人工智能如何改变我们编码的方式
从ChatGPT和Stack Overflow的证据

简而言之:本文将为您提供我关于人工智能和工作的最新研究摘要(探讨人工智能对生产力的影响并开展对长期效果的讨论),并通过使用ChatGPT和Stack Overflow进行的准实验方法(差异分析法)示例,了解如何通过简单的SQL查询从Stack Overflow提取数据。
链接到完整的科学文章(请引用):https://arxiv.org/abs/2308.11302
与大多数技术革命一样,ChatGPT的发布伴随着迷惑和恐惧。一方面,在短短两个月内,这个应用拥有1亿活跃用户,打破了历史上增长最快的消费者应用记录。另一方面,高盛的一份报告声称这种技术可能会在全球范围内替代超过3亿个工作岗位。此外,埃隆·马斯克与1,000多位科技领袖和研究人员签署了一封公开信,呼吁对最先进的人工智能发展进行暂停。
我们只能看到前方的短距离,但我们能看到许多需要完成的事情。- Alan Turing
根据艾伦·图灵的说法,本文并不试图过于英勇地预测人工智能及其影响的遥远未来。然而,我专注于其中一个主要的可观察后果,即人工智能如何改变我们的编码方式。
世界因ChatGPT的问世而改变。至少对于一个每天都在编码的人来说,我的世界一夜之间改变了。不再花费几个小时在谷歌上寻找正确的解决方案,或是深入研究Stack Overflow上的答案,并将解决方案翻译成符合我具体问题的正确变量名和矩阵尺寸,我只需要询问ChatGPT。这个聊天机器人不仅能立刻给我一个答案,而且这个答案完全适合我的具体情况(例如正确的名称、数据框维度、变量类型等)。我震惊了,我的生产力突然提升了。
因此,我决定探索ChatGPT发布的大规模影响以及它对生产力和我们工作方式的潜在影响。我使用Stack Overflow的数据来验证了三个假设(Hs)。
ChatGPT 减少了在 Stack Overflow 上提出的问题数量。如果 ChatGPT 能在几秒钟内解决编码问题,我们可以预期编码社区平台上提问和获得答案所需的时间将会减少。
H2: ChatGPT提高了提问的质量。如果大规模使用ChatGPT,则Stack Overflow上剩下的问题必须更好地记录,因为ChatGPT可能已经有所帮助。
剩下的问题更复杂。我们可以预料到剩下的问题更具挑战性,因为它们有可能无法由ChatGPT回答。因此,我们正在测试未回答问题的比例是否增加,以验证这一点。此外,我还测试每个问题的浏览次数是否有所变化。如果每个问题的浏览次数保持稳定,那将是另一个迹象,表明剩下的问题的复杂性增加,并且这一发现不仅仅是由于平台上活动减少所引起的。
为了测试这些假设,我将利用ChatGPT在Stack Overflow上的突然发布。在2022年11月,当OpenAI公开发布他们的聊天机器人时,没有其他可行的选择(例如Google Bard),而且访问是免费的(不像OpenAI ChatGPT 4或Code Interpreter那样限于付费订阅)。因此,我们可以观察在线编程社区在冲击之前和之后的活动如何变化。然而,尽管这个冲击有多“清洁”,其他影响可能会混淆,因此对因果关系提出质疑。特别是季节性(例如发布后的年底假期)以及问题越新,被查看次数越少,并且找到答案的可能性越低。
理想情况下,为了减轻季节性等可能存在的混杂变量的影响并测量因果效应,我们希望能观察在没有ChatGPT发布的情况下的世界,然而这是不可能的(例如因果推断的基本问题)。尽管如此,我将利用ChatGPT在与编码相关问题上回答质量在不同语言间存在差异的事实,并使用准实验方法来限制其他因素对效应的混淆风险(差异法)。
为了做到这一点,我将比较Stack Overflow上Python和R的活动情况。Python是一个显而易见的选择,因为它可以说是最受欢迎的编程语言之一(例如,在TIOBE编程社区指数中排名第一)。Python在线资源的丰富提供了ChatGPT等聊天机器人的丰富训练素材。现在,与Python进行比较,我选择了R。Python通常被认为是R的最佳替代品,两者都可以免费使用。然而,R相对不那么受欢迎(例如,在TIOBE编程社区指数中排名第16位),因此训练数据可能较少,这意味着ChatGPT的性能较差。个人经验证实了这种差异(有关方法的更多细节请参见方法部分)。因此,R对于Python来说是一个有效的反事实情况(它受到季节性影响,但我们可以预期ChatGPT的影响可以忽略不计)。
Overflow (figure by the author)
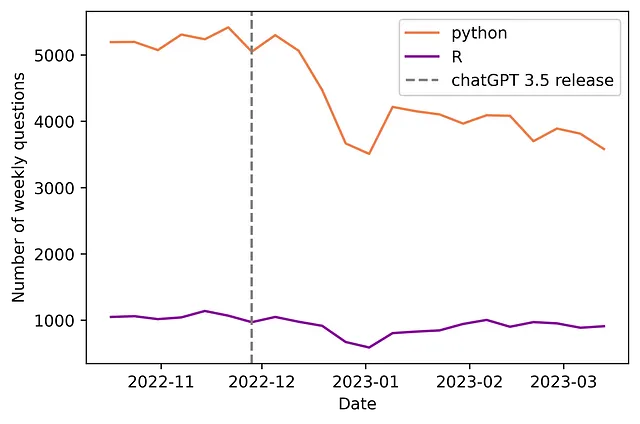
上图展示了原始的每周数据。我们可以看到,在ChatGPT 3.5发布后,关于Python每周在Stack Overflow上提问数量出现了突然而重要的下降(21.2%),而对R的影响相对较小(下降了15.8%)。
这些“定性”观察结果得到了统计模型的证实。随后描述的计量经济模型发现,对于在Stack Overflow上的Python,每周问题数量平均下降了937.7个(95%置信区间:[-1232.8,-642.55];p值= 0.000)。随后的分析利用Diff-in-Diff方法进一步揭示了问题质量的改善(通过平台上的评分来衡量),以及未解答问题比例的增加(而每个问题的平均观看次数似乎没有变化)。因此,该研究提供了对先前定义的三个假设的证据。
这些研究结果凸显了人工智能在我们工作方式中的深远作用。通过回答例行查询,生成型人工智能使个人能够将精力转移到更复杂的任务上,从而提高生产力。然而,在讨论部分还讨论了重要的潜在长期不利影响。
文章的其余部分将先介绍数据和方法,然后是结果,并以讨论作结。
数据
这些数据是通过对Stack Overflow数据探索器门户进行SQL查询提取的(许可证:CC BY-SA)。以下是使用的SQL命令:
SELECT Id, CreationDate, Score, ViewCount, AnswerCount
FROM Posts
WHERE Tags LIKE '%<python>%'
AND CreationDate BETWEEN '2022–10–01' AND '2023–04–30'
AND PostTypeId = 1;我然后按周聚合数据以减少噪音,因此获得了一个数据集,包含2022年10月17日至2023年3月19日的每周帖子数量、观看数量、每个问题的观看量、每个问题的平均得分和未回答问题的比例的信息。得分是由平台用户定义的,他们可以投票赞成或反对,表示该问题是否显示了“研究努力;它是有用且清晰的”或不是。
方法
为了测量因果效应,我使用了一种称为“差异-差异”模型的计量方法,该方法通常利用随时间变化的情况,并将一个或多个受试单元与未接受处理的群体进行比较。为了更了解该方法,我可以推荐您阅读两本免费电子书中关于该方法的章节:《Causal Inference for the Brave and True》和《Causal Inference: The Mixtape》。
简而言之,Diff-in-Diff模型通过计算双重差异来确定因果效应。以下是简化的解释。首先,我们的想法是计算两个简单差异:即经过处理和未经处理的两组(在这里分别是Python和R问题)的前期(ChatGPT发布前)和后期的‘平均’差异。我们关心的是处理对处理单元(即Python问题上ChatGPT发布的效应)的影响。然而,正如之前所说,可能会存在与处理(例如季节性)混淆的其他影响。为了解决这个问题,该模型的思路是计算双重差异,以检查处理组(Python)的第一差异与对照组(R)的第二差异之间的差别。由于我们预期在对照组上没有处理效应(或可以忽略不计),同时仍受到季节性等因素的影响,我们可以消除这个潜在的混淆因素,并最终测量因果效应。
这是一个稍微正式些的表示。
对于接受处理的组别来说,首要的区别是:
E[Yᵢₜ| Treatedᵢ, Postₜ]-E[Yᵢₜ| Treatedᵢ, Preₜ] = λₜ+β 在保持HTML结构的情况下,将下面的英文文本翻译为简体中文: E[Yᵢₜ| Treatedᵢ, Postₜ]-E[Yᵢₜ| Treatedᵢ, Preₜ] = λₜ+β
这里的 "i" 和 "t" 分别表示语言(R 或 Python)和周期。而 "treated" 指的是与 Python 相关的问题,"Post" 提示了 ChatGPT 可用的时间段。这个简单的差异可能代表了 ChatGPT 的因果效应(β)+ 一些时间效应 λₜ(例如季节性)。
对照组的第一个差异:
E[Yᵢₜ|控制ᵢ, 后ₜ] - E[Yᵢₜ|控制ᵢ, 前ₜ] = λₜ
The simple difference for the control group does not include the treatment effect (as it is untreated) but only the λₜ.
对照组的简单差异不包括治疗效应(因为它未接受治疗),仅包括 λₜ。
因此,双倍差异将会产生:
DiD = ( λₜ+β) — λₜ = β DiD = ( λₜ+β) — λₜ = β
在假设λₜ对于两组是相同的(平行趋势假设,在下面讨论),双重差异将使我们能够确定β,即因果效应。
这个模型的核心在于并行趋势假设。为了断言因果效应,我们应该确信在治疗期(2022年11月之后)中没有ChatGPT的情况下,Python(治疗组)和R(对照组)在Stack Overflow上的帖子演变是相同的。然而,显然无法观察到这一点,因此无法直接进行测试(参见因果推断的基本问题)。(如果你想了解更多关于这个概念和因果推断的内容,请查看我的视频和文章,可以在Towards Data Science: the Science and Art of Causality找到)。然而,在冲击之前,可以测试趋势是否是平行的,这表明对照组是一个潜在的良好“逆事实”。通过数据进行的两个不同的安慰剂测试显示,在ChatGPT之前的期间,我们无法拒绝并行趋势假设(测试的p值分别为0.722和0.397(详见在线附录B))。
正式定义:
Yᵢₜ = β₀ + β₁ Pythonᵢ + β₂ ChatGPTₜ + β₃ Pythonᵢ × ChatGPTₜ + uᵢₜ Yᵢₜ = β₀ + β₁ Pythonᵢ + β₂ ChatGPTₜ + β₃ Pythonᵢ × ChatGPTₜ + uᵢₜ
“i” 和 “t” 分别对应于 Stack Overflow 上问题的主题(i ∈ {R; Python})和周数。Yᵢₜ 表示结果变量:问题数量(H1),平均问题分数(H2)和未答问题的比例(H3)。Pythonᵢ 是一个二元变量,如果问题与 Python 相关,则取值为 1;否则为 0(与 R 相关)。ChatGPTₜ 是另一个二元变量,从 ChatGPT 发布之后取值为 1,否则为 0。uᵢₜ 是在编写语言级别(i)上聚集的误差项。
这个模型的本质在于并行趋势的假设。为了宣称一个因果效应,我们应该相信在处理期间(2022年11月之后),如果没有ChatGPT,Stack Overflow上Python(处理组)和R(对照组)的帖子发展将是相同的。然而,显然不可能观察到这一点,因此无法直接测试(参见因果推断的基本问题)。(如果你想了解更多关于这个概念和因果推断的内容,请参考我的视频和文章《因果性的科学与艺术》)。然而,在冲击之前,可以测试趋势是否平行,这表明对照组是一个好的“对照因素”。在这种情况下,两个不同的安慰剂测试表明我们不能否认平行趋势假设在ChatGPT出现之前的前期(测试的p值分别为0.722和0.397,请参见在线附录B)。
结果
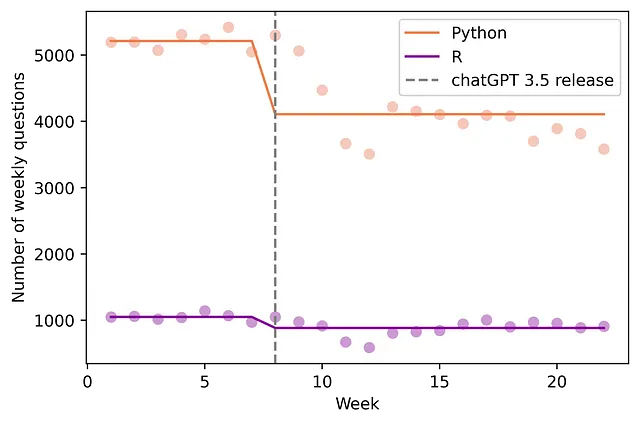
H1:ChatGPT 减少了 Stack Overflow 上提问的数量。
如介绍中所述,Diff-in-Diff模型估计出在Stack Overflow上,Python每周问题的平均数量显著下降了937.7个(95% CI:[-1232.8, -642.55];p值=0.000)。这表示每周问题数量下降了18%(见下方图2)。
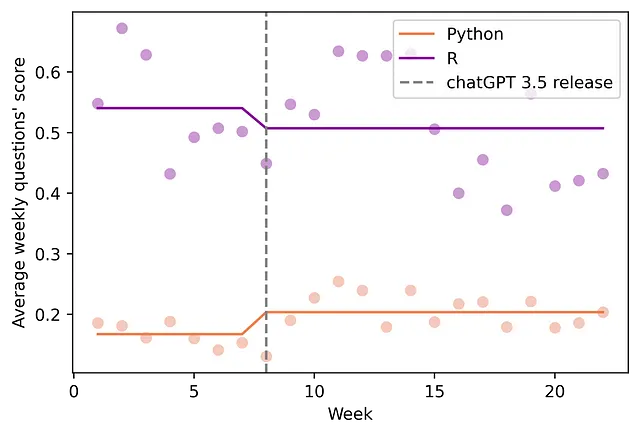
H2: ChatGPT提高了所提问题的质量。
ChatGPT可能有助于回答问题(参见H1)。然而,当聊天机器人无法解决问题时,它可以让用户进一步获取有关问题或解决方案的更多信息。该平台允许我们测试此假设,因为用户可以根据他们认为的“这个问题表现出研究努力,具有用途和清晰性”来投票(将得分增加1分),或者不投票(将得分减少1分)。这个第二个回归估计平均问题得分增加0.07分(95% CI:[-0.0127 , 0.1518];p值:0.095)(见图3),这表示增加了41.2%。
H3: 其余的问题更加复杂。
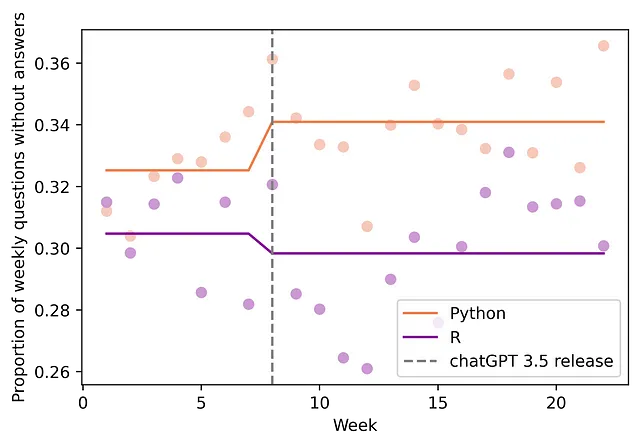
现在我们已经有一些证据表明ChatGPT能够提供重要的帮助(解答问题并帮助文档其他内容),我们想要确认剩下的问题更加复杂。为了做到这一点,我们要关注两个方面。首先,我发现未被回答的问题比例正在上升(没有答案可能意味着问题更加复杂)。更具体地说,我发现未被回答的问题比例增加了2.21个百分点(95%置信区间:[0.12, 0.30];p值:0.039),这代表了6.8%的增长(见图4)。其次,我们还发现每个问题的浏览次数没有改变(我们不能拒绝零假设,即浏览次数没有改变,p值为0.477)。这第二个测试允许我们部分排除另一个解释,即由于流量减少而导致更多未被回答的问题。
讨论
这些发现支持这样一种观点,即生成式人工智能可以通过处理例行问题而彻底改变我们的工作方式,使我们能够专注于更需要专业知识的复杂问题,同时提高我们的工作效率。
虽然这个承诺听起来令人兴奋,但背后也存在着一种反面情况。首先,低技能工作可能会被聊天机器人取代。其次,这种工具可能会对我们的学习方式产生负面影响。就个人而言,我认为编程就像骑自行车或游泳一样:光看视频或听课是不够的,你必须亲自尝试和失败。如果答案太完美,我们不迫使自己去学习,很多人可能会感到困扰。第三,如果Stack Overflow上的大量问题减少,可能会减少用于生成型人工智能模型的宝贵资源,从而影响它们的长期表现。
所有这些长期不良影响都尚不清楚,需要仔细分析。请在评论中告诉我你的想法。
[0] Gallea, Quentin. “从世俗到有意义:人工智能对工作动态的影响 - 基于 ChatGPT 和 Stack Overflow 的证据” arXiv econ.GN (2023)
[1] Hatzius,Jan。“人工智能对经济增长的潜在重大影响(布里格斯/科德纳尼)。”高盛公司(2023年)。
[2] https://cn.nytimes.com/technology/20230329/ai-artificial-intelligence-musk-risks/
[3] 巴特,瓦苏德夫等。“最小化你的标签:在stackoverflow中问题回复时间的分析。”2014年IEEE/ACM国际社交网络分析与挖掘会议(ASONAM 2014)。IEEE,(2014)