AI驱动的个人语音学习助手

保持HTML结构,将以下英文文本翻译为简体中文: 掌握一门新语言最有效的方法是什么?就是说它!但我们都知道,在他人面前尝试新的词汇和短语可能让人感到害怕。如果你有一个有耐心且理解的朋友来练习,不受评判,无羞耻之感,会怎么样呢?
你正在寻找那位有耐心、理解力强的朋友吗?也许你可以尝试使用由LLMs驱动的虚拟语言导师!这可能是一种改变游戏规则的方式来精通一门语言,在你自己的舒适空间里进行学习。
最近,大型语言模型出现在舞台上,它们正在改变我们的工作方式。这些强大的工具已经创建了能够像人类一样回应的聊天机器人,并且它们迅速地融入到我们生活的各个方面,在数百种不同的方式中得到应用。其中一个特别有趣的用法是在语言学习中,尤其是在口语练习方面。
当我一段时间前搬到德国时,我意识到学习一门新语言并找到练习口语的机会有多么具有挑战性。上课和参加语言组可能既昂贵又难以安排在繁忙的日程中。作为面临这些挑战的人,我有了一个想法:为什么不利用聊天机器人来练习口语?但仅仅通过发短信是不够的,因为语言学习涉及的不仅仅是写作。因此,通过结合人工智能聊天机器人、语音转文字和文字转语音技术,我成功地创造了一种学习体验,感觉就像在与真正的人交谈一样。
在本文中,我将分享我选择的工具,解释过程,并介绍通过声音指令和声音回应与AI聊天机器人进行口语练习的概念。该项目的流程包括三个主要部分:语音转文本转录、使用语言模型和文本转语音转换。下面将分别对这三个部分进行解释。
语音转文本转录
语音识别对我的语言导师来说是用户口语输入和AI基于文本的理解之间的桥梁,用于生成回应。它是实现基于语音的互动的关键组成部分,为更沉浸和有效的语言学习体验做出贡献。
准确的转录对于与聊天机器人的顺畅交互至关重要,尤其是在语言学习环境中,发音、口音和语法是关键因素。有各种语音识别工具可以用于在Python中转录口语输入,例如OpenAI的Whisper和Google Cloud的语音转文本。
在选择语言辅导项目的语音识别工具时,应考虑准确性、语言支持、成本以及是否需要离线解决方案等因素。
谷歌有一个需要互联网连接的Python API,每个月免费提供60分钟的转录服务。与谷歌不同,OpenAI发布了他们的Whisper模型,只要你拥有足够的计算能力,就可以在本地运行它,而不依赖于网络速度。这就是为什么我选择了Whisper,尽量减少转录的延迟。
2. 语言模型
语言模型是这个项目的骨干。因为我已经对ChatGPT和其API非常熟悉了,所以我决定在这个项目中继续使用它。然而,如果你有足够的计算能力,你也可以在本地部署Llama,这将是免费的。ChatGPT需要一些费用,但更加方便,因为你只需要几行代码就可以运行它。
为了增加响应的一致性并使其符合特定模板,您还可以微调语言模型(例如如何微调您的使用案例下的ChatGPT)。您需要生成示例句子和相应的最佳响应,并将它们输入到微调训练中。然而,我想要构建的基本教程不需要进行微调,我将在我的项目中使用通用的GPT3.5-turbo模型。
我将提供一个使用Python通过API来促进用户和ChatGPT之间对话的API调用示例,如下所示。首先,如果您还没有OpenAI帐户,您需要打开一个,并设置一个API密钥来与ChatGPT进行交互。这里提供了详细说明。
一旦你设置好了你的API密钥,你可以开始使用openai.ChatCompletion.create方法生成文本。这个方法需要两个参数:model参数,用于指定通过API访问的特定GPT模型,以及messages参数,它包含了与ChatGPT对话的结构。messages参数由两个关键部分组成:角色和内容。
以下是一个代码片段用来说明这个流程:
# Initialize the messages with setting behavior(s).
messages = [{"role": "system", "content": "Enter behaviour(s) here."}]
# Start an infinite loop to continue the conversation with the user.
while True:
content = input("User: ") # Get input from the user to respond.
messages.append({"role": "user", "content": content})# Append the user's input to the messages.
# Use the OpenAI GPT-3.5 model to generate a response to the user's input.
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
chat_response = completion.choices[0].message.content # Extract the chat response from the API response.
print(f'ChatGPT: {chat_response}') # Print the response.
# Append the response to the messages with the role "assistant" to store the chat history.
messages.append({"role": "assistant", "content": chat_response})
- 系统角色的定义是通过在消息列表的开头添加一条指令来确定ChatGPT的行为。
- 在聊天过程中,用户的消息通过提及的语音识别模型接收,以从ChatGPT获得回复。
- 最后,ChatGPT的回复将追加到助手角色的信息列表中,以记录对话历史记录。
3. 文字转语音转换
在语音转文字转录部分,我解释了用户如何利用语音命令模拟对话体验,就像与真实的人交谈一样。为了进一步增强这种感觉,并创造更具动感和互动性的学习体验,下一步是使用类似gTTS的文字转语音工具将GPT的文本输出转换为可听的语音。这不仅有助于创造更有吸引力和易于理解的体验,还解决了语言学习的一个关键方面:通过听而不是阅读的理解挑战。通过整合这一听觉组成部分,我们正在促进更全面的练习,更接近真实世界的语言使用。
有许多可用的TTS工具,例如Google的语音合成(gTTS)和IBM Watson的文本转语音。在这个项目中,我更喜欢gTTS,因为它非常容易使用,声音质量自然,而且完全免费。要使用gTTS库,您需要拥有互联网连接,因为该库需要访问Google的服务器将文本转换为语音。
流水线的详细解释
在我们深入研究流程之前,您可能希望查看我在Github页面上的整个代码,因为我将引用其中的某些部分。
下图解释了基于人工智能技术的虚拟语言助教的工作流程,旨在提供实时、基于语音的对话式学习体验。
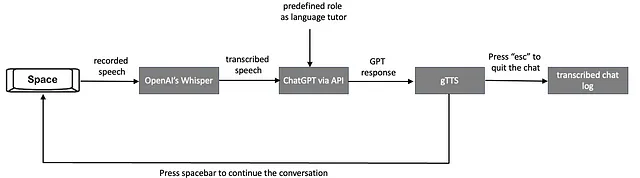
- 用户通过启动录音他们的语音来开始对话,将其暂时保存为.wav文件。按住空格键来完成这一操作,当松开空格键时,录音将停止。下面解释了实现这种按住键盘即可录音的Python代码部分。
以下全局变量用于管理录制过程的状态:
recording = False # Indicates whether the system is currently recording audio
done_recording = False # Indicates that the user has completed recording a voice command
stop_recording = False # Indicates that the user wants to exit the conversation
listen_for_keys函数用于检查按键的按下和释放。它根据空格键和esc键的状态设置全局变量。
def listen_for_keys():
# Function to listen for key presses to control recording
global recording, done_recording, stop_recording
while True:
if keyboard.is_pressed('space'): # Start recording on spacebar press
stop_recording = False
recording = True
done_recording = False
elif keyboard.is_pressed('esc'): # Stop recording on 'esc' press
stop_recording = True
break
elif recording: # Stop recording on spacebar release
recording = False
done_recording = True
break
time.sleep(0.01)
回调函数用于处理录音时的音频数据。它通过检查录音标志来确定是否录制传入的音频数据。
def callback(indata, frames, time, status):
# Function called for each audio block during recording.
if recording:
if status:
print(status, file=sys.stderr)
q.put(indata.copy())
press2record 函数是主要函数,负责处理用户按住空格键时进行语音录制的功能。
它初始化全局变量来管理录音状态,并确定采样率,同时创建一个临时文件来存储录制的音频。
该函数然后打开一个SoundFile对象来写入音频数据,并打开一个InputStream对象来捕捉来自麦克风的音频,使用先前提及的回调函数。启动一个线程来监听按键操作,特别是用于录制的空格键和用于停止的 'esc' 键。在一个循环内,函数检查录制标志,并在录制活动时将音频数据写入文件。如果录制停止,函数返回-1;否则,返回录制音频的文件名。
def press2record(filename, subtype, channels, samplerate):
# Function to handle recording when a key is pressed
global recording, done_recording, stop_recording
stop_recording = False
recording = False
done_recording = False
try:
# Determine the samplerate if not provided
if samplerate is None:
device_info = sd.query_devices(None, 'input')
samplerate = int(device_info['default_samplerate'])
print(int(device_info['default_samplerate']))
# Create a temporary filename if not provided
if filename is None:
filename = tempfile.mktemp(prefix='captured_audio',
suffix='.wav', dir='')
# Open the sound file for writing
with sf.SoundFile(filename, mode='x', samplerate=samplerate,
channels=channels, subtype=subtype) as file:
with sd.InputStream(samplerate=samplerate, device=None,
channels=channels, callback=callback, blocksize=4096) as stream:
print('press Spacebar to start recording, release to stop, or press Esc to exit')
listener_thread = threading.Thread(target=listen_for_keys) # Start the listener on a separate thread
listener_thread.start()
# Write the recorded audio to the file
while not done_recording and not stop_recording:
while recording and not q.empty():
file.write(q.get())
# Return -1 if recording is stopped
if stop_recording:
return -1
except KeyboardInterrupt:
print('Interrupted by user')
return filename
最后,get_voice_command函数调用press2record来记录用户的语音命令。
def get_voice_command():
# ...
saved_file = press2record(filename="input_to_gpt.wav", subtype = args.subtype, channels = args.channels, samplerate = args.samplerate)
# ...
- 将音频命令捕获并保存在临时.wav文件中后,我们现在开始转录阶段。在这个阶段,使用Whisper将录制的音频转换为文本。下面是仅用于运行.wav文件转录任务的相应脚本:
def get_voice_command():
# ...
result = audio_model.transcribe(saved_file, fp16=torch.cuda.is_available())
# ...
此方法接受两个参数:已录制音频文件的路径 saved_file 和一个可选标志,用于提升兼容硬件上的性能,如果 CUDA 可用则使用 FP16 精度。它仅返回转录的文本。
- 然后,将转录的文本发送到ChatGPT,以在interact_with_tutor()函数中生成一个合适的回应。相应的代码段如下所示:
def interact_with_tutor():
# Define the system role to set the behavior of the chat assistant
messages = [
{"role": "system", "content" : "Du bist Anna, meine deutsche Lernpartnerin.
Du wirst mit mir chatten. Ihre Antworten werden kurz sein.
Mein Niveau ist B1, stell deine Satzkomplexität auf mein Niveau ein.
Versuche immer, mich zum Reden zu bringen, indem du Fragen stellst, und vertiefe den Chat immer."}
]
while True:
# Get the user's voice command
command = get_voice_command()
if command == -1:
# Save the chat logs and exit if recording is stopped
save_response_to_pkl(messages)
return "Chat has been stopped."
# Add the user's command to the message history
messages.append({"role": "user", "content": command})
# Generate a response from the chat assistant
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
# Extract the response from the completion
chat_response = completion.choices[0].message.content # Extract the response from the completion
print(f'ChatGPT: {chat_response} \n') # Print the assistant's response
messages.append({"role": "assistant", "content": chat_response}) # Add the assistant's response to the message history
# ...
函数interact_with_tutor开始定义ChatGPT的系统角色,以使它在整个对话过程中塑造行为。由于我的目标是练习德语,因此我相应地设置了系统角色。我将我的虚拟导师称为"Anna",并设置了我的语言熟练程度以便让她调整回答。此外,我还指示她通过提问来保持对话的互动性。
接下来,用户转录的语音命令将以“用户”的身份添加到消息列表中。然后将该消息发送到ChatGPT。随着对话在while循环中继续,用户命令和GPT响应的完整历史记录都会记录在消息列表中。
- 在ChatGPT的每个响应之后,我们使用gTTS将文本消息转化为语音。
def interact_with_tutor():
# ...
# Convert the text response to speech
speech_object = gTTS(text=messages[-1]['content'],tld="de", lang=language, slow=False)
speech_object.save("GPT_response.wav")
current_dir = os.getcwd()
audio_file = "GPT_response.wav"
# Play the audio response
play_wav_once(audio_file, args.samplerate, 1.0)
os.remove(audio_file) # Remove the temporary audio file
gTTS()函数有4个参数:text、tld、lang和slow。text参数被赋予了messages列表中最后一条消息的内容(用[-1]表示),你想将其转化为语音。tld参数指定了Google翻译服务的顶级域名。将其设置为“de”表示使用德国域名,这对于确保德语的发音和语调是恰当的是很重要的。lang参数指定文本应该以哪种语言发音。在这段代码中,语言变量设为“de”,表示文本将以德语发音。slow=False:slow参数控制语音的速度。将其设置为False意味着语音将以正常速度播放。如果设置为True,语音将会慢一些。
- 将ChatGPT响应的转换语音保存为临时的.wav文件,播放给用户,并随后删除。
- Theinteract_with_tutor函数会在用户再次按下空格键以继续会话时持续运行。
- 如用户按下“esc”,会话结束并且整个对话将保存到一个pickle文件chat_log.pkl。可以之后用于分析。
命令行用法
在运行脚本之前,只需在终端中运行以下Python代码。
sudo python chat.py
sudo是必需的,因为该脚本需要访问麦克风并使用键盘库。如果您使用Anaconda,您可以通过“以管理员身份运行”启动Anaconda终端,以获得完全访问权限。
这里是一个演示视频,展示了代码在我的笔记本电脑上的运行情况。您可以感受到它的性能。
最后的话
我通过设置ChatGPT的系统角色和调整gTTs函数中的参数来将导师的语言设置为德语,同时保持了HTML结构。然而,你可以轻松地将其切换到其他语言。只需几秒钟即可配置为目标语言。
如果您想讨论特定的话题,您还可以在ChatGPT的系统角色中添加进去。例如,用它练习面试可能是一个不错的使用案例。您还可以指定您的语言水平以调整它的回答。
一个重要的备注是,聊天的整体速度取决于您的互联网连接(由于ChatGPT API和gTTS),以及您的硬件(由于Whisper的本地部署)。在我的情况下,输入后的整体响应时间在4至10秒之间。