解读NVIDIA的人工智能芯片主导地位
明天人工智能领域的蓝图

介绍
曾被称为游戏玩家的终极装备,NVIDIA的GPU现已成为推动全球最尖端人工智能企业的驱动力。
AI行业对于为强大的大型语言模型(LLM)量身定制的芯片充满了兴奋。这一热潮吸引了许多敏捷的初创企业和行业巨头,如AMD和英特尔,它们都争夺市场份额。但这个故事听起来似曾相识:许多过去和现在的竞争者们试图超越英伟达,却发现领先就像是抓住瓶中的闪电一样困难。要打破英伟达的壁垒,需要的不仅仅是重复利用的策略,还需要对英伟达DNA中深深嵌入的原则有深刻的理解。
NVIDIA在人工智能世界中的崛起不仅仅源自创新,更扎根于其对核心价值的坚守。在我们接下来的深入探讨中,“解读NVIDIA的AI芯片主导地位”,我们将跳过噪音,专注于节奏。我们将聚焦那些贯穿NVIDIA旅程的基本原则。虽然这个故事可能被许多人忽略,但关注它可能会让我们窥探人工智能未来的方向。
解码GPU的AI之旅
从游戏世界到人工智能的未来
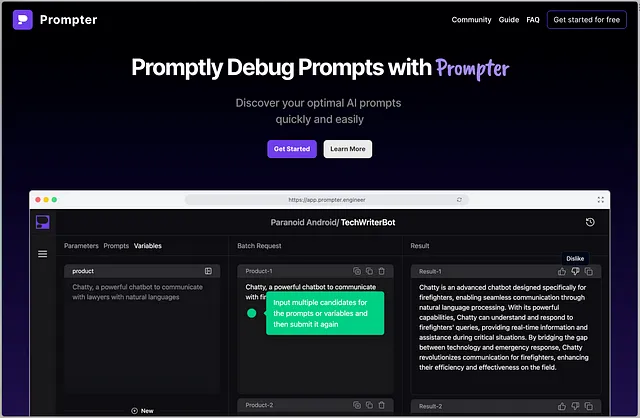
在深入讨论GPU和人工智能之前,了解它们的根源是至关重要的。最初,GPU悄然为游戏和电影中的图形提供动力,处理从顶点到像素的所有内容。但随着对高级图形的渴望不断增强,GPU经历了一次演变,引入了可定制的用于单个顶点或像素的"着色器"。这不仅仅是一种进步,而是一种改变游戏规则的力量。今天游戏中的惊人视觉效果超越了传统的图形规范,见证了这一卓越的演变。
着色器核心的演变
着色器核心最初有一个简单的任务:运行指定图形功能的着色器。然而,随着图形变得更加复杂,这些核心进行了适应。它们扩展了自己的功能,不仅限于3D图形,开创了通用GPU(GPGPU)计算的时代。在人工智能占据中心舞台之前,GPGPU在高性能计算(HPC)领域已经取得了显著的进展。着色器核心现在不仅处理“着色器”,还处理HPC应用程序的“内核”。这种演变在像Summit和Sierra这样的超级计算机上得到了体现,它们都由NVIDIA的Volta GPU推动。这些不仅仅是在HPC方面树立了标准,它们也象征着人工智能对GPGPU的日益关注。
在专业化与多才多艺之间取得平衡
创造一个GPU就像指挥一支交响乐团一样。这是一场精密和和谐的舞蹈。一方面,我们可以找到专门设计用于精确角色的专用单元。在相反的光谱上,多功能的着色器核心准备好拥抱各种功能。纹理和特殊功能单元(SFU)不仅仅是机器中的齿轮;它们是基石,专门从事不同的领域。它们的本质不仅仅是原始动力,而是与着色器程序的无缝协作,优化特定任务。随着人工智能的发展,NVIDIA引入的张量核心体现了GPU将专业能力与适应性相融合的传统。简而言之,许多人现在称之为领域特定架构(DSA)深深扎根于GPU的DNA中。
随着我们转向下一个部分,我们的镜头聚焦于矩阵乘法,这是人工智能的基石。这是一个关于基础计算机架构如何与人工智能的迅猛崛起交织在一起的故事,为科技的下一个重大飞跃铺平了道路。
解锁AI的力量:矩阵乘法掌握
解密计算机架构的核心
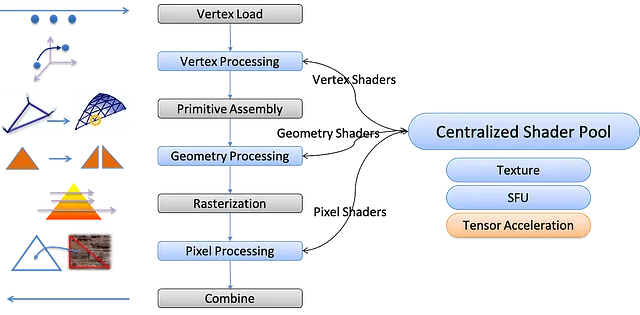
在计算机体系结构的编年史上,一个关键的真理浮现出来:往往,在数据传输中涉及的能量和时间超过了原始计算本身。这种理解推动了追求在最小化数据洗牌的同时放大计算输出的设计的探索。在这个努力的前沿是矩阵乘法,通常被称为MatMul。
思考一下乘以两个N × N矩阵的问题。这个操作大约需要N³个乘积累加(MAC)操作,但只需从内存中提取2N²个数据位。计算与通信的比率为N/2,随着N的增加而增加,凸显出每字节的卓越计算密度或“算术强度”。鉴于这种高效的比率,MatMul成为了强化优化的主要候选,涵盖了硬件和算法两个方面的优化维度。
矩阵相乘的重要性引发了一个有趣的思考:是否可以将各种算法重塑成适应矩阵相乘蓝图的形式?尽管乍一看矩阵相乘似乎是专业化的,但它固有的高效性激发了更广泛的可能性领域。
这个概念在HPC领域获得了强有力的支持。他们结合自己广泛的专业知识,巧妙地重塑了各种任务,使其与MatMul的框架相匹配,利用精细的MatMul库的能力,绕过硬件的复杂性。
AI与矩阵乘法的舞蹈
在AI的无边宇宙中,梦想触摸星辰,HPC经常充当指路明灯。借鉴HPC的成就,AI先驱者正在微调各种算法,与MatMul框架无缝对齐。这一举措不仅突显了MatMul在技术舞台中的关键角色,还展示了其多功能性,提醒我们在AI领域,我们可以取得无限的成就。
跳入AI领域,人们对机器学习(ML)的设置议论纷纷。这些设置并不是普通的设置;它们充斥着错综复杂的神经层。在每个人都对卷积神经网络(CNN)感到兴奋之前,多层感知机(MLP)是主要角色。它全都与矩阵-向量乘法(MVM)有关。但是MVM存在一个问题:它的算术密集度并不是顶尖的,导致在庞大数据集上进行大量的MAC运算,没有多余的空间进行数据重用。然后,在CNN中引入了张量卷积,就像这样,MatMul开始抢夺风头,展示其灵活的特点。
现在,有一群人在推动CNNs,在计算机视觉领域取得了重大突破。然后我们有了Transformer模型——把它当作MatMul的粉丝俱乐部主席——在自然语言处理领域掀起了波澜。你可以感受到这种人工智能领域的巨大变革。当你看到大型语言模型(LLM)背后的大脑们,尝试处理更长的序列和扩展的词汇表时,他们正在进行一些高级的MatMul技巧。将标记转化为数字计算的过程?这只是MatMul在人工智能领域不断发展的又一个篇章。
矩阵相乘难题:英伟达的无与伦比之路
尽管MatMul在AI芯片设计策略中占据中心舞台,但一个问题在空中悬浮着。随着NVIDIA的强势崛起,充分利用了MatMul的优势,一个燃烧的问题浮现出来:在这个以MatMul为重点的时代,为什么其他AI芯片设计者没有达到甚至超过NVIDIA的崛起,尤其考虑到MatMul内部的巨大潜力?
从矩阵乘法的掌握到GPU的主导地位
超越仅仅矩阵乘法
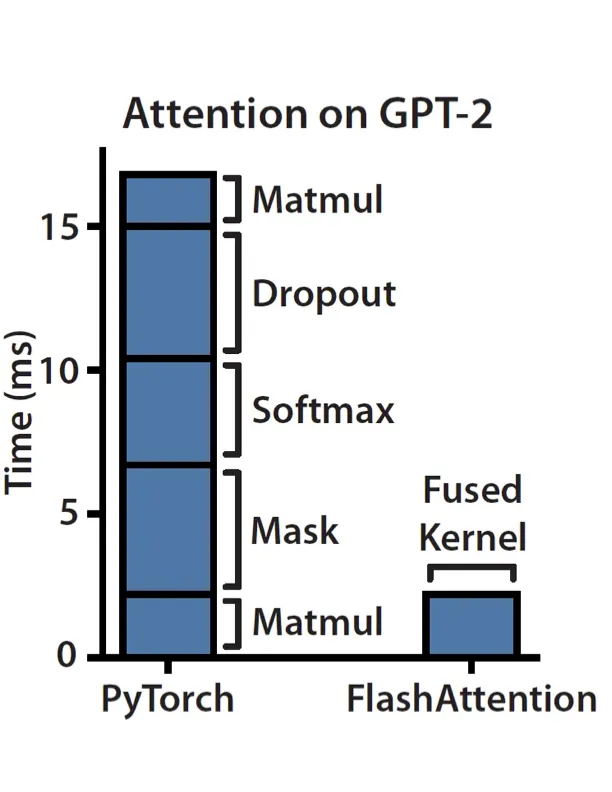
矩阵乘法,或者酷孩子们称之为MatMul,在AI计算中扮演着重要的角色。但是,AI的故事不仅仅只有MatMul。我们还有关键的操作,像逐元素和缩减函数,这些都增加了情节的转折。让我们来解释一下:逐元素函数(如激活函数)聚焦于矩阵或张量的各个元素,而不改变它们的形状。缩减函数呢?它们涉及到对张量数据维度进行压缩,比如softmax就是一个流行的例子。但是这里最关键的是:这些操作有时可能会对性能造成一定的拖累,尤其是当你看到浮点运算每秒(FLOPS)的效率时。如果你曾经想过像LLMs这样的大型智能模型中那些“注意力”部分的挑战,这就是真实的地方。
回到2019年,赫奈斯和帕特森聚焦于领域特定架构(DSA),讨论了如何通过定制指令集和内存布局来优化其性能。他们以谷歌的TPU v1作为主要的DSA示例。从理论上讲,这听起来是完美的。但在实践中,人工智能计算经常会偏离这条完美的路径。许多作为DSA设计的人工智能芯片过于专注于特定的MatMul操作。它们确实会考虑非MatMul任务,并根据当时热门的神经网络进行调整。但在这样做的过程中,它们可能会限制自身的适应能力。想象一下:如果一个DSA设计完全针对ResNet或Yolo等卷积神经网络,那么当面对Transformer-style LLMs时,它会感到力不从心。这就好像为马拉松比赛做准备,然后被告知这是一个接力赛!
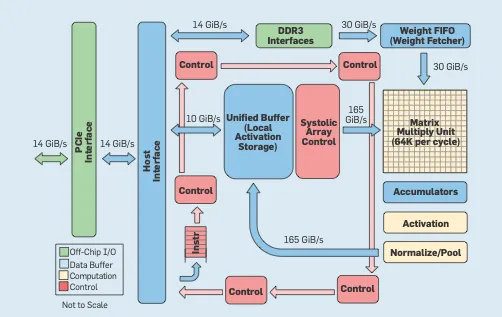
释放MatMul火力:GPU如何以软件为先的方式展开
跳入GPU的世界,它们关注的是整个人工智能的大局而非单个像素的沉迷。它们携带着一套丰富的指令集 - 实际上就是硬件的一套独特工具箱。这给开发者提供了一个充满操作的游乐场。再加上一个智能的存储系统,其中存储和获取数据在快速(但昂贵)的片上存储器(SRAM)与其他较慢(但更便宜)的位置之间进行平稳的切换。结果呢?超适应性的计算机能够精准地存储数据。
现在,这种适应性使得GPU专家能够发挥极强的创造力。他们正在努力确保在性能障碍方面,主要挑战的是MatMul操作。通过推出智能软件技巧,他们减少了非MatMul任务造成的性能滞后,并提高了输送到MatMul操作中的FLOPS。以很酷的创新项目Flash Attention为例。它的关键是将矩阵分解成适合快速加载到芯片上的SRAM。还有专门用于softmax计算等的全新算法,GPU就是为了将MatMul放在重点推广。
桥接两个世界:软件灵活性与硬件进化的结合
当我们看到科技领域时,软件的快速发展与芯片技术的渐进发展之间存在明显的分歧。可以想象成这样:如果软件世界像一辆高速汽车,芯片技术则像一辆稳定可靠的火车。两者都在前进,但速度不同。如果仅仅基于当前软件趋势来设计芯片,就有点像把所有筹码(双关语)都押在这个时刻永远持续下去的赌注上。但由于科技始终处于不断变化中,那些传统的设计仿真分析(DSA)可能会被落下,不得不匆忙适应新的挑战。
但是这才是关键:一个芯片的真正价值不仅仅在于它能很好地完成整个矩阵乘法的任务,甚至不仅仅在于它能完美地适应一组特定的操作。黄金在于给开发者提供一个瑞士军刀般的工具,激发对不仅仅关注矩阵乘法任务的创新。
输入NVIDIA的GPU。当灵活的硬件与尖端的软件完美结合时,这些强大的家伙是这种情况的典范。它们已经开发了一种许多主流数据科学家似乎忽视的人工智能方面,展示了当你对人工智能硬件拥有广泛视野时会发生的魔力。
GPU难题:为何NVIDIA脱颖而出
在实际情况下,英伟达并不是唯一的重要GPU游戏参与者。还有其他一些拥有类似技术工具和专业知识的大牌选手。理论上讲,它们应该和英伟达齐头并进,对吧?然而,当我们看市场时,英伟达就像明星四分卫,而其他厂商还在摸索。这种显著差异,即使每个人都对GPU架构赞不绝口,也给我们提供了深入探究的舞台。为什么英伟达如此辉煌,而其他厂商似乎陷入了阴影中?让我们深入挖掘一下。
AMD的AI挑战
AMD vs. NVIDIA:人工智能架构差异
NVIDIA在利用GPU能力进行人工智能方面的成就是无与伦比的,将其确立为行业的黄金标准。然而,尽管拥有强大的GPU设计,像AMD这样的强大竞争对手却没有达到NVIDIA在人工智能领域的里程碑。这种差异不仅仅是由于技术上的差异,而是源于多种原因的汇集,包括市场营销举措、远见的方向、战略合作、历史优势以及他们开发者社区的强大实力。为了真正理解这种差异的根源,我们需要聚焦于正在发挥作用的基本战略。
这场讨论的核心是一个引人注目的事实:与NVIDIA相比,AMD在人工智能领域的发展轨迹似乎不够有目标且不够协调,这从它们采取的明显架构课程中可以看出来。NVIDIA巧妙地将其对人工智能的承诺与统一的架构方法相结合,而AMD似乎陷入两难境地,将资源分散到了用于人工智能和计算目的的CDNA和用于以图形为中心任务的RDNA上。
两种架构的故事:NVIDIA的人工智能实力对比AMD的分歧
请考虑以下事实:NVIDIA生态系统以Tensor Core的强大能力闻名,专为人工智能计算而设计。作为将人工智能与图形融合的先驱,NVIDIA推出了诸如DLSS(深度学习超级分辨率)和基于人工智能的光线追踪降噪等创新技术,而AMD的对策似乎有些保守。他们采用了更传统、人工智能之前的超分辨率策略,对光线追踪的重视也稍显低调,这显示出组织或领导层在人工智能方面的热情不及。与NVIDIA在整体架构上竞争的挑战是巨大的,但当资源和重点分散时,这些挑战就会进一步增加。
保护开发人员的投资:一代人的节奏
早些时候,我们深入探讨了硬件在为开发者提供丰富工具的过程中的重要性。但问题在于:仅仅拥有工具是不够的。掌握一个平台是一个漫长的过程,需要严肃的头脑和时间投入。NVIDIA以其专注于人工智能的方法,不仅提供开发工具,而且承诺:你今天构建的东西将在我们明天带来的东西的推动下变得更好。为某一代NVIDIA设计的应用程序随着技术的升级而升级,通常在新的设备上运行得更加流畅。这种不断提升的游戏水平意味着无论开发者投入多少时间和智慧来创建基于NVIDIA的作品,都是一项可靠的投资,即使新技术推出。这种天才的循环是NVIDIA的成功秘诀,使他们保持在游戏行业的顶尖地位。虽然有些人可能考虑转向其他平台,但是对NVIDIA的生态系统的舒适和信任使得即使考虑开始其他地方也变得困难。
让GPU编程变得更易学:NVIDIA的秘密武器
但这不仅仅是关于拥有硬件工具包的问题,更重要的是使其易于使用。从头开始编写GPU代码?这是一项艰巨的任务。NVIDIA清楚这一点,这正是他们与AMD等竞争对手有优势的地方。NVIDIA拥有大量的加速库,其中包括以“cu”为前缀的宝石,如cuDNN和cuBLAS。它们使进入GPU世界变得更加友好,而另一方面,缺乏这些资源使得采用AMD GPU变得相当困难。
设置AI趋势:NVIDIA的远见行动
现在,让我们稍微转换一下思路。NVIDIA不仅在硬件领域称霸,而且在引领人工智能的方向上也表现出色。他们不仅跟得上潮流,还在给予引领。就拿H100来说吧,这个厉害的家伙经过精密设计,专为大型语言模型而生,并且在ChatGPT掀起波澜之际登场。当NVIDIA在做出这些强大举措时,AMD却落后了,并没有回应H100的卓越表现。NVIDIA对人工智能场景的预测能力和塑造力使他们独树一帜。对于大多数人来说,考虑转换到其他平台只不过是幻想,因为NVIDIA正在领导这场变革。
NVIDIA 的最终战略:引领人工智能的进步道路
NVIDIA 领先愿景:人工智能的下一个地平线
在人工智能的精密芭蕾舞中,软件和硬件在一场永恒的创新华尔兹中纠缠在一起,NVIDIA不仅仅是另一个舞者 - 他们引领整个演出。他们的策略是什么?加强GPU技术,并定义人工智能演化的轨迹。通过预测并与新颖的算法浪潮无缝对齐,NVIDIA总是领先一步。他们的技术不仅解决当前人工智能的挑战,还精确绘制了明天科技的路线图。让我们更深入地了解这种具有远见的方法,加强NVIDIA在人工智能领域的主导地位。
NVIDIA的H100:超越传统DSA范式
NVIDIA的H100不仅仅是又一个芯片;它是一种声明。虽然它与DSA的氛围相呼应,尤其是它强大的MatMul游戏,但NVIDIA的玩法不同。他们不仅仅在冲浪AI浪潮;他们是创造浪潮的人。在AI传奇中,NVIDIA不是一个普通的角色;他们是故事的讲述者。当开发者感到他们从A100的MatMul中挤取了所有可能性之后,他们自然而然地渴望更多。数字讲述了故事:A100的张量核心计算与带宽的比例为每TB/s的156 TOPS。但是有了H100呢?这一比例飙升至惊人的298。这不仅仅是一个数字;它是朝着处理更大矩阵任务的明确转变。而当你看到原始的力量,张量核心和着色器核心之间的平衡时,重点是不言而喻的。
此外,随着在其H100中发布FP8,NVIDIA展示了创新的另一次飞跃。尽管这种格式比传统的32位和16位浮点数更紧凑,但它让人联想到一辆高性能汽车,以更高的燃油效率提供惊人的速度。正是这种效率和能力,正是FP8带给人工智能世界的。随着更广泛的人工智能社区开始认识到其潜力,NVIDIA已经开创了其使用,并巩固了其在人工智能进步的前沿地位。
总结思考:超越NVIDIA的主导地位
在人工智能的不断发展中,NVIDIA作为一个杰出的领导者,以无缝集成硬件和软件创新而闻名。他们的创新能力引发了重要的问题:学术研究人员能否自由地访问他们的庞大资源而不受限制?内容创作者能否在无压力的情况下创作出最好的作品?当一家公司拥有如此大的影响力时,新兴的元宇宙能否真正实现民主化?过分依赖单一实体可能限制多样化的观点,阻碍探索,并集中权力,可能危及一个普遍包容和变革性未来。
建筑基础:源自Hennessy和Patterson的洞察
亨尼斯和帕特森,计算机架构领域的知名人物,提出了三个架构原则:
- 软件创新可以开辟新的建筑方向。
- 强化硬件和软件之间的协同作用可以带来突破性的发现。
- 更广泛的用户群最终决定了哪些建筑设计成为主流。
理解NVIDIA的策略:预见和适应
为了与NVIDIA进行有效竞争,理解其战略决策至关重要,包括硬件进展和软件创新方向。这需要对新兴趋势进行敏锐观察,深入研究NVIDIA过去的选择,并对其潜在未来动向有预见性。凭借这些知识,竞争对手可以制定策略,要么与NVIDIA的成就保持一致,要么超越其成就。
这里的一个关键洞察力在于NVIDIA在软件创新方面的主动参与,这有可能重塑架构方向,体现了第一条架构原则。
“De-CUDA”转变:人工智能发展的重大转型
AI行业正在发生一个值得注意的转变,特别是在大型语言模型(LLMs)的开发领域中表现得尤为明显。这种转变正在引导开发者转向像PyTorch这样的平台,标志着传统对NVIDIA的CUDA的依赖的消失。这个被称为"去CUDA"运动的过渡不仅仅代表了一种短暂的趋势,更凸显了行业追求提供更高灵活性和效率的工具的共同努力。随着人工智能的进步,它引入了额外的抽象层,赋予开发者和研究人员在处理复杂性、简化工作流程和推动创新方面的熟练能力,同时避开了底层系统的复杂性。这一运动令人着迷的一个方面是Triton的整合,为在PyTorch生态系统中编写GPU核心函数提供了一条途径。随着这些复杂平台的崛起,人工智能芯片设计师面临着一个非凡的机会,模拟NVIDIA软件和硬件协同的成功合作。
这种转变强调了关键的行业观点:优化硬件和软件之间的协同作用可以打开人工智能创新的新途径,与第二个架构原则产生共鸣。
重新构想GPU的格局
在人工智能不断发展的动态世界中,像特斯拉、GraphCore、Esperanto和Tenstorrent等公司正在多样化其方法,倾向于采用利用CPU核心网状结构的架构。与此同时,像SambaNova这样的实体也在尝试另类设计,比如粗粒度可重组阵列(CGRA)。虽然GPU凭借其高效能和强大性能仍然是首选之一,但是CPU核心为中心的设计的探索提供了一个有趣的变化。然而,对于NVIDIA的竞争对手来说,避免“好锤子综合症”,并且对GPU架构的潜力进行批判性评估是至关重要的。市场对GPU的倾向证明了其在人工智能任务中的功效。例如,NVIDIA的H100表示其在这一领域进一步改进和创新的承诺。
这种演变凸显了第三个架构原则:市场将始终是最终的裁判,确定未来哪些架构设计能崭露头角,以应对不断演化的需求和挑战。
拥抱人工智能训练
从Hennessy和Patterson的洞察力中汲取灵感,出现了一项新的第四个架构原则来闭环:
获胜的架构推动着软件进步的下一波浪潮。
在人工智能快速发展的领域中,新的人工智能模型的快速涌现导致对与训练芯片兼容的推理芯片的偏好。这种架构的统一促进了下一代软件的突破。仅仅关注人工智能推断就如同在熟悉的领域中导航,然而NVIDIA的一些竞争对手忽视了在人工智能训练中的参与。这种观点需要转变,因为人工智能训练在推动软件创新方面起着至关重要的作用。即将到来的软件进步将与人工智能训练的进展密切相关。因此,领先的架构不仅必须拥抱其复杂性,而且还要立志成为新兴软件创新的基础平台。