修复LLMs中的幻觉问题
为什么LLMs产生幻觉,缓解方法,评估数据集的挑战以及更多内容。

生成式大型语言模型(LLM)能够对各种用户提示生成非常流利的回应。然而,它们产生的偏执妄想或非事实陈述的倾向可能会损害信任。
I think we will get the hallucination problem to a much, much better place... it will take us a year and a half, two years. — OpenAI CEO Sam Altman
我认为我们将会把幻觉问题解决到一个更好的地步... 这将需要我们一年半到两年的时间。
—— OpenAI 的首席执行官 Sam Altman
随着开发人员尝试使用模型构建系统,这些限制提出了一个真正的挑战,因为整体系统必须满足质量、安全和可靠性要求。例如,我们能相信由LLM提供的自动代码审查是否正确吗?或者对处理与保险相关任务的问题的回答是否可靠?
本文首先概述了在语言生成模型中幻觉问题一直存在的挑战,然后介绍了解决幻觉和可靠性问题的步骤(以及相关的研究论文)。
免责声明:
本文章信息截至2023年8月为准,但请注意之后可能会发生变更。
“简短”概述
幻觉在大型语言模型中源于数据压缩和不一致性。质量保证具有挑战性,因为许多数据集可能过时或不可靠。为了减轻幻觉情况:
- 调整温度参数以限制模型的创造力。
- 密切关注及时工程。要求模型逐步思考,并在回答中提供事实和参考来源。
- 利用外部知识源来改善答案验证。
这些方法的综合应用可以达到最佳效果。
什么是LLM幻觉?
一个来自人工智能研究中心的研究论文将LLM中的幻觉定义为“当生成的内容毫无意义或与提供的源内容不一致时”。
幻觉可以分为几种类型:
- 逻辑谬误:该模型在推理过程中出现错误,给出了错误的答案。
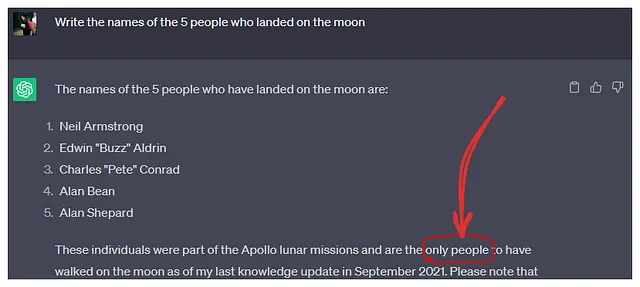
- 事实捏造:模型自信地断言不存在的事实,而不是回答“我不知道”。例如:谷歌的 AI 聊天机器人 Bard 在第一次演示中犯了一个事实错误。
- 数据驱动偏见:由于某些数据的普遍性,模型的输出可能会偏向,导致结果不正确。示例:在 NLP 模型中发现的政治偏见。
为什么LLMs会产生幻觉。
我喜欢这篇文章中的概念:当我们压缩训练数据时,模型必然会产生幻觉。考虑一些受欢迎模型的压缩比率:

当然,这种压缩的关键在于生成模型存储了输入(文本或像素)之间关系(概率)的数学表达,而不是输入本身。更重要的是,这种表达使我们能够提取知识(通过采样或运行查询/提示)。
这样的压缩会降低保真度,类似于JPEG压缩,正如《纽约客》的文章所讨论的那样。从本质上讲,完全恢复原始知识变得困难,如果不是不可能的任务。模型倾向于不完美地“填补空白”或产生幻觉,这是用这种压缩但有用的知识表达所需要做出的权衡。
当LLMs的训练数据集中包含有限、过时或矛盾的关于提出的问题的信息时,它们也会产生错觉。
准备实验
本文旨在创建和测试减少幻觉并改善系统性能的实际步骤。为此,经过查阅各种数据集后,我选择了TruthfulQA基准进行研究。

尽管数据集存在问题,比如正确答案与其来源之间的差异,但由于其涵盖了多种话题并且内容全面,它仍然是最合适的选择。我也很欣赏答案以测验形式呈现,方便进行模型测试。我们可以轻松地请求以JSON格式获取答案。
返回JSON格式的响应,例如:[{"class": "A"}]
我使用了一个包含800行数据的数据集,并选择了GPT-3.5 turbo来提高成本效益。
其他评估幻觉的基准指标
- 知识导向型硕士法学评估基准(KoLA)
- TruthfulQA: 测量模型如何模仿人类的虚假言论
- 医学领域对于大型语言模型的幻觉测试
- HaluEval:供LLM评估的幻觉评估基准
温度降低
一个模型的温度是指用于调整模型预测的概率分布的标量值。在LLMs的情况下,它在坚持模型从训练数据中学到的内容与生成更多多样化或创造性回答之间取得平衡。一般而言,这些创造性的回答更容易产生幻觉。
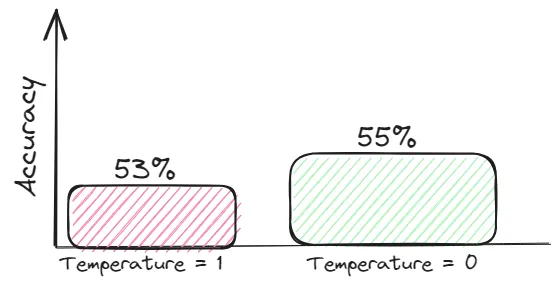
对于需要真实性的任务,努力追求信息丰富的背景,并将温度设置为0,以获得与背景相关的答案。
思维连续性与自洽性
算法错误通常可以通过改进提示设计来解决。这就是为什么我更加关注这个话题的原因。
LLM在多步推理任务(如算术或逻辑)上经常失误。最近的研究指出,提供将任务分解为步骤的示例可以提升性能。值得注意的是,仅仅提示“让我们逐步思考”而不提供具体的示例也会产生类似的改善效果。
许多文章深入探讨思维链接技术。本质上,它们旨在逐步引导模型思考并自我验证。以下是一些突出的方法:
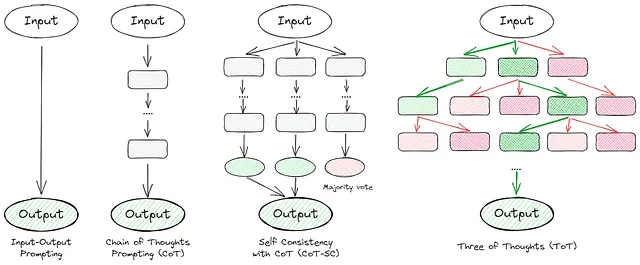
现在,让我们深入研究每种方法,并评估它们在数据集上的质量。
思维链 (CoT)
文章的主要内容是在提示中加入"思考逐步进行"。
在回答之前,逐步思考并以 JSON 格式返回响应,例如:[{“class”: “A”}]”。
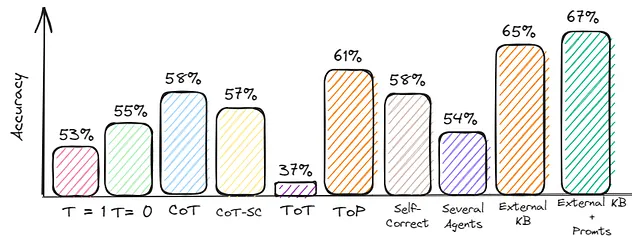
评估:准确率 = 58%
2. CoT自洽性(CoT-SC)
这种方法是之前想法的改进版本。我们要求模型给出多个答案,然后通过投票选择最佳答案。
在回答之前逐步考虑并给出三个答案:如果一个领域专家回答,如果一个主管回答,以及你的答案。以下是JSON格式的响应:
评估:准确率 = 57%
3. 思维之树
它是一个框架,可以泛化思维链索提示,并鼓励探索作为通用问题解决的中间步骤的思维。这种方法使得语言模型能够通过有意识的推理过程自我评估中间思维在解决问题上的进展。一个示例的ToT提示是:
假设有三个不同的专家回答这个问题。所有专家都会记录下他们思考的第一个步骤,然后与小组分享。然后所有专家都会继续进行下一步,依此类推。如果任何专家在任何时候意识到他们是错误的,则离开。以下是以JSON格式的回应:
评估:准确度 = 37%
4. 标签化的语境提示
该方法包括生成问题集、通过摘要创建上下文提示,并验证上下文提示和问题。
鉴于额外数据集生成的复杂性,我调整了我的方法来请求源链接和事实信息。
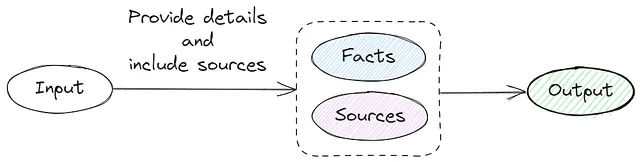
提供细节并在回答中包含来源。以JSON格式返回响应,例如:[{"class": "A", "details": "静脉中的人血实际上并不是蓝色的。血液由于含有血红蛋白而呈现红色。", "source": "https://example.com"}]
评估:准确率 = 61%
5. 自我纠正
它可能是更高级的快速工程技术之一。这个想法是让模型进行复查并批评其结果,如下所示:
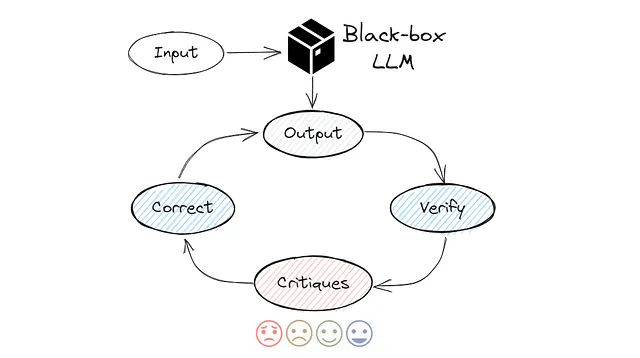
选择最有可能的答案从列表中[“A”,“B”,“C”,“D”,“E”],仔细检查你的答案。思考这是否是正确的答案,其他人是否会同意?如有必要,改进你的答案。以JSON格式返回响应,例如:[{“first_answer”:”A”, “final_answer”:”B”}]
评估:准确率 = 58%
6. 几个代理
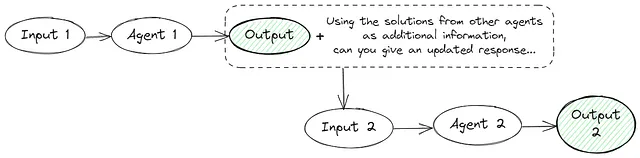
多语言模型实例在多轮中提出和辩论各自的回答和推理过程,以达到一个共同的最终答案。这种方法包括几个提示:
提示一
按照以下步骤逐渐给出事实和你的想法,以找到对这个问题的正确答案:{QUESTION}
问题2
保持HTML结构,将以下英文文本翻译为简体中文: 使用其他代理的解决方案作为附加信息,选择正确的答案选项:{问题} {答案}。以JSON格式返回响应...
评估:准确性 = 54%
我不建议在实际应用中使用这种方法,因为你需要发出两个或更多的请求。这不仅增加了API的成本,还会减慢应用程序的速度。在我的情况下,生成800个问题的响应花费了两个小时以上。
使用外部知识库
正如前面所提到的,LLM中的幻觉源于试图重构压缩信息。通过在预测过程中提供来自知识库的相关数据,我们可以将纯生成问题转化为基于提供的数据的简化搜索或总结问题。
由于在实践中,从知识库检索相关数据并非易事,因此我选择了我收集的数据集中的一个小样本(约300行)进行重点研究。
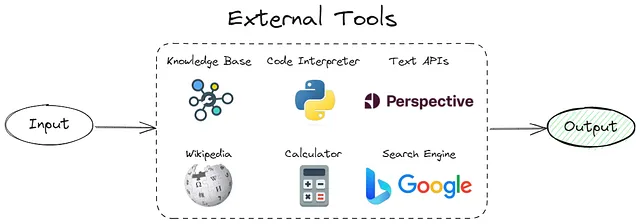
最后,我的提示看起来是这样的:
使用此信息{INFORMATION}选择正确答案{QUESTION}并以JSON格式返回响应...
评估:准确率 = 65%
仍然需要更多的工作来过滤/排序检索到的语句并决定在这个任务中使用多少LLM上下文预算。此外,检索和排序可能会引入对于实时交互非常重要的延迟。
另一种有趣的方法是检索增强生成(Retrieval-Augmented Generation,RAG),它将检索和文本生成的能力结合在大型语言模型中。该方法使用一个检索系统从庞大的文集中获取相关的文档片段,并结合一个基于检索到的信息生成答案的语言模型。
一些相关文章
- 虚拟文档嵌入(HYDE)-本论文提出使用来自LLM的初始答案作为检索相关段落的软查询。
- 通过交互式问题-知识对齐来减轻语言模型幻觉
- 揭示:使用多源多模态知识记忆进行检索增强的视觉-语言预训练
- RAG vs 微调——哪一个是提升你的LLM申请的最佳工具?
工程提示和外部知识库
这种方法结合了之前的观点。使用了不同的提示工程技术和外部知识库。我从CRITIC框架中实施了逻辑。
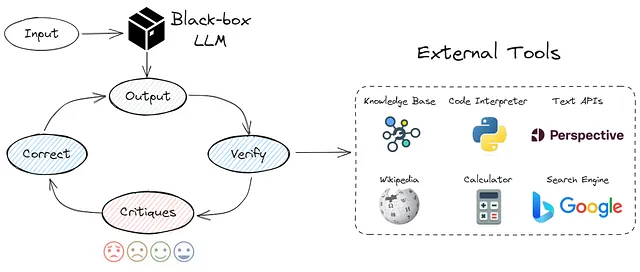
使用这些信息{INFORMATION}选择正确答案{QUESTION} 然后仔细核对你的答案。思考一下这是否是正确的答案,其他人是否会同意它?根据需要改进你的答案。以JSON格式返回响应,例如:[{"first_answer":"A", "final_answer":"B"}]
评估:准确率 = 67%
尽管质量并没有提高太多,但这是由于我所使用的数据集存在问题。一些“正确”的答案与来源信息不相符。
外卖
乍一看,减少LLM中的幻觉并不是什么高深的科学:调整温度,玩弄提示,并链接外部数据源。然而,就像许多事情一样,细微差别无处不在。每种方法都有其优点和缺点。
我的主要建议是什么?优先考虑及时的设计 - 这是修复幻觉的最经济高效的方式。
参考资料
- 使用大型语言模型构建系统以减少幻觉和提高性能的实用步骤 — 这是我找到的最好的文章之一。
- 浏览LLMs中幻觉的阅读列表 — 一个有关LLMs中幻觉的各种链接的实用GitHub代码库。
如果您有任何问题或建议,请随时在LinkedIn上联系。