释放聊天机器人的潜力:用LLMs重新考虑策略

企业软件的领域之一是聊天机器人开发,这是LLM能够产生可衡量影响的最大领域之一。我们都使用过聊天机器人,并看到大多数聊天机器人在解决用户的问题和提供出色体验方面不尽人意。
语言模型模型(LLMs)的出现,例如ChatGPT,提供了一种有前途的解决方案,可以实现更加人性化的对话。这让我们思考:
LLM是否将成为用于创建聊天机器人的事实技术?
为了探索这个问题,我决定只使用ChatGPT来创建一个订购披萨的聊天机器人。通过将ChatGPT作为聊天机器人的唯一基础,我开始了一段探索LLM在聊天机器人开发中能力和限制的旅程。
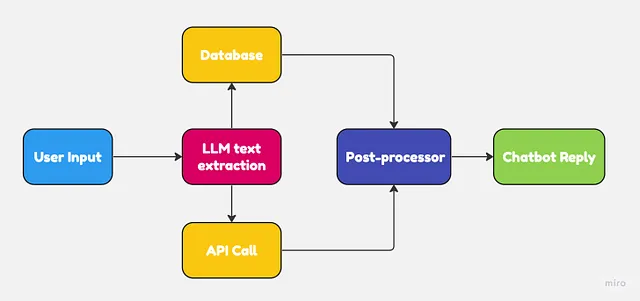
为了让聊天机器人有效地工作,它们需要能够做几件事情:
- 从用户输入中提取信息片段
- 根据提取的信息,在数据库或调用 API 端点中进行搜索。
- 清洗检索到的数据并将其发送回用户
- 循环进行步骤1至3,直到用户满意为止。
在这种特殊情况下,我完全依赖ChatGPT来完成所有这些任务。以下是ChatGPT的每个步骤:
- 解析OpenAPI yaml文件以理解定制披萨订购API。
- 将用户输入转换为类似于API调用的JSON对象
- 将从API获得的信息转化为类似于人的反应,以回应用户。
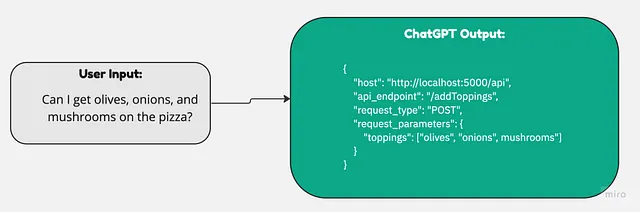
结果
我所发现的是,虽然聊天机器人在技术上能够工作,但其结果并不一致。例如,ChatGPT 有时会调用错误的 API 端点或发送错误的请求参数。
即使聊天机器人运作正常,整个过程也感觉有些缓慢和不可预测。
由于LLMs是生成模型,它们的输出本质上是随机的。为了使聊天机器人应用程序能够有效地工作,我们需要一定程度的可预测性,而仅仅使用LLMs无法提供。
将LLMs整合进传统的NLU流程中。
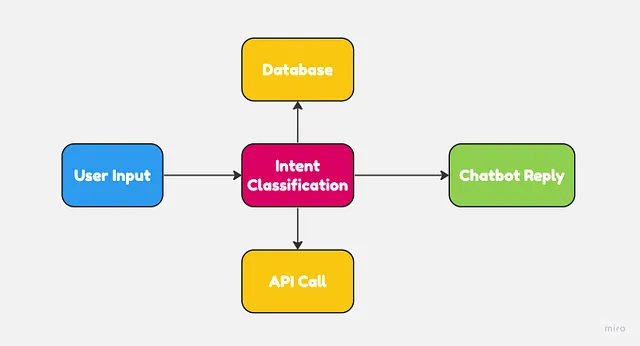
传统自然语言理解技术在开发聊天机器人方面提供了许多优势:
- 模型输入和输出的精细控制
- 速度和效率,如意图识别、实体提取等文本处理。
- 高可预测性,因为模型已经经过特定任务的训练,例如分类。
- 可解释性和可解释性,让解释系统如何得出特定结果更容易。
然而,传统的NLU模型也有自己的权衡之处,比如无法很好地泛化。许多这些聊天机器人都有手工制作的规则,往往聊天机器人的回应很少或没有变化。
这是人们不喜欢使用聊天机器人的主要原因之一。对话往往遵循非常严格的格式,聊天机器人的回答缺乏人类个性。
最好的两个世界
LLMs和NLU应用程序本身都不完美,用于聊天机器人的情况下。而不是用LLMs替换传统的NLU技术,通过将两个系统集成起来,可以获得更好的结果。
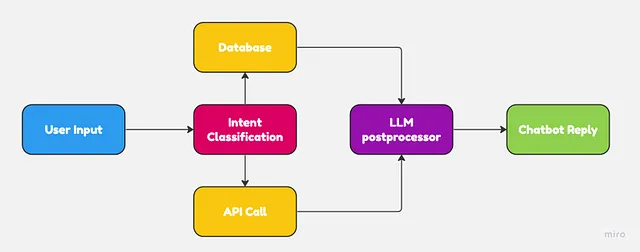
传统系统在文本提取和意图分类方面通常表现更好。另一方面,语言模型则非常适合根据某些上下文生成类人回复。
通过将LLMs嵌入NLU工作流程中,企业可以在最小程度上更改软件架构,从而获得显著更好的聊天机器人。
因此,为了回答此帖子开头的初始问题:
LLM是否会成为创建聊天机器人所使用的事实技术?
LLM技术在取代传统的NLU技术方面仍有很长的路要走。目前最好的结果是将两者组合起来使用。