在GPT — I内部:理解文本生成
ChatGPT背后模型的简单解释

经常与不同领域的同事交流,我喜欢向没有数据科学背景的人传达机器学习概念的挑战。在这里,我尝试以简单的方式解释GPT的运作原理,只不过这次是以书面形式呈现。
在ChatGPT的受欢迎的魔力背后隐藏着一种不太受欢迎的逻辑。您写下一个提示给ChatGPT,它会生成文本,无论这些文本是否准确,它都类似于人类的回答。它如何能够理解您的提示并生成连贯和易理解的回答呢?
Transformer神经网络。这个架构被设计用来处理大量的非结构化数据,而我们的情况是文本。当我们说架构时,我们的意思是一系列在多个层次上并行进行的数学运算。通过这个方程系统,我们引入了几项创新,帮助我们克服了长期存在的文本生成难题。这些难题在5年前之前一直困扰着我们。
如果GPT已经存在了5年(实际上GPT的论文发表于2018年),那么它难道不是旧闻了吗?为什么它最近变得非常受欢迎?GPT 1、2、3、3.5(ChatGPT)和4之间有什么区别呢?
所有GPT版本都建立在相同的架构上。然而,每个后续模型都包含更多的参数,并使用更大的文本数据集进行训练。显然,后续的GPT版本引入了其他新颖性,尤其是在训练过程中通过人类反馈进行加强学习,我们将在博客系列的第三部分中进行解释。
向量、矩阵、张量。所有这些花哨的词语本质上都是包含一系列数字块的单元。这些数字通过一系列数学运算(主要是乘法和求和)进行处理,直到我们得到最佳的输出值,即可能结果的概率。
输出值?从这个意义上说,它是语言模型生成的文本,对吗?是的。那么,输入值是什么?是我的提示吗?是的,但不完全是。还有其他什么背后的东西呢?
在进入不同的文本解码策略之前,这将是下一篇博客文章的主题,先消除歧义是很有用的。让我们回到开始时提出的基本问题。它是如何理解人类语言的?
生成预训练变压器。GPT是该缩写词代表的三个词。我们在上面提到了Transformer部分,它代表了进行大量计算的架构。但是我们到底要计算什么?你从哪里得到这些数字?它是一种语言模型,你需要做的就是输入一些文本。你怎么计算文本呢?
数据是无神论的。无论是以文字、声音还是图像的形式,所有的数据都是相同的。
令牌。我们将文本分成小块(令牌)并为每个令牌分配一个唯一的编号(令牌ID)。模型不知道词语、图片或音频记录。它们学习将它们表示为一系列庞大的数字(参数),这些数字作为我们用来描绘事物特征的工具。令牌是传达意义的语言单位,令牌ID是编码令牌的唯一数字。
显然,我们如何进行语言标记化可以有所不同。标记化可以将文本分割成句子、单词、词的部分(子词)甚至是单个字符。
让我们考虑这样一种情况,我们的语言语料库中有50,000个标记(类似于GPT-2的50,257个)。在标记化后,我们如何表示这些单位呢?
Sentence: "students celebrate the graduation with a big party"
Token labels: ['[CLS]', 'students', 'celebrate', 'the', 'graduation', 'with', 'a', 'big', 'party', '[SEP]']
Token IDs: tensor([[ 101, 2493, 8439, 1996, 7665, 2007, 1037, 2502, 2283, 102]])
上面是一个例子句子被分解成单词。分词方法在实现上可以不同。对我们现在来说重要的是,我们通过相应的令牌ID获得语言单元(令牌)的数值表示。那么,现在我们有了这些令牌ID,我们可以直接将它们输入到进行计算的模型中吗?
基数在数学中很重要。对于模型来说,101和2493作为符号的代表是有意义的。因为记住,我们所做的一切主要是大量数字的乘法和求和。所以将一个数字乘以101或者2493都是有关紧要的。那么,我们如何确保以数字101表示的符号不会因为我们随意对其进行标记化而变得比2493不重要呢?我们如何编码这些词语而不引起虚构的排序?
一位热编码。稀疏映射的记号。一位热编码是一种将每个记号投射为二进制向量的技术。这意味着向量中只有一个单一元素为1(“热点”),其余元素为0(“冷点”)。
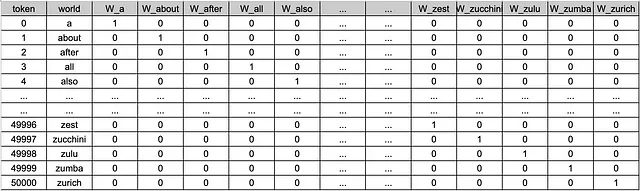
令牌用一个向量表示,其长度等于我们语料库中的总令牌数。换句话说,如果我们的语言中有50k个令牌,那么每个令牌都用一个长度为50k的向量表示,其中只有一个元素为1,其余元素为0。由于这个投影中的每个向量只包含一个非零元素,因此它被称为稀疏表示。然而,正如你所想,这种方法非常低效。是的,我们设法消除了令牌ID之间的人为基数,但我们无法从稀疏向量中推断出任何有关单词语义的信息。我们无法通过使用稀疏向量来理解“party”一词是指庆祝活动还是政治组织。此外,用大小为50k的向量表示每个令牌将意味着总共有50k个长度为50k的向量。从所需的内存和计算方面来看,这非常低效。幸运的是,我们有更好的解决方案。
嵌入。令牌的密集表示。通过嵌入层,令牌化单位被转换为固定大小的连续向量表示。例如,在GPT 3的情况下,每个令牌都由一个包含768个数字的向量表示。这些数字被随机分配,然后在模型看到大量数据(训练)后进行学习。
Token Label: “party”
Token : 2283
Embedding Vector Length: 768
Embedding Tensor Shape: ([1, 10, 768])
Embedding vector:
tensor([ 2.9950e-01, -2.3271e-01, 3.1800e-01, -1.2017e-01, -3.0701e-01,
-6.1967e-01, 2.7525e-01, 3.4051e-01, -8.3757e-01, -1.2975e-02,
-2.0752e-01, -2.5624e-01, 3.5545e-01, 2.1002e-01, 2.7588e-02,
-1.2303e-01, 5.9052e-01, -1.1794e-01, 4.2682e-02, 7.9062e-01,
2.2610e-01, 9.2405e-02, -3.2584e-01, 7.4268e-01, 4.1670e-01,
-7.9906e-02, 3.6215e-01, 4.6919e-01, 7.8014e-02, -6.4713e-01,
4.9873e-02, -8.9567e-02, -7.7649e-02, 3.1117e-01, -6.7861e-02,
-9.7275e-01, 9.4126e-02, 4.4848e-01, 1.5413e-01, 3.5430e-01,
3.6865e-02, -7.5635e-01, 5.5526e-01, 1.8341e-02, 1.3527e-01,
-6.6653e-01, 9.7280e-01, -6.6816e-02, 1.0383e-01, 3.9125e-02,
-2.2133e-01, 1.5785e-01, -1.8400e-01, 3.4476e-01, 1.6725e-01,
-2.6855e-01, -6.8380e-01, -1.8720e-01, -3.5997e-01, -1.5782e-01,
3.5001e-01, 2.4083e-01, -4.4515e-01, -7.2435e-01, -2.5413e-01,
2.3536e-01, 2.8430e-01, 5.7878e-01, -7.4840e-01, 1.5779e-01,
-1.7003e-01, 3.9774e-01, -1.5828e-01, -5.0969e-01, -4.7879e-01,
-1.6672e-01, 7.3282e-01, -1.2093e-01, 6.9689e-02, -3.1715e-01,
-7.4038e-02, 2.9851e-01, 5.7611e-01, 1.0658e+00, -1.9357e-01,
1.3133e-01, 1.0120e-01, -5.2478e-01, 1.5248e-01, 6.2976e-01,
-4.5310e-01, 2.9950e-01, -5.6907e-02, -2.2957e-01, -1.7587e-02,
-1.9266e-01, 2.8820e-02, 3.9966e-03, 2.0535e-01, 3.6137e-01,
1.7169e-01, 1.0535e-01, 1.4280e-01, 8.4879e-01, -9.0673e-01,
…
…
… ])
以下是单词“party”的嵌入向量示例。
现在我们有一个大小为50,000x786的向量,与50,000x50,000的独热编码相比,它更高效。
嵌入向量将成为模型的输入。由于稠密的数值表示,我们能够捕捉到单词的语义,相似的标记的嵌入向量将更接近彼此。
如何在上下文中衡量两个语言单元的相似度呢?有几个函数可以衡量两个大小相同的向量之间的相似度。我们可以通过一个例子来解释。
考虑一个简单的示例,我们有标记“猫”、“狗”、“汽车”和“香蕉”的嵌入向量。为简化起见,让我们使用嵌入大小为4。这意味着将有四个学习的数字来表示每个标记。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# Example word embeddings for "cat" , "dog", "car" and "banana"
embedding_cat = np.array([0.5, 0.3, -0.1, 0.9])
embedding_dog = np.array([0.6, 0.4, -0.2, 0.8])
embedding_car = np.array([0.5, 0.3, -0.1, 0.9])
embedding_banana = np.array([0.1, -0.8, 0.2, 0.4])
使用以上向量,让我们使用余弦相似度计算相似性得分。人类逻辑会发现单词“狗”和“猫”之间比单词“香蕉”和“汽车”更相关。我们能期望数学来模拟我们的逻辑吗?
# Calculate cosine similarity
similarity = cosine_similarity([embedding_cat], [embedding_dog])[0][0]
print(f"Cosine Similarity between 'cat' and 'dog': {similarity:.4f}")
# Calculate cosine similarity
similarity_2 = cosine_similarity([embedding_car], [embedding_banana])[0][0]
print(f"Cosine Similarity between 'car' and 'banana': {similarity:.4f}")
"Cosine Similarity between 'cat' and 'dog': 0.9832"
"Cosine Similarity between 'car' and 'banana': 0.1511"
我们可以看到,“猫”和“狗”的相似度非常高,而“车”和“香蕉”的相似度非常低。现在想象一下,我们语料库中的每个50000个标记的嵌入向量长度为768,这就是我们能够找到彼此相关的单词的方式。
现在,让我们来看一下下面这两个句子,它们具有更高的语义复杂性。
"students celebrate the graduation with a big party"
"deputy leader is highly respected in the party"
第一句和第二句中的“party”一词传达了不同的意思。大型语言模型如何能够区分“party”作为政治组织和作为庆祝社交活动的含义差异呢?
我们可以通过依赖于词嵌入来区分相同词语的不同含义吗?事实是,尽管嵌入提供了许多优势,但它们并不足以解开人类语言语义挑战的全部复杂性。
自注意力。解决方案再次由Transformer神经网络提供。我们生成一组新的权重(又称为参数),即查询(query)、键(key)和值(value)矩阵。这些权重学习以一组新的嵌入向量表示令牌。如何做到的?简单地通过对原始嵌入的加权平均值来实现。每个令牌在输入句子中“关注”每个其他令牌(包括自身),并计算一组注意权重,或者用其他词来说,所谓的“情境嵌入”。
它实际上所做的就是通过分配使用令牌嵌入计算出的一组新的数字(注意权重),来映射输入句子中单词的重要性。
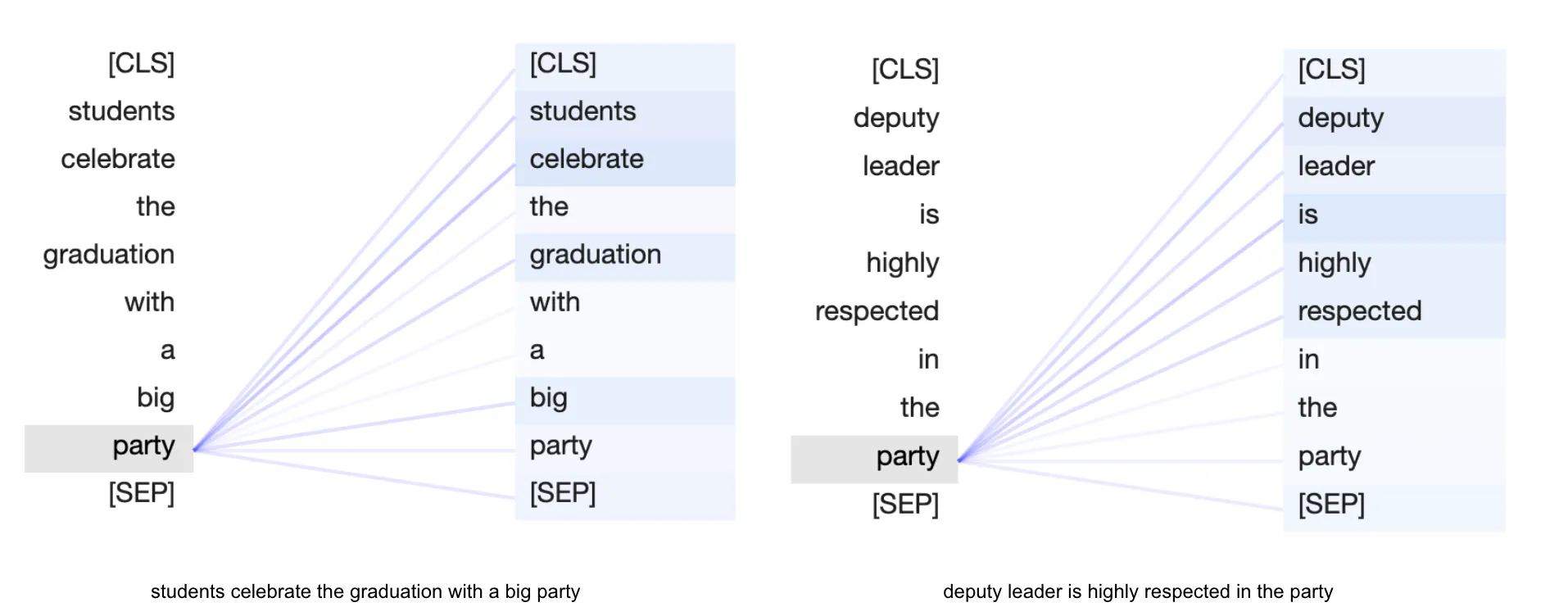
上面的可视化展示了“party”这个标记对两个句子中其他标记的“关注”。连接的粗细表示标记的重要性或相关性。关注和“关注”是指一系列新的数字(关注参数)及其大小,我们使用它们以数值形式表示单词的重要性。在第一个句子中,单词“party”对单词“celebrate”的关注最高,而在第二个句子中,“deputy”一词的关注最高。这就是模型通过检查周围单词来整合上下文的方式。
正如我们在注意力机制中提到的,我们会得出一组新的权重矩阵,即查询(Query)、键(Key)和值(Value)(简称q、k、v)。它们是相同大小的级联矩阵(通常比嵌入向量小),引入了体系结构以捕捉语言单元中的复杂性。为了揭示单词、单词对、单词对的对,以及单词对的对的对等之间的关系,我们会学习注意力参数。下面是可视化查询、键和值矩阵在查找最相关单词时的示意图。
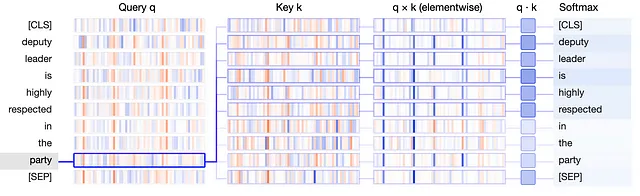
可视化将q和k向量表示为垂直带状物,每个带状物的粗细反映其大小。代表注意力确定的权重的标记之间的连接表明,“party”的q向量与“is”,“deputy”和“respected”的k向量最为显著地对齐。
为了使注意机制和q、k和v的概念不那么抽象,想象一下你去了一个派对,听到了一首让你爱上的惊艳的歌曲。派对结束后,你迫切想找到这首歌并再次听到,但你只记得歌词中的几个词和歌曲的一部分旋律(查询)。为了找到这首歌,你决定遍历派对播放列表(键)并听(相似性函数)播放列表中所有在派对上播放过的歌曲。当你最终辨认出这首歌时,你记录下了歌曲的名称(值)。
最后一个重要的技巧是在向量嵌入中添加位置编码,这是Transformer引入的。这是因为我们希望捕捉单词的位置信息。它增强了我们更准确地预测下一个标记的机会,使其更符合真实的句子语境。这是必要的信息,因为经常情况下,改变单词的顺序会完全改变语境。例如,“Tim chased clouds all his life”与“clouds chased Tim all his life”这两个句子在本质上是完全不同的。
到目前为止,我们所探索的所有数学技巧都是在基础水平上进行的,其目标是预测下一个标记,给定输入标记的序列。事实上,GPT 在文本生成方面进行训练,或者换句话说,进行下一个标记的预测。在其核心问题中,我们衡量一个标记在之前出现的标记序列中的概率。
您可能会想知道模型是如何从随机分配的数字中学习到最佳数字的。这可能是另一篇博客文章的主题,而了解这一点实际上是基础知识的重要部分。此外,您已开始对基本问题进行质疑,这是一个很好的迹象。为了消除不清楚之处,我们使用了一种优化算法,该算法根据一个称为损失函数的度量来调整参数。通过将预测值与实际值进行比较,可以计算出这个度量。模型跟踪度量的机会,并根据损失的大小来调整数字。此过程将一直进行,直到根据我们在称为超参数的算法中设置的规则,损失无法再减小为止。一个示例超参数可以是,我们希望多频繁地计算损失并调整权重。这是学习的基本思想。
我希望在这篇简短的帖子中,至少能够稍微澄清一些情况。本博客系列的第二部分将着重介绍解码策略,特别讲解为什么您的提示很重要。第三和最后一部分将专门讨论ChatGPT成功的关键因素,即通过人类反馈进行的强化学习。非常感谢阅读。下次见。
参考资料:
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “注意力就是你所需的一切”,于《神经信息处理系统进展》第30期(NIPS 2017),2017年。
J. Vig,“Transformer 模型中的多尺度关注可视化”,于《计算语言学年会第57届年会: 系统演示》论文集中,页码37-42,意大利佛罗伦萨,计算语言学协会,2019年。
L. Tunstall,L. von Werra和T. Wolf,《使用Transformer的自然语言处理,修订版》,O'Reilly Media,Inc.,于2022年5月发布,ISBN:9781098136796。
1 - 懒程序员博客