ChatGPT-4在诊断复杂医学状况方面的成功被展示在新的研究中。
它的平均诊断分数是惊人的5分之4.2。

在最近发表于《JAMA》杂志上的开创性研究中,题为“一种生成人工智能模型在复杂诊断挑战中的准确性”的医学专家团队在美国哈佛医学院的贝斯以色列-德肯斯医疗中心(BIDMC)深入探讨了一种流行的对话人工智能ChatGPT-4的诊断能力。
结果确实令人印象深刻。ChatGPT-4在近40%的复杂医疗案例中第一时间确定了正确的诊断。更令人惊讶的是,在三个具有挑战性的案例中,它在考虑的可能性范围内包括了正确的诊断结果。
生成式人工智能(例如ChatGPT)是人工智能的一种变体,它利用其训练数据中的模式和洞见来生成新鲜的内容,而不仅仅是处理和分析现有数据。你可能已经通过聊天机器人与这种技术进行了交互,这些机器人是日益复杂的数字助手,它们使用自然语言处理(NLP)——一种使计算机能够理解和产生类似人类语言的人工智能形式。
虽然聊天机器人已经在客户服务和教育等领域开始改变着我们的生活,但是在临床场景, 特别是复杂的诊断上,他们的潜力才刚刚开始被发掘。
“最近AI的进步导致了生成AI模型的出现,它们能够提供详细的基于文本的响应,并在标准化医学考试中得到高分,”领导这项研究的Adam Rodman医学博士兴奋地说道,“我们想知道这样的生成模型是否能够像医生一样‘思考’,于是我们让它解决了用于教育目的的标准化复杂诊断案例。 它表现得非常出色。”
罗德曼和他的研究团队使用一系列临床病理病例会议(CPCs)评估聊天机器人的诊断能力。这些病例涵盖复杂的临床数据、实验室发现、影像研究和组织病理学结果,通常在《新英格兰医学杂志》上发表,以进行教育性洞察。
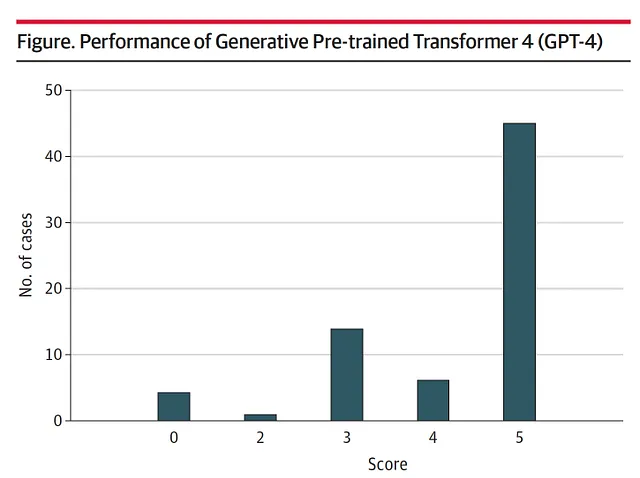
团队使用ChatGPT-4人工智能检查了70个CPC病例。根据五个层次的分级标准,得分为5表示真实诊断已被包含在鉴别诊断中,得分为0表示完全未诊断。鉴别诊断是一个可能病情列表,可以从患者的症状、病史和临床表现中获得。
值得注意的是,平均得分为4.2分,大多数病例得分为5分(图1)。在64%的病例中,正确的诊断被列入鉴别诊断,并在39%的病例中成为主要诊断。
“尽管聊天机器人不能代替经过训练的医疗专业人员的专业知识和技能,但生成式人工智能在诊断中是一种有前途的潜在辅助手段,”该研究的主要作者查希尔·坎吉(Zahir Kanjee), MD,MPH表示。“它有潜力帮助医生理解复杂的医学数据,并扩大或完善我们的诊断思维。”