ChatGPT揭示:它内部的ML模型是什么,从GPT-1到GPT-4。
在这个新的令人兴奋的人工智能进步时代,像OpenAI的ChatGPT这样的大型语言模型(LLM)已经引发了公众的广泛关注。无论是用于写电子邮件、调试代码还是回答复杂的问题,ChatGPT展现出了卓越的能力,能够提供准确且接近人类的回复。
但是哪些机器学习技术使ChatGPT具备这些功能?对于机器学习工程师和人工智能爱好者来说,理解这些模型的内部工作原理是发挥其全部潜力的关键!
在本文的第一部分中,我们将从GPT到GPT-4的演变过程进行探讨。在第二部分中,我们将深入探讨技术细节,以了解它们是如何生成如此准确的回复的。
GPT模型的演变
为了理解我们如何得到ChatGPT,我们将从GPT模型的演变开始。在本部分中,我们提到了许多技术术语,但不用担心:下一部分将详细解释它们!
从GPT-1到GPT-4
许多类似GPT的模型自第一个版本发布以来陆续问世,因此让我们试着关注那些引入了最重要创新的模型。
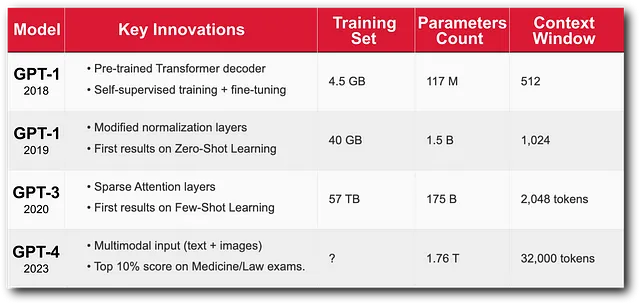
- GPT-1引入了以自我监督方式预训练Transformer解码器的想法,然后在特定的机器学习任务上进行微调。原始的Transformer在机器翻译方面已经有很高的准确率,但它需要大量有标签的数据。
- GPT-2通过增加参数超过10倍并轻微修改标准化层来提高准确性。GPT-2展现了零样本学习的能力,即在没有监督微调的情况下生成问答任务的预测。实际上,在自监督预训练期间接触到问答问题消除了对任务特定训练的需求。
- GPT-3 进一步扩大至 175B 参数,并且集成了稀疏注意机制来降低计算成本。GPT-3 取得了显著的少样本学习结果:与 GPT-2 不同,预训练数据与评估任务无关,而简单几个样本的提示就能帮助它理解任务并生成准确的预测结果。
- InstructGPT采用了人类反馈的强化学习(RLHF)进行微调,旨在实现更加符合人类的输出结果。与增加模型大小不同,这里的重点是优化模型的回答,以避免错误或有毒的答案。
- ChatGPT是InstructGPT的同类模型,但不同的是它不使用指令-回应对进行调整,而是使用人类对话进行RLHF微调,使其成为一个出色的对话代理。其发布引起了巨大关注,在不到一周内就吸引了超过100万用户。
- GPT-4作为ChatGPT的增强引擎发布。这是第一个支持文本和图像提示的多模态GPT。模型大小也有所增加,并且令人印象深刻的是,GPT-4在从高级摆放到医学执照考试中获得了前10%的成绩。
大型(语言)模型—大胆前进!
观察这些模型的发展,我们可以看到参数数量和训练数据集大小的不断增加在像ChatGPT这样的LLM取得戏剧性成功中起到了关键作用。确实,新的人工智能加速器的可用性和从互联网上获取的海量文本数据催生了模型和数据集规模的指数增长。
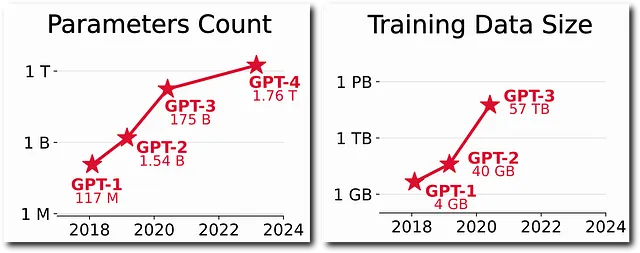
但是这些模型之所以取得如此令人印象深刻的成果,不仅仅是因为它们的巨大规模。实际上,还有许多创新和技术特点使得这些模型能够取得如此出色的成就。让我们详细看一下它们!
变压器架构
Transformer是自然语言处理(NLP)领域中所有最先进模型的基本架构,包括GPT模型等LLM模型。
- 输入的句子已被分词,即分成单词或单词片段。
- 每个标记都使用学习到的词向量转换为向量。
- 在每个层中,为每个标记计算软注意力权重。
- 这些权重通过与嵌入进行点乘,为每个标记生成一个新的向量,然后传递给后续的层。
- 多个注意力头可以计算这些权重,因此它们的输出在移动到下一层之前进行合并。
自注意机制使得模型能够学习句子中标记之间的关系,这是其成功的关键特征。此外,与RNN等之前的顺序模型相比,Transformer只使用易于并行计算的点积操作,从而实现更快的训练和评估速度。

不幸的是,自我注意力层需要计算每对令牌之间的注意力得分,因此总共需要 O(N²) 次操作(其中 N 是输入序列的长度)。对于长输入序列来说,这可能非常昂贵!
稀疏注意力
为了降低自注意力层的二次成本,GPT-3采用了稀疏注意力层。不是关注所有先前的标记,而是每个标记只关注前一个√N个标记。显著地,这样可以将计算成本减少到O(N√N)。
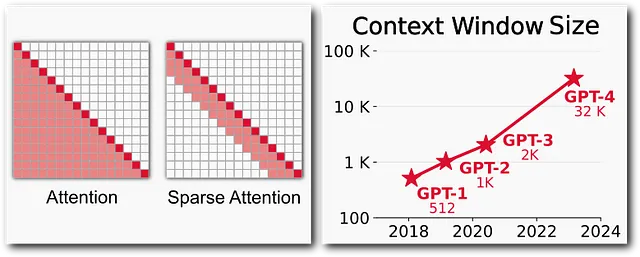
如图所示,疏密注意力使得GPT模型能够呈指数增加上下文窗口大小,也就是可以处理更长的提示长度。虽然这似乎会降低表达能力,但带状注意力图形设计得使得每个标记能够关注附近的标记和较远距离的标记,从而保持了模型的准确性。
跟着因果语言建模的自我监督预训练
GPT的训练策略利用大量未标记的原始互联网文本以自我监督的方式对模型进行预训练。但是我们如何在没有标签的情况下训练模型呢?思路是通过处理原始文本获得“人为任务”来训练模型。有两种方法可行。
- 遮罩语言建模(MLM)-在句子中随机屏蔽一个标记,并训练模型预测该标记。这种方法用于具有编码器结构的鉴别性双向模型,如BERT。
- 原因语言建模(CLM)-随机截断一个句子,并训练模型预测下一个标记。这种方法适用于具有解码器架构的生成自回归模型,例如GPT。
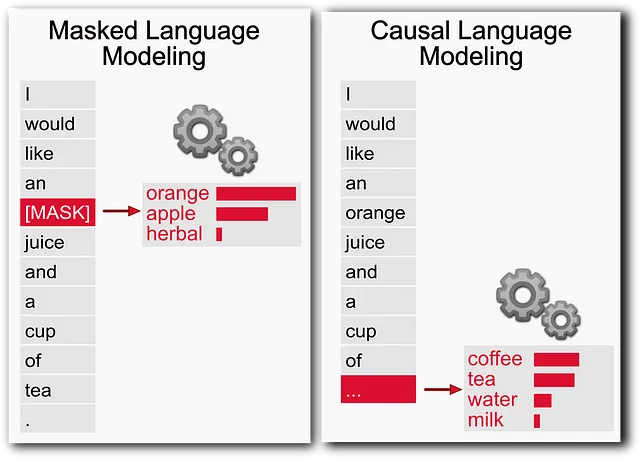
因此,CLM预训练跳过了手动标记的麻烦,让GPT模型可以利用各种在线数据,这是它们成功的一个重要原因。
零射击和少射击VS. 微调
经过预训练后,大多数机器学习模型需要进行额外的微调步骤,以生成特定下游机器学习任务(如情感分析)的预测结果。然而,微调需要数千个标记示例,并且每个新任务都需要一个不同的数据集。
相比之下,GPT模型可以生成下游任务的预测,而无需进行进一步的微调。由于GPT模型在如此广阔的数据集上进行了预训练,它们已经学会了理解和逻辑推理各种任务。因此,重点转移到了提示工程,即如何为模型提供定义要执行任务的提示。
- 零样本学习-模型仅给出包含要执行的任务描述和输入的提示。
- Few-Shot Learning — 任务描述和输入之外,模型还会提供一些执行该任务的输入-输出示例。
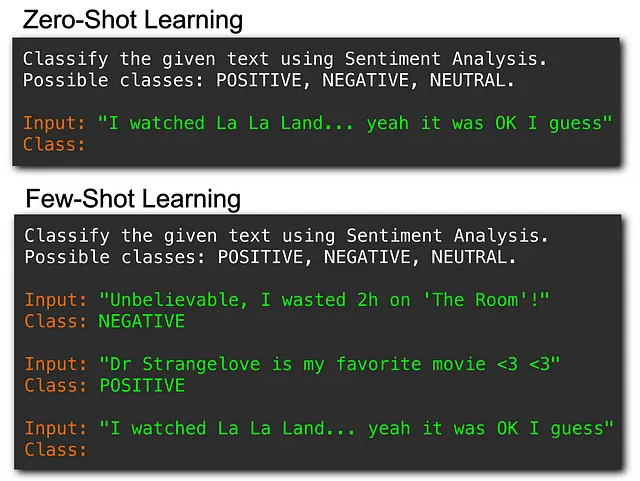
Few-Shot Learning通常比Zero-Shot Learning取得更好的结果,但它需要一些有标签的示例。尽管如此,这仍然是对传统的Fine-Tuning的巨大进步,因为它只需要最少数量的示例,并消除了耗时的权重调整的需求!
来自人类反馈的强化学习
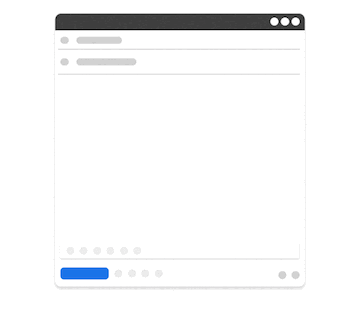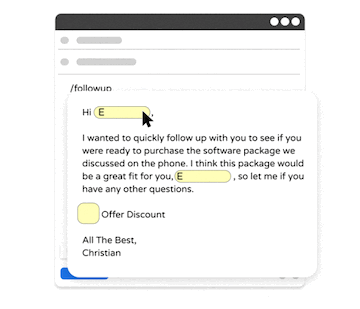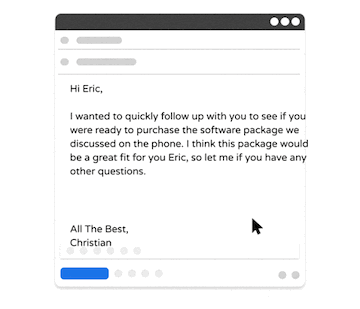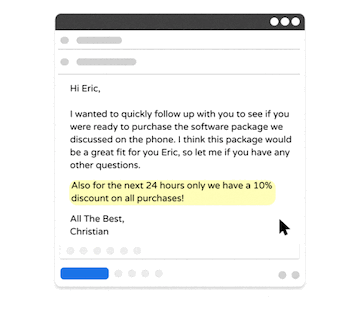
GPT的自动生成结果在评估得分方面表现出色,但有时与提示中人类意图不一致。为了解决这个问题,InstructGPT和ChatGPT采用了强化学习与人类反馈(RLHF)的方法,通过三个步骤来对模型进行微调。
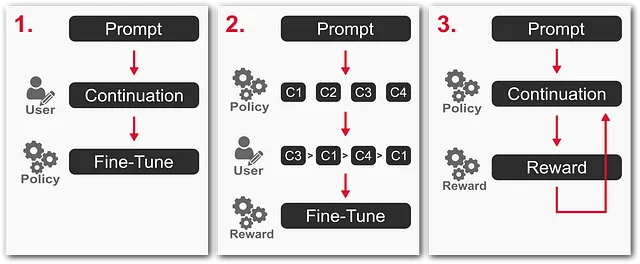
- 策略模型 - 在一个提示下,GPT模型通过一个人类专家撰写的延续来进行CLM任务的微调。
- 奖励模型 - 在给定一个提示的情况下,策略模型生成约5个完成。人类专家将它们从最好到最差进行评级,然后用这些评级训练另一个GPT模型,以预测每个完成的偏好分数。
- 增强学习 - 在给定一个提示的情况下,策略模型预测一个完成或"动作"。奖励模型计算一个奖励用于优化和微调策略模型。

如我们在上面的示例图中所看到的,使用RLHF进行微调后的提示补充显著提高了答案的质量。
结论 — 简述
- GPT模型在文本生成方面取得了令人瞩目的成果。
- 随着时间的推移,我们可以看到准确性和能力的提高。
- LLM(如ChatGPT)的成功部分原因在于模型和数据集的庞大规模。
- 但是也有技术创新促成了这一成功,例如稀疏注意力、CLM训练和RLHF。
参考资料
- (A. Vaswani 2017)注意力是你需要的一切
- (A. Radford 2018)通过生成型预训练提高语言理解
- (J. Delvin 2018)BERT:深度双向转换器的预训练用于语言理解
- (R. Child 2019)使用稀疏变压器生成长序列
- (A. Radford 2019)语言模型是无监督多任务学习器
- (T. Brown 2020)语言模型是少样本学习者。
- (L. Ouyang 2022年)使用人类反馈训练语言模型遵循指令。
- (OpenAI 2022)介绍ChatGPT
- (OpenAI 2023)GPT-4 技术报告