGPT从文档中提取数据
使用大型语言模型(LLM),从PDF等文件中提取数据的指南
将PDF转换为纯文本。
为了从PDF中提取文本,可以区分两种主要的方法:
- 光学字符识别(OCR)
- 解析
使用OCR,你可以在像素级别上扫描PDF并识别出所有的字符/词语。这通常是通过一个经过训练的机器学习模型来完成的,该模型可以识别常见的字符。而解析则是通过深入PDF的内部结构和元数据来提取书写的词语。传统算法可以用于简单的基准。
对于这个指南,我们可以使用免费的在线转换器。以下是一些例子:pdf2go.com,smallpdf.com,pdftotext.com
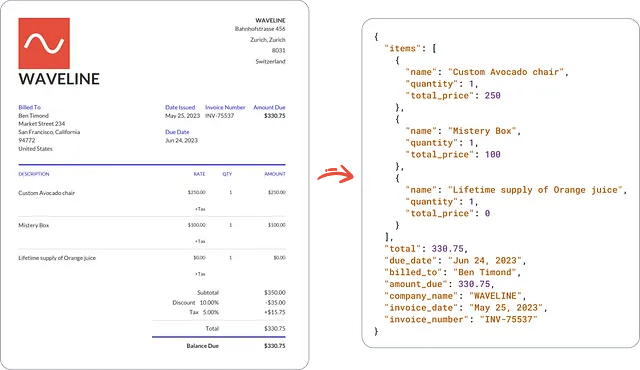
Text: WAVELINE Bahnhofstrasse 456 Zurich, Zurich 8031 Switzerland WAVELINE Billed To Ben Timond Market Street 234 San Francisco, California 94772 United States Date Issued Invoice Number May 25, 2023 INV-75537 Amount Due $330.75 Due Date Jun 24, 2023 DESCRIPTION Custom Avocado chair RATE QTY AMOUNT $250.00 1 $250.00 1 $100.00 1 $0.00 +Tax Mistery Box $100.00 +Tax Lifetime supply of Orange juice $0.00 +Tax Subtotal $350.00 Discount 10.00% -$35.00 Tax 5.00% +$15.75 Total $330.75 Balance Due $330.75使用LLM提取所需信息
下一步,我们设计一个提示,告诉LLM我们要提取哪些数据。我们还确保以JSON格式输出结果。
You extract data from the text provided below into a JSON object
of the shape provided below.
Shape:
{
total: number // total amount due,
invoice_number: string // invoice number,
billed_to: string // name of the person that needs to pay the invoice
}
Text: WAVELINE Bahnhofstrasse 456 Zurich, Zurich 8031 Switzerland WAVELINE Billed To Ben Timond Market Street 234 San Francisco, California 94772 United States Date Issued Invoice Number May 25, 2023 INV-75537 Amount Due $330.75 Due Date Jun 24, 2023 DESCRIPTION Custom Avocado chair RATE QTY AMOUNT $250.00 1 $250.00 1 $100.00 1 $0.00 +Tax Mistery Box $100.00 +Tax Lifetime supply of Orange juice $0.00 +Tax Subtotal $350.00 Discount 10.00% -$35.00 Tax 5.00% +$15.75 Total $330.75 Balance Due $330.75喜讯🎉通过查询GPT-4,我们获取到以下的JSON回复:
{
"total": 330.75,
"invoice_number": "INV-75537",
"billed_to": "Ben Timond"
}需要注意的事项
数据提取可能不总是按预期工作。以下是一些需要留意的事项。
坏的OCR/解析根据您的输入,OCR方法比解析方法更好,反之亦然。这一步骤的质量会传递到最终结果上。如果我们未能正确将PDF转换为LLM可以阅读或写下错误信息的表示形式,那么我们会失去质量。存在着可以提高质量的先进OCR AI模型,例如Tesseract。
幻觉如果在您提供的文本中找不到信息(这可能发生在将PDF转换为文本时在解析/OCR步骤中遗漏了一些部分,或者如果信息在PDF中本来就没有提供),LLM会倾向于创造或猜测信息。我们需要确保这种情况不会发生。

所以尽管没有明确指定性别,模型也产生了幻觉。一个常见的方法是为LLM提供一个简单的退出方式。例如,通过在提示中添加:
If the provided information is not explicitly written, write UNSUREContext-window-size每个LLM都有一定数量的标记可以处理。输入标记的数量加上输出标记的数量需要小于此上下文窗口。对于GPT-4来说,这个数量为8k,我们的示例足够小。否则,我们将不得不将我们的提取分成多个LLM调用。请注意,不要将表格分成两部分,其中第二部分没有标题,而LLM不知道每一列代表什么。
输出结构一致性 LLM 可能不总是输出所需的 JSON。也许会提供一些填充文本,如“当然,这里是提供的…”,或者返回的 JSON 格式错误,特别是在您的形状更复杂的情况下。

在这里,我们可以看到交易被写成了对象内的对象,而不是对象数组。因此,我们应该仔细检查 LLM 输出的结构。
结论
语言模型具有惊人的功能,现在可以帮助您从文档中提取特定的信息。如果它适用于您的用例,您可以很快测试它。确保可靠性和良好质量有一些陷阱,但这些可以通过工程努力来解决。
如果您不想处理繁琐的事务,只希望使用一个方便实用的服务,请尝试一下waveline.ai!
愉快地提取 :)