适者生存:紧凑的生成式人工智能模型是大规模成本有效的人工智能的未来
灵活、有针对性且以检索为基础的模型作为大规模部署的生成式人工智能应用的最佳解决方案的案例。
经过十年的人工智能(AI)模型复杂性和计算能力的快速增长,2023年标志着关注重点转向效率和生成式人工智能(GenAI)的广泛应用。因此,出现了一批参数少于150亿的新模型,被称为灵活的AI,它们能够与包含超过1000亿参数的ChatGPT风格的巨型模型相媲美,尤其是针对特定领域的应用。虽然GenAI已经在各行各业中用于广泛的业务用途,然而使用紧凑但高度智能的模型却越来越多。在不久的将来,我预计会出现一小部分巨型模型和大量嵌入无数应用程序的小型、更灵活的AI模型。
虽然大型模型取得了很大的进展,但在培训和环境成本方面,更大并不一定更好。TrendForce估计,仅ChatGPT模型的培训费用就超过1亿美元,而灵活的模型预训练成本要低得多(例如,MosaicML的MPT-7B被报价大约为20万美元)。大部分计算成本发生在持续推理执行过程中,但对于更大的模型来说,这也带来了相似的挑战,包括昂贵的计算。此外,托管在第三方环境中的巨型模型带来了安全和隐私方面的挑战。灵活的模型运行成本更低,并提供一系列额外的好处,如适应性、硬件灵活性、与更大应用程序的集成能力、安全和隐私、可解释性等(见图1)。较小型模型性能不如较大型模型的观念也在改变。较小、专注的模型并不缺乏智能——它们可以为商业、消费者和科学领域提供相等或更优越的性能,提高其价值的同时降低时间和成本投入。
越来越多的这些灵活的模型大致与ChatGPT-3.5级巨型模型的性能相匹配,并且在性能和范围上持续快速提升。而且,当灵活模型配备了即时检索精选领域特定私有数据和基于查询的网络内容定向检索功能时,它们比广泛数据集上记忆的巨型模型更准确、更具成本效益。

随着灵活的开源GenAI模型走在前沿,推动领域的快速发展,这个“iPhone时刻”,即革命性技术成为主流,正面临一个被“安卓革命”挑战的局面。一个由研究人员和开发者组成的强大社区正在借鉴彼此的开源努力,创造出越来越有能力的灵活模型。
思考,行动,知道:具有有针对性领域的灵活模型可以像巨大的模型一样表现。

为了更好地理解何时和如何一个较小的模型可以为生成式人工智能提供高竞争力的结果,重要的是要观察到灵活和庞大的生成式人工智能模型都需要三类能力来执行任务。
- 认知能力思考:包括语言理解、概括、推理、规划、经验学习、长篇阐述和互动对话。
- 实用技能要求:例如——识别野外文本,阅读图表/图表,视觉识别,编程(编码和调试),图像生成和语音。
- 信息(已记忆或检索的)要了解的内容:网页内容,包括社交媒体、新闻、研究和其他一般内容,以及/或策划的特定领域内容,如医疗、金融和企业数据。
根据其认知能力,该模型可以“思考”和理解、概括、综合、推理和组合语言以及其他符号化表达。灵活型和巨型模型在这些认知任务中都表现得很好,并且目前并不清楚这些核心能力是否需要庞大的模型尺寸。例如,像微软研究的奥卡这样的灵活型模型已经在多个基准测试中展示了与ChatGPT相匹配甚至超越其理解、逻辑和推理技能的能力。此外,奥卡还证明了推理能力可以通过用作教师的更大模型中提炼出来。然而,目前用于评估模型认知能力的基准测试仍然比较初级。进一步的研究和基准测试需要进行,以验证灵活型模型是否可以预训练或微调以完全匹配巨型模型的“思考”能力。
功能技能是要做的。大型模型往往具有更多的功能技能和信息,因为它们的整体关注点是全能型模型。然而,对于大多数商业应用来说,部署的任何应用程序都需要一定范围的功能技能。用于商业应用的模型应具备灵活性和发展空间,以及多样化的使用方式,但很少需要一个无限制的功能技能集合。GPT-4可以生成多种语言的文本、代码和图像,但说话数百种语言并不意味着这些巨型模型在根本认知能力上更强 — 它主要是为模型增加了更多的功能技能来“完成”更多任务。此外,功能专门化引擎将与GenAI模型相连,并在需要该功能时使用 —— 比如,通过为ChatGPT模块化添加数学“沃尔夫拉姆超能力”,可以提供最佳的功能性能,而无需给模型带来不必要的规模负担。例如,GPT-4正在部署插件,这些插件实质上利用了较小的模型来进行附加功能。有传言称,GPT-4模型本身是由训练在不同数据和任务分布上的多个巨型(参数少于1000亿)“专家混合模型”组成,而不是像GPT-3.5那样的单一巨型密集模型。为了获得最佳的能力和模型效率组合,未来的多功能模型很可能会采用比每个模型小于150亿参数的较小、更专注的专家混合模型。
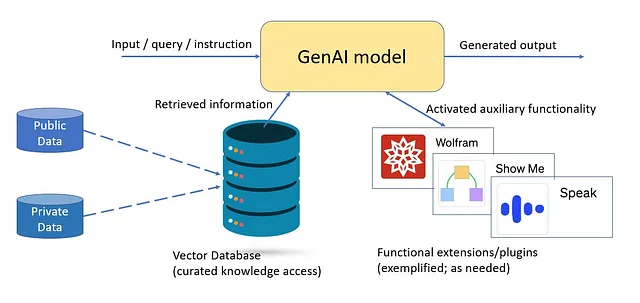
信息(记忆或检索到的)需要了解。巨型模型通过在参数化内存中记忆大量数据来“了解”更多,但这并不一定使它们更聪明。它们只是比较小的模型更加通识。巨型模型在零-shot环境中具有高价值,适用于新的用例,为没有需要进行定位的普通消费者提供服务,并在提炼和微调Orca等灵敏模型时充当教师模型。然而,有针对性的灵敏模型可以根据特定领域进行训练和/或微调,为所需的能力提供更犀利的技能。
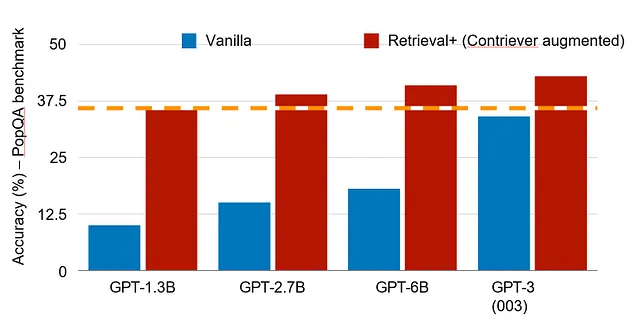
例如,针对编程的模型可以关注不同的能力集,而与之不同的是医疗AI系统。此外,通过使用策划的一组内部和外部数据进行检索,可以大大提高模型的准确性和及时性。最近的一项研究表明,在PopQA基准测试中,具有1.3B参数并使用检索的模型可以与具有175B参数的模型相媲美(见图4)。从这个意义上说,具有高质量索引可访问数据的目标系统的相关知识可能比多合一通用系统更加广泛。这对于大多数需要用例或应用特定数据的企业应用程序可能更为重要,并且在许多情况下,更依赖本地知识而不是广泛的通用知识。这就是灵活模型的价值所在,并将在未来实现。
三个方面促进了灵活模型的爆炸性增长。
评估灵活模式的好处和价值时,有三个方面需要考虑:
- 高效率的同时保持较小的模型尺寸。
- 开源或专有的许可。
- 模型专业化为通用型或定制型,包括检索。
就尺寸而言,敏捷的通用模型,如Meta的LLaMA-7B和-13B或技术创新研究所的Falcon 7B开源模型,以及MosaicML的MPT-7B、微软研究的Orca-13B和Salesforce AI研究的XGen-7B等专有模型正在快速改进(见图6)。拥有高性能、较小模型的选择对操作成本和计算环境的选择具有重要意义。ChatGPT的175B参数模型和GPT-4的估计参数1.8万亿需要大量安装加速器,如具备足够计算能力来处理训练和微调工作负载的GPU。相比之下,敏捷模型通常可以在任何选择的硬件上进行推理,从单个插槽CPU到入门级GPU,再到最大的加速架。目前,基于13B参数或更小尺寸模型的出色结果,敏捷AI的定义被设定为15B参数。总体而言,敏捷模型提供了一种更具成本效益和可扩展性的处理新用例的方法(详见敏捷模型的优缺点部分)。
开源许可的第二个方面允许大学和公司对彼此的模型进行迭代,推动了创意创新的繁荣。开源模型允许小型模型能力的惊人进展,如图5所示。
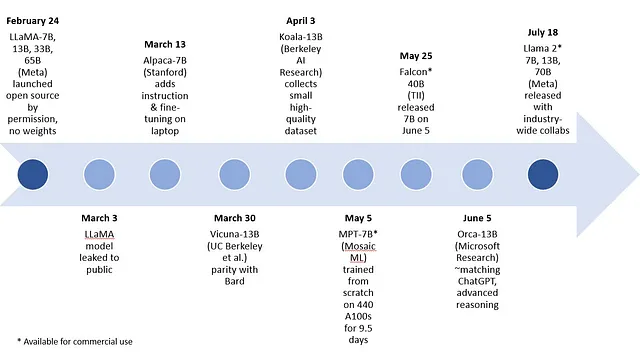
有多个2023年初的示例,展示了通用灵活的生成式AI模型,其中最早的是Meta的LLaMA,它具有7B、13B、33B和65B个参数的模型。下列7B和13B参数范围内的模型是通过对LLaMA进行微调而创建的:Stanford大学的Alpaca,伯克利AI研究的Koala,以及由加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣迭戈分校和MBZUAI研究人员创建的Vicuna。最近,微软研究发表了一篇关于尚未发布的Orca的论文,这是一个基于13B参数的LLaMA模型,它在定位到特定领域之前或进行微调之前,能够模仿巨型模型的推理过程并取得令人印象深刻的结果。
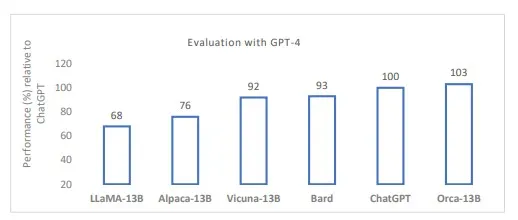
维丘纳可能是最近基于LLaMA作为基础模型衍生出的开源灵活模型的一个很好的替代品。维丘纳-13B是由大学合作创建的聊天机器人,旨在解决现有模型如ChatGPT中缺乏培训和架构细节的问题。经过对使用者共享对话进行微调后,维丘纳的回应质量在使用GPT-4作为评判标准时超过90%,相比之下,与ChatGPT和Google Bard相比。然而,这些早期的开源模型不能用于商业用途。据报道,MosaicML的MPT-7B和科技创新研究院的Falcon 7B可商用的开源模型在质量上与LLaMA-7B相当。
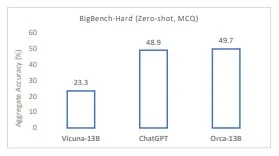
奥卡「在复杂的零射击推理基准测试(如Big-Bench Hard)中,超越了诸如维库纳-13B等传统教学调优模型的成果,提升幅度超过了100%。根据研究人员的说法,在BBH基准测试中,它与ChatGPT-3.5的成绩相当。」奥卡-13B在其他通用模型上的顶级性能加强了巨型模型规模可能源于早期采用蛮力的模型的观点。巨型基础模型的规模对于像奥卡-13B这样的一些较小模型来提炼知识和方法是重要的,但对于推断来说,规模并非必需,即使是对于一般情况也是如此。需要注意的一点是,只有在广泛部署和使用时,才能对模型的认知能力、功能技能和知识记忆进行全面评估。
截至本博客的撰写时,Meta发布了Llama 2模型,其参数数量分别为7B、13B和70B。此次发布距第一代仅四个月,该模型带来了有意义的改进。在比较图表中,灵活的Llama 2 13B模型实现了与之前LLaMA一代的较大模型以及MPT-30B和Falcon 40B模型相似的结果。Llama 2是开源的,可供研究和商业使用。它与微软以及包括英特尔在内的许多合作伙伴紧密合作推出。Meta对于开源模型的承诺和广泛合作必将进一步推动我们正在看到的这类模型在跨行业/学术界改进周期中的快速发展。
敏捷模型的第三个方面与专业化有关。许多新引入的敏捷模型是通用型的,例如LLaMA、维库纳和逆齿鲸。通用的敏捷模型可能仅依赖于它们的参数内存,通过微调方法(包括LLoRA:大型语言模型的低秩适应)和基于检索增强的生成来进行低成本更新,后者在推断时从策划的语料库中实时提取相关知识。检索增强解决方案正在建立,并通过像LangChain和Haystack这样的GenAI框架持续优化。这些框架允许简单灵活地集成索引和有效地访问基于语义的大型语料库。
大多数商业用户更喜欢为自己感兴趣的特定领域调整的定向模型。这些定向模型也倾向于利用所有关键信息资产的检索方式。例如,医疗保健用户可能希望自动化患者沟通。
目标模型使用两种方法:
- 模型本身的专业化与目标用例所需的任务和数据类型相关。可以通过多种方式实现,包括在特定领域知识上预训练模型(类似于phi-1在网络上预训练的教科书质量数据),微调相同大小的通用基础模型(类似于Clinical Camel微调LLaMA-13B),或将庞大模型的精华提炼并学习成一个灵活的学生模型(例如Orca学习模仿GPT-4的推理过程,包括解释轨迹、逐步思考过程和其他复杂指令的学习)。
- 在即時檢索中,對相關數據進行精選和索引,這可能是一個大量的數據,但仍在目標使用案例的範圍/空間內。模型可以檢索公共網絡和私人消費者或企業內容,這些內容是不斷更新的。用戶決定要索引的來源,可以從網絡上選擇高質量的資源,還可以選擇更完整的資源,如個人的私人數據或公司的企業數據。儘管檢索現在整合到了大型和敏捷系統中,但在較小的模型中它扮演著關鍵的角色,因為它提供了模型性能所需的所有必要信息。它還允許企業將所有私人和本地的信息提供給在其計算環境中運行的敏捷模型。
灵活的生成式人工智能模型的优势和劣势
在将来,紧凑型模型的规模可能会上升到200亿或250亿个参数,但仍远远低于1000亿个参数的范围。还有各种中等规模的模型,如MPT-30B、Falcon 40B和Llama 2 70B。尽管预计它们在零样本情况下表现比较小型模型好,但我不认为它们在任何定义的功能集合上会比灵活、针对性强、基于检索的模型表现更好。
与庞大模型相比,灵活模型有许多优势,当模型是有目标和基于检索时,这些优势得到进一步增强。这些好处包括:
- 可持续且较低成本的模型:具有大幅降低训练和推理计算成本的模型。对于集成到全天候使用中的面向业务的模型来说,推理运行时计算成本可能是可行性的决定因素;而在广泛部署中,其显著降低的环境影响也是非常重要的。最后,灵活的模型凭借其可持续、具体和功能导向的系统,并不试图解决人工通用智能(AGI)的雄心勃勃目标,因此在与后者相关的公共和监管辩论中参与较少。
- 更快的微调迭代:较小的模型可以在几个小时(甚至更短)内进行微调,通过LoRA等适应方法向模型添加新信息或功能,这对于灵活的模型非常有效。这使得模型能够更频繁地进行改进周期,始终符合其使用需求。
- 基于检索的模型的好处:检索系统重构了知识,引用大部分信息直接来自于原始来源,而不是模型的参数化记忆。这改进了以下方面:-解释性:检索模型使用源属性,提供信息可追溯性或追溯到信息来源以提供可信度。-及时性:一旦最新的源被索引,它就立即可供模型使用,无需进行培训或微调。这允许持续添加或更新相关信息以实现准实时的检索。-数据范围:用于按需检索的索引信息可以非常广泛和详细。当专注于目标领域时,该模型可以覆盖广泛且深入的公开和私有数据范围。它的目标空间中可能包含比巨型基础模型训练数据集更多的数据量和细节。-准确性:直接访问原始数据的形式、细节和上下文可以减少幻觉和数据近似。只要答案在检索范围内,它可以提供可靠完整的答案。对于较小的模型来说,检索根据需求检索的可追溯策划信息与记忆信息(如巨型模型)之间的冲突更少,记忆信息可能过时、部分或没有来源标注。
- 硬件选择:敏捷模型的推断可以在任何硬件上实现,包括可能已经是计算环境一部分的无处不在的解决方案。例如,Meta的Llama 2敏捷模型(7B和13B参数)在Intel的数据中心产品上运行良好,包括Xeon、Gaudi2和Intel数据中心GPU Max系列。
- 集成、安全和隐私:如今,ChatGPT和其他巨型GenAI模型通常是独立的模型,运行在第三方平台的大型加速安装上,并通过接口进行访问。灵活的AI模型可以作为嵌入到更大的商业应用程序中的引擎运行,并完全集成到本地计算环境中。这对安全和隐私产生了重大影响,因为不需要与第三方模型和计算环境交换/暴露信息,并且可以将更广泛应用程序的所有安全机制应用于GenAI引擎。
- 优化和模型简化:通过量化等优化和模型简化技术可以将输入值转换为较小的输出值,从而减少计算需求,这在灵活模型上显示出了强大的初始结果,并提高了能源效率。
一些敏捷模型的挑战仍值得一提:
- 任务范围的减少:通用巨型模型具有出色的适用性,尤其在以前未考虑的零样例新用途方面表现出色。灵活系统能够实现的广度和范围仍在评估中,但近期模型的表现似乎有所提高。针对性模型假设在预训练和/或微调期间已知并定义了任务范围,因此范围的减小不应影响任何相关能力。针对性模型不是单一任务,而是一系列相关功能。这可能会导致任务或业务特定的灵活模型而产生碎片化。
- 可能通过少量微调来改进:为了使模型能够有效地解决特定领域的问题,不一定总是需要进行微调,不过微调可以通过调整模型以适应应用所需的任务和信息来提高人工智能的效果。现代技术使得这个过程可以通过少量的示例完成,而无需深入数据科学专业知识。
- 检索模型需要索引所有的源数据:模型通过索引映射在推理过程中获取所需的信息,但存在错过信息源的风险,使其对模型不可用。为确保来源、可解释性和其他属性,目标检索模型不应依赖于存储在参数内存中的详细信息,而应主要依赖于可在需要时提取的索引信息。
简介
生成式人工智能的重大突破使得新的功能成为可能,例如AI代理以简单的语言进行对话、概括和生成引人入胜的文本、图像创作、利用以前迭代的背景等等。本博客介绍了“灵活的AI”这一术语,并说明了为什么它将成为规模化部署GenAI的主导方法。简单来说,灵活的AI模型运行速度更快,通过持续微调更容易刷新,并且通过开源社区的集体创新更容易跟上技术快速改进周期。
随着多个示例的证明,最大模型演变过程中展现的出色性能表明,灵活的模型并不需要像庞大的模型那样庞大的体量。一旦掌握了基本的认知能力,调整了所需功能并提供了相应的数据,灵活的模型为商业世界提供了最高价值。
那么,灵活的模型并不会使庞大的模型灭绝。庞大的模型仍然有望在零-shot(无需样本训练),开箱即用的情况下表现更好。这些庞大的模型也可以用作小型、灵活模型的来源(教师模型)进行蒸馏。虽然庞大的模型拥有大量额外的记忆信息来解决任何潜在的用途,并且具备多种技能,但大多数GenAI应用并不需要这种普遍性。相反,能够针对领域相关的信息和技能对模型进行精细调节的能力,以及从策划的本地和全球资源中检索最新信息的能力,对于许多应用来说将是一个更好的价值主张。
将敏捷、有针对性的人工智能模型视为可嵌入任何现有应用程序的模块,提供了一个非常有吸引力的价值主张,包括:
- 部署和运营所需成本仅为原本的一小部分。
- 适用于任务和个人/企业数据。
- 可随时更新,可在任何硬件上运行,包括CPU、GPU或加速器。
- 集成到当前计算环境和应用中。
- 在本地环境上运行或在私有云中运行。
- 所有安全和隐私设置的好处。
- 更高的准确性和可解释性。
- 在提供类似水平的生成 AI 能力的同时,更加注重环境责任。
令人印象深刻的进步将在少数几个巨型模型上持续发展。然而,该行业很可能只需要几十个通用敏捷基础模型,这些模型可用于构建无数个具体的版本。我预见在不久的将来,先进的通用人工智能将在各个行业广泛应用,主要是通过整合敏捷、具有针对性的安全智能模块作为其增长引擎。
参考资料
- 曾品凯(2023年3月1日)。TrendForce表示,随着云公司发起人工智能竞赛,ChatGPT对GPU的需求预计将达到3万颗芯片,准备商业化。TrendForce。https://www.trendforce.com/presscenter/news/20230301-11584.html
- 介绍MPT-7B:开源商用LLMs的新标准。 (2023年5月5日)。https://www.mosaicml.com/blog/mpt-7b
- Mukherjee, S., Mitra, A., Jawahar, G., Agarwal, S., Palangi, H., 和 Awadallah, A. (2023). Orca: 从GPT-4的复杂解释轨迹中进行渐进式学习. arXiv (康奈尔大学). https://doi.org/10.48550/arxiv.2306.02707
- 沃尔夫勒姆,S.(2023年3月23日)。ChatGPT获得其“沃尔夫勒姆超能力”!斯蒂芬·沃尔夫勒姆文集。https://writings.stephenwolfram.com/2023/03/chatgpt-gets-its-wolfram-superpowers/
- 谢赖纳,M. (2023年7月11日)。GPT-4架构、数据集、成本以及更多泄露。THE DECODER. https://the-decoder.com/gpt-4-architecture-datasets-costs-and-more-leaked/
- ChatGPT 插件。 (无日期)。https://openai.com/blog/chatgpt-plugins
- Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., & Grave, E. (2021). 无监督密集信息检索与对比学习. arXiv (康奈尔大学). https://doi.org/10.48550/arxiv.2112.09118
- Mallen, A., Asai, A., Zhong, V., Das, R., Hajishirzi, H., and Khashabi, D. (2022). 当不信任语言模型:探究参数化和非参数化记忆的有效性。arXiv(康奈尔大学)。https://doi.org/10.48550/arxiv.2212.10511
- Papers with Code — PopQA数据集。 (无日期)。https://paperswithcode.com/dataset/popqa
- 介绍LLaMA:一种基础的语言模型,参数达到650亿。(2023年2月24日)。https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
- 介绍猎鹰LLM。 (无日期)。https://falconllm.tii.ae/
- Nijkamp, E., Hayashi, H., Xie, T., Xia, C., Pang, B., Meng, R., Kryscinski, W., Tu, L., Bhat, M., Yavuz, S., Xing, C., Vig, J., Murakhovs’ka, L., Wu, C. S., Zhou, Y., Joty, S. R., Xiong, C., and Savarese, S.(2023年)。使用XGen进行长序列建模:一个7B LLM在8K输入序列长度上进行训练。Salesforce AI Research。https://blog.salesforceairesearch.com/xgen/
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. (2021年6月17日). LoRA: 大型语言模型的低秩适应. arXiv (康奈尔大学). https://doi.org/10.48550/arXiv.2106.09685
- 刘易斯(Lewis)、佩雷斯(Perez)、皮克图斯(Piktus)、佩特罗尼(Petroni)、卡普金(Karpukhin)、戈亚尔(Goyal)、库特勒(Küttler)、刘易斯(Lewis)、伊亚(Yih)、洛克塔舍尔(Rocktäschel)、里德尔(Riedel)和基拉(Kiela)(2020)。用于知识密集型自然语言处理任务的检索增强生成。NeurIPS 2020。[链接](https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html)
- 介绍LangChain。 (n.d.). https://python.langchain.com/docs/get_started/introduction.html
- 隐形外套。 (n.d.). https://www.haystackteam.com/core/knowledge
- 马实质。(2023)。《如何使用Haystack和LangChain增强大型语言模型》。马实质。https://mantiumai.com/blog/how-haystack-and-langchain-are-empowering-large-language-models/
- Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. (2023年3月13日). Alpaca: 一种强大、可复制的指令追随模型. 斯坦福大学CRFM. https://crfm.stanford.edu/2023/03/13/alpaca.html
- Geng, X., Gudibande, A., Liu, H., Wallace, E., Abbeel, P., Levine, S. and Song, D. (2023年4月3日). Koala: 一种用于学术研究的对话模型. 伯克利人工智能研究博客. https://bair.berkeley.edu/blog/2023/04/03/koala/
Chiang, W. L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J. E., Stoica, I., and Xing, E. P. (2023年3月30日)。Vicuna: 一个开源的聊天机器人,以90%*的ChatGPT质量给GPT-4留下深刻印象。LMSYS Org。[https://lmsys.org/blog/2023-03-30-vicuna/](https://lmsys.org/blog/2023-03-30-vicuna/)
Meet Vicuna: The Latest Meta's Llama Model that Matches ChatGPT Performance
Rodriguez, J. (2023, April 5). Medium. https://pub.towardsai.net/meet-vicuna-the-latest-metas-llama-model-that-matches-chatgpt-performance-e23b2fc67e6b
遇见维丘纳:最新的 Meta 天竺骆驼模型,可与 ChatGPT 的表现匹敌
Rodriguez, J.(2023 年 4 月 5 日)。Medium。 https://pub.towardsai.net/meet-vicuna-the-latest-metas-llama-model-that-matches-chatgpt-performance-e23b2fc67e6b
- Papers with Code — BIG-bench数据集。 (无日期)。https://paperswithcode.com/dataset/big-bench
- . (2023年7月18日). Meta和Microsoft推出下一代Llama。Meta. https://about.fb.com/news/2023/07/llama-2/
- 元神智能。 (无日期)。 介绍Llama 2。 https://ai.meta.com/llama/
- Gunasekar、Zhang、Aneja、Mendes、Allie、Gopi、Javaheripi、Kauffmann、Gustavo、Saarikivi、Salim、Shah、Behl、Wang、Bubeck、Eldan、Kalai、Lee和Li(2023年)。教科书是你所需的一切。arXiv(康奈尔大学)。https://doi.org/10.48550/arxiv.2306.11644
Toma, A., Lawler, P. R., Ba, J., Krishnan, R. G., Rubin, B. B., 和 Wang, B. (2023)。Clinical Camel: 一个带有基于对话的知识编码的开源专家级医学语言模型。arXiv (康奈尔大学)。https://doi.org/10.48550/arxiv.2305.12031
- 帕特尔,D.,以及艾哈迈德,A.(2023年5月4日)。谷歌“我们没有堡垒,OpenAI也没有。”SemiAnalysis。https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
- 加速Llama 2:利用英特尔 AI 硬件和软件优化功能。(n.d.). 英特尔。https://www.intel.com/content/www/us/en/developer/articles/news/llama2.html
- 较小更好:Q8-Chat,一种在Xeon上高效生成的AI体验。 (n.d.). Hugging Face. https://huggingface.co/blog/generative-ai-models-on-intel-cpu