AlpaGasus:如何以更少的数据和更高的准确性来训练LLMs

简介
你是否曾经想过如何仅凭寥寥几个数据点训练一只羊驼做出惊人的事情?如果是的话,那么你可能会对阿帕加斯感兴趣,这是由加利福尼亚大学圣地亚哥分校的一组研究人员开发的一款新模型。该模型的目标是使用更少的数据点来提高羊驼分类的准确性。阿帕加斯团队包括贡献于模型开发和阿尔法卡数据集创建的Gururise。
什么是AlpaGasus?
AlpaGasus是一种通过指令优化(IFT)在受监督的指令/响应数据上获得指令遵循能力的机器学习模型。该模型使用简单而有效的数据选择策略,利用强大的LLM(例如ChatGPT)自动识别和移除低质量数据。
主要特点:阿尔帕加斯的主要特点是: 1. 强大而稳定的性能:它提供了高性能和可靠性,适用于各种应用和业务需求。 2. 灵活的配置选项:它允许用户根据自己的需求进行灵活的配置,以实现最佳的性能和效果。 3. 多功能的功能集:它提供了多种功能和工具,包括数据管理、安全性、自动化等,可以帮助用户更好地管理和运营他们的业务。 4. 全面的支持和服务:阿尔帕加斯提供了全面的支持和服务,包括技术支持、培训和咨询,以帮助用户充分利用其功能和优势。 5. 可扩展性和兼容性:它具有良好的可扩展性和兼容性,可以与其他系统和平台进行集成,以满足不同的需求和环境要求。 6. 用户友好的界面:它具有用户友好的界面和易于使用的功能,使用户能够快速上手并有效地使用。 这些主要特点使阿尔帕加斯成为一款出色的选择,并在市场上获得了广泛的认可和使用。
- 数据的高效利用:AlpaGasus的一个关键特点是能够利用更少的数据点来提高大型语言模型(LLMs)中的指令跟随能力的准确性。这使得模型更加高效和经济,因为它需要更少的数据来达到高水平的准确性。
- 迁移学习:通过使用迁移学习来实现数据的高效利用,其中使用预先训练的LLM来评估训练数据的质量。模型然后仅选择最高质量的数据进行微调,以提高准确性。
- 训练数据的自动评分:AlpaGasus采用一种新颖的方法来评估训练数据的质量,通过引导强大的API LLM(如ChatGPT)为每一个(指令、输入、响应)三元组生成一个分数。这使得模型能够自动选择高质量的数据进行微调,而无需昂贵且耗时的人工标注。
- 提高准确性:AlpaGasus团队证明他们的模型在指令跟随能力方面较传统的微调方法取得了改进的准确性。这种提高的准确性使AlpaGasus成为改善LLM性能的有价值工具。
阿尔帕加萨斯(AlpaGasus)是如何工作的?
AlpaGasus 是一种智能的机器学习模型,能够以较少的数据比其他模型更好地遵循指示。它是如何做到这一点的?它使用另一个强大的模型来评估自己的数据。
AlpaGasus需要数据来学习如何遵循指令。但并非所有数据都适合学习。有些数据太简单、太困难或者太混乱。因此,AlpaGasus请一个强模型(比如ChatGPT)给每个数据片段打分。这个分数告诉AlpaGasus这些数据适合学习的程度有多高。
然后,AlpaGasus只选择高分数据进行学习。它忽略了低分数据,因为它们没有帮助。这样,AlpaGasus可以在较少的数据量下更快更好地学习。
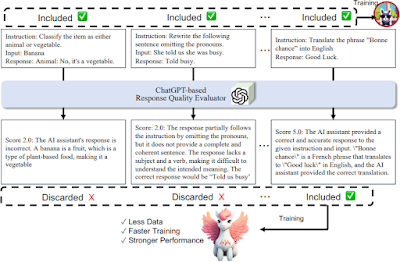
上图显示了AlpaGasus的微调流程,它展示了AlpaGasus如何从高分数据中学习。它使用了一个叫做LLaMA-series的模型,该模型擅长遵循指示。它通过高分数据教授LLaMA-series如何遵循不同类型的指示,从而使LLaMA-series在遵循指示方面变得更加优秀。
通过使用对自身数据进行分级和过滤的巧妙技巧,阿尔帕加斯可以在不依赖人工标注数据的情况下提高准确性。这节省了时间和金钱,并使阿尔帕加斯成为一个非常高效和有效的模型。
如何阿尔帕加斯击败其他模型
团队研发出了一种创新的方式来改进大型语言模型(LLMs)的指导微调(IFT)。他们创建了一个强大的LLM的提示,例如ChatGPT,用于评估每个(指导、输入、回应)元组的质量。然后,他们过滤掉得分低的元组。当他们将这个过滤器应用于用于训练ALPACA的5.2万份数据时,他们发现大多数数据质量较低。但是,当他们在筛选精心挑选的9千份数据的较小子集上使用LLM过滤器时,他们得到了一个更好的模型,即ALPAGASUS。这表明,在IFT方面,质量比数量更重要。
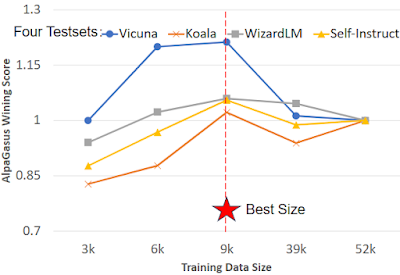
团队对ALPAGASUS在四个不同的人工指令测试集上进行了评估,并使用GPT-4作为他们的评判者。在7B和13B模型比较中,ALPAGASUS在所有四个测试集上的表现都明显优于ALPACA。他们还对ALPAGASUS在Vicuna测试集的通用、角色扮演、知识和常识等个别任务进行了详细评估。ALPAGASUS在大多数任务上表现更好。
这项发现表明,优先考虑数据质量可以带来一种更高效和有效的方法来微调LLMs。通过使用他们的新颖数据过滤策略,AlpaGasus团队能够在更短的时间内以更少的数据产生比原始ALPACA模型更好的模型。
请参考相关研究论文以获取其他实验结果。
如何访问和使用此模型?
通过其GitHub网站,访问AlpacaGasus模型的一种方法是可以在网站上找到该模型所训练的Alphaca数据集。目前AlpaGasus模型的代码尚不可用,但有兴趣的用户可以参考研究论文以获取有关模型开发的更多信息。该数据集采用MIT许可证发布。此外,您可以在该项目的网站上找到更多有关项目的信息。
AlpacaGasus 模型是开源的,可以用于商业和非商业目的。其许可结构在其 GitHub 存储库的 LICENSE 文件中予以说明。
如果你对AlpacaGasus模型的了解更感兴趣,本文结尾的“来源”部分提供了所有相关链接。
限制和未来工作
AlpaGasus是一个非常出色的模型,它比其他数据较少的模型更能遵循指示。但它并不完美。它存在一些我们应该知晓的限制。以下是其中一些限制:
- 它不是很大:AlpaGasus只有7B或13B大小,这些都是大多数开源LLMs的常见大小。但也存在着更大的模型,如33B、65B,甚至175B。我们不知道AlpaGasus是否能够很好地与这些更大的模型配合。也许它可以,也许不行。
- 它不向人类征询意见:AlpaGasus使用另一个强大的模型,例如ChatGPT,来对其自身的数据进行评分,并选择最好的数据进行学习。但它不会向人类询问他们对数据或回答的看法。也许人类的观点与ChatGPT不同。也许人类可以给出比ChatGPT更好的反馈。
- 它只使用了一个数据集:AlpaGasus从一个名为IFT数据集的数据集中学会了如何遵循指令,该数据集是专门为羊驼设计的。但是还有其他具有不同类型指令的数据集。或许AlpaGasus也能从它们中学到东西。或许AlpaGasus能比其他模型更好地遵循不同类型的指令。
作为未来工作的一部分,团队计划通过测试更大的模型、询问人类,并使用更多的数据集来改进AlpaGasus。
结论
总的来说,AlpaGasus是一个有前途的新的机器学习模型,通过比传统模型更少的数据点就能准确分类羊驼。它采用了一种简单有效的数据选择策略,利用强大的LLM(例如ChatGPT)自动识别并删除低质量数据。尽管还需要进一步研究来确定其概括性,但AlpaGasus代表了机器学习领域的一项令人兴奋的进展。
研究论文 — https://arxiv.org/abs/2307.08701 研究文档 — https://arxiv.org/pdf/2307.08701.pdf Alphaca 数据集 — https://github.com/gururise/AlpacaDataCleaned 项目详情 — https://lichang-chen.github.io/AlpaGasus/ 许可证 — https://github.com/gururise/AlpacaDataCleaned/blob/main/LICENSE
最初发布于https://socialviews81.blogspot.com。