机器学习 - 向量数据库:比较和理解
介绍:智能AI互动之谜
在今天的数字时代,数据库几乎成为了每个应用程序的基石,从电子邮件客户端到复杂的企业资源规划(ERP)系统。传统的数据库架构,如SQL、NoSQL和图形数据库都有其优点,但对于那些需要模拟人类思维并实时响应的应用程序来说呢?这就是向量数据库的作用所在,它们复制了人类回答问题的速度和直觉。
人的感触:我们如何回答问题
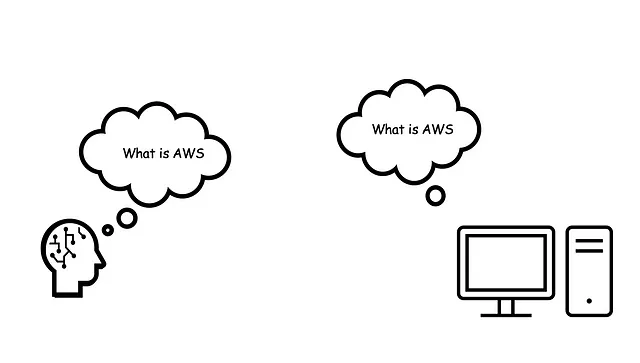
当有人向我们提问,比如“什么是AWS?”时,我们的大脑不会默认使用课本上的定义。相反,它会迅速扫描一遍脑海中的“数据库”,包括经验、记忆和掌握的知识。在这次扫描之后,我们会制定一个定制化答案,我们认为这是最相关的问题。简而言之,我们的大脑几乎瞬间进行“查询”、“检索”和“生成”一个个性化回应。
矢量数据库:模仿人类思维
向量数据库以类似的原理运作。它们将信息存储为数学向量,捕捉数据的本质。这些向量化的信息随后存储在持久层中。当系统接收到查询时,它也被转换为向量形式,然后与现有数据库进行匹配。通过余弦相似度等度量方法衡量,最接近的匹配结果将被检索出来作为最合适的答案。
在帷幕后:数据与速度的共生
1. 初始化阶段
最初,数据库将填充一组向量。这些向量是通过机器学习算法生成的,这些算法在大型数据集中筛查以发现模式和关系。
2. 适应和进化
随着收集到更多的数据,或者查询的重点变化,机器学习算法会不断优化自身。因此,数据库中的向量会被更新以反映这种新的学习进展。
实际实施:简化的JavaScript示例
为了提供一个具体的理解,让我们深入看一个简单的JavaScript示例。
数据库
在这里,MyKnowledgeBase类充当我们的数据库,存储向量供将来使用。
// Class for our "Knowledge Base"
class MyKnowledgeBase {
// ... (same as VectorDatabase)
}机器学习流程
我们使用MyLearningProcess类来对句子进行分词、将其转换为频率向量,然后保存到我们的知识库中。
// Class for ML Pipeline with method chaining
class MyLearningProcess {
constructor(vectorDB) {
this.vectorDB = vectorDB;
this.currentTokens = [];
this.currentVector = [];
this.currentSentence = '';
}
// Real-world equivalent: Tokenization
understandSentence(sentence) {
this.currentSentence = sentence;
this.currentTokens = sentence.toLowerCase().split(' ');
return this;
}
// Real-world equivalent: Vectorization
rememberImportantWords() {
// FrequencyVector
const frequencyMap = {};
for (let token of this.currentTokens) {
frequencyMap[token] = (frequencyMap[token] || 0) + 1;
}
this.currentVector = Object.values(frequencyMap);
return this;
}
// Real-world equivalent: Storing to database
saveToKnowledgeBase() {
this.vectorDB.addVector(this.currentSentence, this.currentVector);
return this;
}
}const myLearningProcess = new MyLearningProcess(vectorDB);
myLearningProcess.understandSentence("AWS is a cloud computing service.") //tokenize
.rememberImportantWords() //createVector
.saveToKnowledgeBase(); //addToVectorDatabse
myLearningProcess.understandSentence("Cloud computing is the delivery of services over the internet.")//tokenize
.rememberImportantWords()//createVector
.saveToKnowledgeBase(); //addToVectorDatabse语义搜索应用
MyAnswerFinder类负责接收查询,找到最佳匹配并检索它。
// Class for "Finding Answers"
class MyAnswerFinder {
// SemanticSearchApp
constructor(vectorDB) {
this.vectorDB = vectorDB;
this.currentQuery = '';
this.bestMatch = '';
}
// Real-world equivalent: Query Setting
askQuestion(query) {
this.currentQuery = query;
return this;
}
// Real-world equivalent: Similarity Search
lookForBestAnswer() {
const vectors = this.knowledgeBase.getVectors();
const sentences = this.knowledgeBase.getSentences();
let maxSimilarity = -1;
let bestMatchIndex = -1;
// Tokenizing the query
const queryTokens = this.currentQuestion.toLowerCase().split(' ');
// vectorizing the query
const queryVector = Object.values(queryTokens.reduce((acc, token) => {
acc[token] = (acc[token] || 0) + 1;
return acc;
}, {}));
// Under the hood: Starting the loop to find the best match
for (let i = 0; i < vectors.length; i++) {
// Calculating similarity for each sentence in the database
const similarity = this.calculateSimilarity(queryVector, vectors[i]);
// Under the hood: Checking if this is the best match so far
if (similarity > maxSimilarity) {
maxSimilarity = similarity;
bestMatchIndex = i;
}
}
this.bestAnswer = sentences[bestMatchIndex];
return this;
}
// Real-world equivalent: Cosine Similarity
calculateSimilarity(vecA, vecB) {
// ... (same as calculateCosineSimilarity)
let dotProduct = 0;
let magnitudeA = 0;
let magnitudeB = 0;
for (let i = 0; i < vecA.length; i++) {
dotProduct += (vecA[i] * vecB[i]);
magnitudeA += Math.pow(vecA[i], 2);
magnitudeB += Math.pow(vecB[i], 2);
}
magnitudeA = Math.sqrt(magnitudeA);
magnitudeB = Math.sqrt(magnitudeB);
return dotProduct / (magnitudeA * magnitudeB);
}
// Real-world equivalent: Retrieving Best Match
getBestAnswer() {
return this.bestAnswer;
}
}
一个指导示例:理解AWS
我们以一个示例来构建一个心智模型。在通过多个句子了解AWS后,我们将它们存储在我们的向量数据库中。
const myLearningProcess = new MyLearningProcess(vectorDB);
myLearningProcess.understandSentence("AWS provides cloud computing services.") //tokenize
.rememberImportantWords() //createVector
.saveToKnowledgeBase(); //addToVectorDatabse
myLearningProcess.understandSentence("Cloud computing is the core of AWS.")//tokenize
.rememberImportantWords()//createVector
.saveToKnowledgeBase(); //addToVectorDatabse
myLearningProcess.understandSentence("AWS has many services, including computing.")//tokenize
.rememberImportantWords()//createVector
.saveToKnowledgeBase(); //addToVectorDatabse为了充分了解我们的学习过程是如何内化信息的,让我们深入了解幕后所发生的细枝末节的细节。
"AWS provides cloud computing services."
Tokenized: ["AWS", "provides", "cloud", "computing", "services"]
Frequency Vector: { "AWS": 1, "provides": 1, "cloud": 1, "computing": 1, "services": 1 }
Numerical Vector: [1, 1, 1, 1, 1]
"Cloud computing is the core of AWS."
Tokenized: ["cloud", "computing", "is", "the", "core", "of", "AWS"]
Frequency Vector: { "cloud": 1, "computing": 1, "is": 1, "the": 1, "core": 1, "of": 1, "AWS": 1 }
Numerical Vector: [1, 1, 1, 1, 1, 1, 1]
"AWS has many services, including computing."
Tokenized: ["AWS", "has", "many", "services", "including", "computing"]
Frequency Vector: { "AWS": 1, "has": 1, "many": 1, "services": 1, "including": 1, "computing": 1 }
Numerical Vector: [1, 1, 1, 1, 1, 1]注意:这些是非常简化的,没有标准化的文本。通常我们会使用更复杂的算法来创建这些向量,比如TF-IDF、Word2Vec等。但这应该可以给你一个我们解释的基本概念。
然后我们模拟了一个朋友向我们提问的情境:“告诉我关于AWS云计算的信息。”
const myAnswerFinder = new MyAnswerFinder(kb)
myAnswerFinder.askQuestion("Tell me about AWS cloud computing")
.lookForBestAnswer()
.getBestAnswer()我的脑袋里:内部机制
当查询“告诉我关于AWS云计算”的时候,我的大脑首先经历以下阶段:
查询预处理
- 分词:将句子拆分为独立的单词:["告诉", "我", "关于", "AWS", "云计算"]
- 频率向量生成:对分词化查询中的每个术语进行频率统计:{"告诉": 1, "我": 1, "关于": 1, "AWS": 1, "云计算": 1}
- 数值向量的创建:基于频率向量[1, 1, 1, 1, 1, 1]创建数值表示。
搜索和评分
Query: "Tell me about AWS cloud computing"
Tokenized: ["Tell", "me", "about", "AWS", "cloud", "computing"]
Frequency Vector: { "Tell": 1, "me": 1, "about": 1, "AWS": 1, "cloud": 1, "computing": 1 }
Numerical Vector: [1, 1, 1, 1, 1, 1]
Step-by-step Calculation of Similarity:
Sentence 1: "AWS provides cloud computing services."
Cosine Similarity: (3 common words "AWS", "cloud", "computing") / sqrt(6 * 5) = 3 / sqrt(30) = 0.5477
Sentence 2: "Cloud computing is the core of AWS."
Cosine Similarity: (3 common words "AWS", "cloud", "computing") / sqrt(6 * 7) = 3 / sqrt(42) = 0.4629
Sentence 3: "AWS has many services, including computing."
Cosine Similarity: (3 common words "AWS", "computing") / sqrt(6 * 6) = 2 / sqrt(36) = 0.3333
决策
基于余弦相似度度量,我的大脑确定句子“AWS提供云计算服务”与查询“告诉我关于AWS云计算”的相似度得分最高。因此,它成为最适合的答案提供。
摘要:
向量数据库,正如我们 JavaScript 示例所展示的那样,不仅仅是一个理论概念;它们是生成式人工智能许多现实应用的引擎。就像我们的代码对句子进行分词和向量化以找到最相关的答案一样,生成式人工智能也使用类似的原理,但规模更加庞大。
以ChatGPT为例。它利用多维向量不仅能够匹配,还能够基于大型数据集生成人类化的文本。我们代码中的“查询设置”,“相似性搜索”和“最佳匹配检索”功能类似于ChatGPT中的底层算法,这些算法也经历了理解上下文,匹配相关性和生成回应的阶段。
最后的话:我作为前端开发者对人工智能的探索
我已经开始学习人工智能以及诸如向量数据库和ChatGPT之类的东西,这与我正常的前端工作有很大的不同。我将分享我所学到的内容,以帮助我自己和你理解这个令人兴奋的领域。请记住,我们都是一起学习的,而这个领域也在不断变化。
我的洞察仅是一个起点,离完整的画面还有很远的距离。因此,如果这激发了您的兴趣,我建议您也自行进行一些研究。我会在学到更多内容时继续分享,并希望您能与我一同加入这个旅程。