RAG 与微调:选择最佳工具 适合您的法学硕士课程的挑选
在不断发展的机器学习世界中,选择合适的工具有时候就像是大海捞针。今天,我们将深入探讨两种在使用像GPT-4这样的大型语言模型时常用的方法:RAG(检索增强生成)和微调。准备一杯咖啡,让我们一起开始这个探索之旅吧!
简介
在我们深入了解之前,让我们通过简要概述一下RAG和微调的内容来给出背景。想象一下:你站在一个十字路口,一条路径通往了RAG的世界,这是一种混合方法,结合了检索系统和生成模型的能力;另一条路径通往了微调的领域,这是一种更简单但高效的方法,可以根据特定任务来调整预训练模型。你会选择哪条路径呢?让我们找出答案!
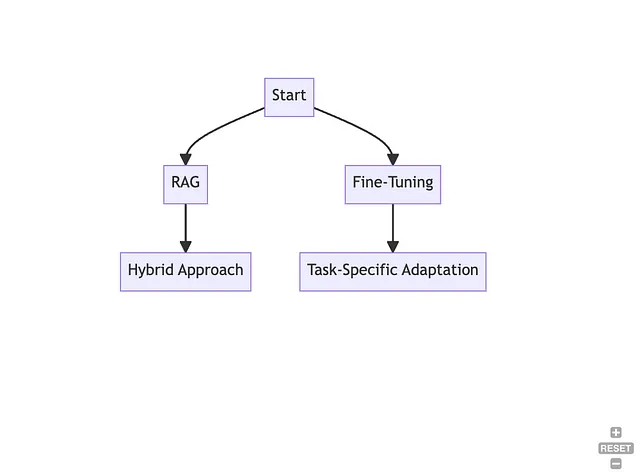
检索-增强生成(RAG)
审视更近一些
想象一下,你可以随时拥有一位智慧丰富的老贤者,从大量的图书馆中获取知识,制定出明智的回答。这就是 RAG!就好像有一位知识渊博的朋友,能够从各种来源获取信息,帮助生成更明智的回答。
使用时机
当您想要整合大量文件语料库中的丰富知识时,RAG可以发挥其优势。对于希望模型成为信息仓库并能够生成准确且内容丰富的回答时,它尤为有用。
代码示例
让我们来看一个简单的Python脚本,展示如何使用Hugging Face的Transformers库来使用RAG。
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
# Initialize tokenizer and model
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq")
# Initialize retriever
retriever = RagRetriever.from_pretrained("facebook/rag-sequence-nq", index_name="exact", use_dummy_dataset=True)
# Encode input and retrieve relevant documents
input_text = "What is the capital of France?"
inputs = tokenizer(input_text, return_tensors="pt")
with retriever:
outputs = model(inputs.input_ids, labels=inputs.input_ids)
# Generate response
decoded_output = tokenizer.decode(outputs.logits.argmax(dim=-1), skip_special_tokens=True)
print(decoded_output)现实世界的例子
想象一款为学生提供帮助的虚拟助手,它能够从广泛的教育资料中提取数据,以提供对复杂问题的详细回答,帮助学生更深入地理解各种主题。
细调
仔细观察
现在,让我们走进细调的道路。想象一位雕塑家,仔细凿刻以打造一件杰作。细调就类似于这个过程,你可以微调一个预训练模型以更好地适应特定任务,从而创造出一种擅长于那个特定任务的专用工具。
何时使用
微调是你在心中有一个特定任务或领域时的最佳选择。它就像在你的工具箱中拥有一个专门的工具,随时准备以极高的精确度完成特定的工作。
代码示例
以下是一个使用Hugging Face的Transformers库来微调GPT-4模型的Python脚本示例:
from transformers import GPT2Tokenizer, GPT2LMHeadModel, GPT2Config
# Load pre-trained model and tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Fine-tuning the model with new data
new_data = ["Sample sentence 1", "Sample sentence 2"]
inputs = tokenizer(new_data, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs, labels=inputs['input_ids'])
# Calculate loss
loss = outputs.loss
loss.backward()
# Optimization step (assuming optimizer has been defined)
optimizer.step()真实世界的例子
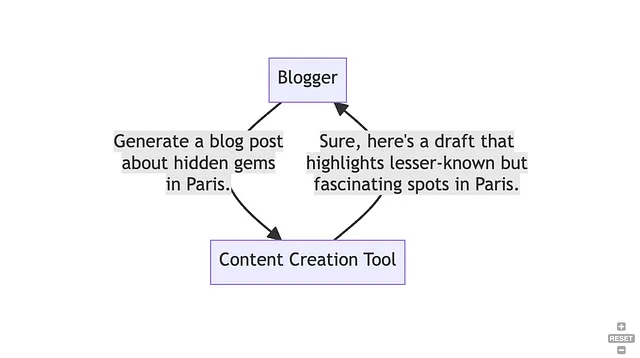
考虑一个为特定领域进行优化的内容创作工具,比如旅游博客,为博主提供与他们的领域相关的创意而引人入胜的内容建议。
结论
随着我们接近旅程的尽头,很明显,在使用RAG和微调之间的选择取决于诸多因素,包括项目需求、数据特征和可用资源。这就像在瑞士军刀和专用工具之间选择一样,每种选择都有其自身的好处,并适用于不同的任务。
所以,请自行尝试这两种方法,并且祝愿您的机器学习之旅既富有成果又充满乐趣!