LangChain 图书馆全面支持 Neo4j 向量索引
简化在检索增强生成应用中的数据摄取和查询流程

如果你过去六个月一直在度假,首先恭喜你。其次,你应该知道,自从引入ChatGPT这类大型语言模型(LLM)以来,技术生态系统已经发生了巨大变化。现如今,一切都围绕着检索增强生成(RAG)应用程序展开。RAG应用程序的理念是在查询时提供额外的上下文信息,以使LLM生成准确和最新的答案。

Neo4j在RAG应用中存储和分析结构化信息方面一直表现出色。此外,Neo4j仅在几天前添加了向量索引搜索功能,使其更接近支持基于非结构化文本的RAG应用。
为了简化Neo4j的向量索引的使用,我已经将其正确地集成到LangChain库中。LangChain是构建LLM应用程序的主要框架,集成了大多数LLM提供商、数据库等等。它支持数据摄取以及读取工作流,并且在使用RAG架构开发问答聊天机器人方面特别有用。
在本博客文章中,我将通过一个端到端的示例引导您,演示如何利用LangChain将数据高效地导入到Neo4j向量索引中,然后构建一个简单但有效的RAG应用程序。
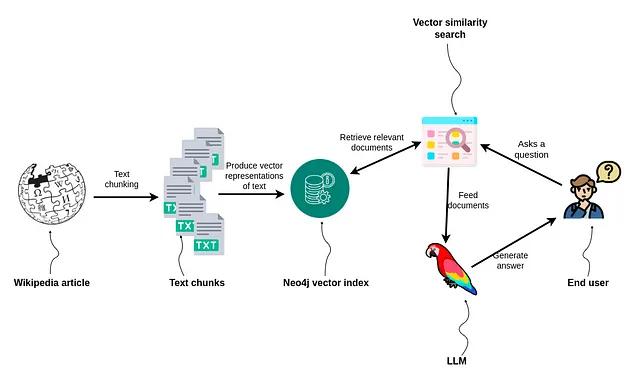
教程将包含以下步骤:
- 使用LangChain文档阅读器阅读维基百科文章
- 定义并分块文本
- 将以下英文文本存储在Neo4j中,并使用新增的向量索引进行索引。
- 实施一个支持RAG应用的问答工作流程。
一如既往,代码可在GitHub上找到。
Neo4j环境设置
您需要设置一个Neo4j 5.11或更高版本才能跟随本博客文章中的示例。最简单的方法是在Neo4j Aura上启动一个免费实例,它提供了Neo4j数据库的云实例。或者,您还可以通过下载Neo4j Desktop应用程序并创建本地数据库实例来设置Neo4j数据库的本地实例。
阅读和分块维基百科文章
我们将从阅读和分块化维基百科的文章开始。这个过程非常简单,因为LangChain已经集成了维基百科文档加载器以及文本分块模块。
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import CharacterTextSplitter
# Read the wikipedia article
raw_documents = WikipediaLoader(query="Leonhard Euler").load()
# Define chunking strategy
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=20
)
# Chunk the document
documents = text_splitter.split_documents(raw_documents)
# Remove summary from metadata
for d in documents:
del d.metadata['summary']
由于Neo4j是一个图数据库,我认为使用维基百科中关于莱昂哈德·欧拉的文章作为示例是合适的。接下来,我们使用tiktoken文本分块模块,该模块使用OpenAI制作的分词器将文章分成每个包含1000个词元的块。您可以在这篇文章中了解更多有关文本分块策略的内容。
LangChain的WikipediaLoader默认为每个块添加了摘要。我认为添加的摘要有些多余。例如,如果您使用向量相似度搜索来检索前三个结果,摘要将会重复三次。因此,我决定从数据集中删除它。
使用Neo4j存储和索引文本
LangChain 使得将文档导入 Neo4j 并使用新加入的向量索引进行索引变得简单。我们尽力使其非常易于使用,这意味着您不需要了解 Neo4j 或图形知识就可以使用它。与此同时,我们为有经验的用户提供了几个自定义选项,将在单独的博客文章中呈现。
Neo4j矢量索引被包装为LangChain矢量存储,因此遵循与其他矢量数据库进行交互所使用的语法。
from langchain.vectorstores import Neo4jVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Neo4j Aura credentials
url="neo4j+s://.databases.neo4j.io"
username="neo4j"
password="<insert password>"
# Instantiate Neo4j vector from documents
neo4j_vector = Neo4jVector.from_documents(
documents,
OpenAIEmbeddings(),
url=url,
username=username,
password=password
)
保持HTML结构,将以下英文文本翻译成简体中文: from_documents方法连接到Neo4j数据库,导入并嵌入文档,创建一个向量索引。 默认情况下,数据将以“Chunk”节点的形式表示。 如前所述,您可以自定义数据的存储方式以及要返回哪些数据。 但是,这将在接下来的博客文章中讨论。
如果您已经有一个已填充数据的现有矢量索引,您可以使用from_existing_index方法。
向量相似性搜索
我们将从一个简单的向量相似度搜索开始,以验证一切是否按照预期工作。
query = "Where did Euler grow up?"
results = neo4j_vector.similarity_search(query, k=1)
print(results[0].page_content)
结果

以指定的嵌入函数(以OpenAI为例)将问题嵌入到LangChain模块中,然后通过比较用户问题与索引文档之间的余弦相似度,找到最相似的文档。
Neo4j向量索引还支持欧几里得相似度度量以及余弦相似度。
问题-答案工作流程与LangChain
关于LangChain的好处是,它仅需一行或两行代码就可以支持问答工作流程。例如,如果我们想创建一个问答系统,根据提供的上下文生成答案,并提供所使用的文档作为上下文,我们可以使用以下代码。
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQAWithSourcesChain
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=neo4j_vector.as_retriever()
)
query = "What is Euler credited for popularizing?"
chain(
{"question": query},
return_only_outputs=True,
)
结果

正如您所看到的,LLM根据提供的维基百科文章构建了准确的答案,同时给出了使用的来源文件。而我们只需要一行代码就能实现这一点,如果您问我,这相当棒。
在测试代码时,我注意到有时源代码并没有返回。问题不在于Neo4j向量实现,而是在于GPT-3.5-turbo。有时候,它不会遵循返回源文件的指令。然而,如果你使用GPT-4,问题就会消失。
最后,为了复制ChatGPT界面,您可以添加一个内存模块,该模块额外提供对话历史给LLM,这样我们可以问后续问题。同样,我们只需要两行代码。
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
qa = ConversationalRetrievalChain.from_llm(
ChatOpenAI(temperature=0), neo4j_vector.as_retriever(), memory=memory)
现在让我们来测试一下吧。
print(qa({"question": "What is Euler credited for popularizing?"})["answer"])
结果

现在还有一个后续问题。
print(qa({"question": "Where did he grow up?"})["answer"])
结果

总结
向量索引是Neo4j的一个很好的附加功能,使其成为处理RAG应用的结构化和非结构化数据的出色解决方案。希望LangChain集成能够简化将向量索引集成到您现有或新的RAG应用程序的过程,这样您就不必担心细节。请记住,LangChain已经支持生成Cypher语句并使用它们来检索上下文,因此您今天就可以使用它来检索结构化和非结构化信息。我们对提升LangChain对Neo4j的支持有很多想法,敬请关注!
一如既往,代码可在GitHub上获得。
确保注册并参加 Nodes 2023,了解更多关于生成式人工智能和图技术的信息!