顶点 AI 小贴士和技巧:使用退出处理器在生产中创建强大的 ML 管道
Vertex AI管道提供了一种可扩展的方式来以无服务器方式自动化和编排您的ML工作流程。Vertex AI支持Kubeflow Pipelines SDK v1.8.9或更高版本,因此,您也可以在Vertex AI管道中使用Kubeflow中可用的各种开源功能。
虽然一些Kubeflow功能通常在Vertex AI Pipelines中使用,例如将管道分解为单独的任务或使用条件控制工作流程,但一些经常被忽视的Kubeflow概念对于创建坚固的生产就绪ML管道至关重要。其中之一是退出处理程序,因此,本文解释了其在从HuggingFace部署GPT-2并使用Vertex AI Pipelines和Locust测试其性能的背景下的用法。
介绍退出处理程序
在创建强大的产品时,必须考虑代码中的错误处理。Python提供了“try-except”语句,用于捕获运行时遇到的错误。此外,Python的“try”语句还具有另一个可选子句“finally”,旨在定义必须在所有情况下执行的清理操作。
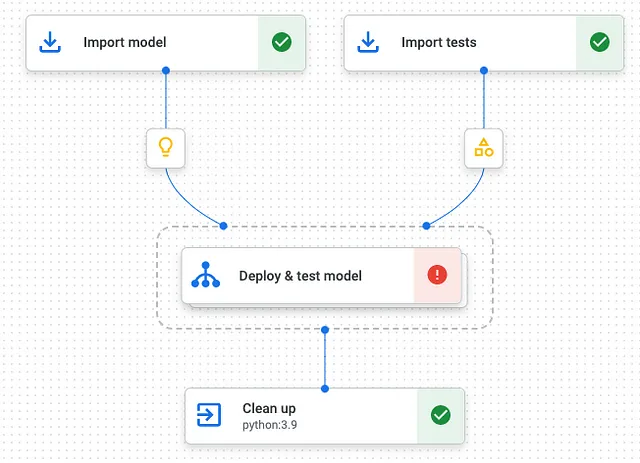
Kubeflow通过引入“Exit Handlers”来提供类似的控制流程。下面的示例(见图1)确保您在Kubeflow管道中清理模型训练期间的资源,类似于在本地使用“finally”语句所实现的效果。

你可能会注意到Kubeflow要求你在创建数据集和训练模型之前定义清理任务。然而,你的退出处理程序仍然会在你的业务逻辑之后运行。考虑以下情况,你的流水线将执行Kubeflow的退出处理程序:
- 管道任务顺利完成
- 在退出处理程序块内的任何管道任务失败
- 管道被取消了。
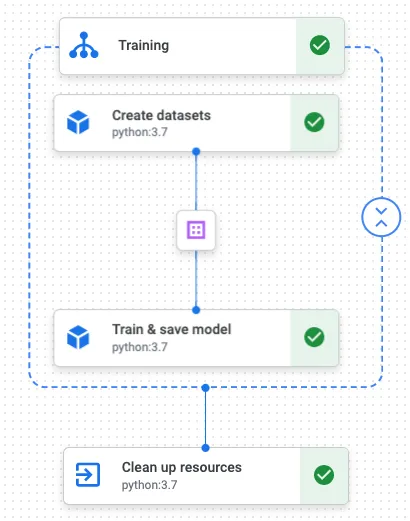
创建强大的机器学习流程。
常见的AI + ML用例需要一个训练和预测流程来提供离线预测。然而,某些用例(例如在聊天机器人的上下文中)通常需要一个API来提供根据用户输入的答案、摘要或推荐等即席预测。在Vertex AI中,您可以部署模型端点来包装您的模型成为一个API,可以在用户请求时进行查询。例如,我们将部署来自HuggingFace的开源大语言模型(LLM)GPT-2,以根据用户提示提供预测。
不论您如何自动化模型的部署,都很重要确保您的API能正确提供预测并满足延迟要求,以保持最终用户的满意度!基于我们对Kubeflow和退出处理程序的了解,让我们在Vertex AI管道中实现一个强大的部署工作流:
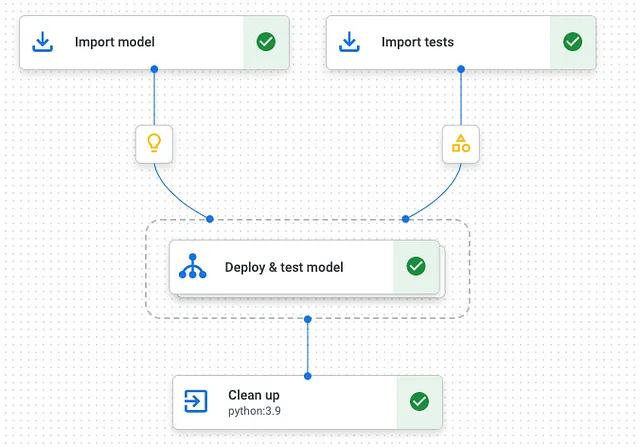
部署流水线分为三个部分:
- 导入模型和测试:从 Vertex AI 模型注册表和云存储导入您的预训练开源模型和测试,以及性能测试。
- 部署和测试模型:部署Vertex AI端点和模型,并对部署的模型API运行性能测试。
- 清理资源:删除部署的模型和端点。
这种管道结构使我们能够声明清理操作作为退出处理程序运行,即使任何一个任务失败或管道被取消也是如此。 如果您部署了具有GPU加速的模型,这一点尤其重要,以保持低成本。
以下代码展示了一个低代码实现的 ML 流程,其中使用了 Google Cloud Pipeline 组件和 Locust:
from kfp.dsl import pipeline, importer, ExitHandler
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp, ModelDeployOp
from .locust_component import LocustTestsOp
@pipeline
def deploy_and_test_model_pipeline():
# 1. Import model and tests
import_model_op = importer(...).set_display_name("Import model")
import_tests_op = importer(...).set_display_name("Import tests")
# 3. Clean up resources
exit_handler_op = EndpointDeleteOp(...).set_display_name("Clean up")
with ExitHandler(exit_handler_op, name="Deploy & test model"):
# 2. Deploy and test models
create_endpoint_op = EndpointCreateOp(...).set_display_name("Create endpoint")
deploy_model_op = ModelDeployOp(...).set_display_name("Deploy model")
locust_tests_op = LocustTestsOp(...).set_display_name("Test model performance")1. 导入模型和测试
管道使用导入节点从模型注册表导入预训练模型,确保模型可用于下游任务。与此同时,我们会使用locustfile.py的形式从云存储中导入测试,因为我们将使用Locust测试模型的性能。使用Locust监视您部署的模型的延迟的测试可以非常简单:
import google.auth
import google.auth.transport.requests
from os import environ as env
from locust import HttpUser, task
class VertexEndpointUser(HttpUser):
host = env["VERTEX_AI_ENDPOINT_HOST"]
path = env["VERTEX_AI_ENDPOINT_PATH"]
def on_start(self):
# authenticate using default credentials
creds, _ = google.auth.default()
creds.refresh(google.auth.transport.requests.Request()
self.client.headers = {"Authorization": f"Bearer {creds.token}"}
@task
def request_prediction(self):
# send a prediction request to the Vertex AI endpoint
prompt = "Write a dialog using Shakespeare language."
body = {"instances": [{"text": prompt}]}
with self.client.post(self.path, json=body, catch_response=True) as res:
if res.status_code == 200:
res.success()
else:
res.failure(f"Status code: {res.status_code} Reason: {res.reason}")2. 部署和测试模型
我们使用模型和端点组件中的“EndpointCreateOp”和“ModelDeployOp”任务来创建模型端点并将模型部署为API。为了运行性能测试,我们实现了一个自定义任务,将Locust包装在Kubeflow组件中,以执行先前在导入节点中定义的性能测试。
蝗虫组件将测试结果作为HTML工件输出到Google Cloud Storage。由于Vertex AI Pipelines支持多种可视化类型,例如HTML或Markdown输出,因此您可以通过UI本地打开结果:

如图7所示,Locust测试报告总结了您的模型随着时间推移的延迟结果和请求的成功率。这些结果与Locust提供的其他有用信息将帮助您在将其投入生产环境供最终用户使用之前了解模型的性能。
3. 清理资源
在你的流程管道结束时,部署的端点会被删除以确保你不会再产生云端费用。回顾一下使用Kubeflow退出处理程序的优点,你的ML管道将对任务失败或管道取消变得更加强大,因为退出处理程序将在所有情况下执行。
从这里去哪里?
如果你对自行运行模型性能测试感兴趣,请关注我们的Medium账号,即将发布关于如何在Vertex AI Pipelines中使用Locust以及更多的Vertex AI提示和技巧。
你是否正在寻找可扩展的XGBoost或TensorFlow的训练和预测管道?请查看我们基于Google Cloud和Vertex AI的MLOps Turbo模板;我们感谢您对我们开源GitHub代码库的贡献!
Datatonic 是 Google Cloud 的年度机器学习合作伙伴,具有丰富的经验在开发和部署有影响力的机器学习模型和 MLOps 平台方面。需要帮助开发 ML 模型,或快速部署您的机器学习模型吗?请参阅我们的 MLOps 101 网络研讨会,在那里我们的专家会向您介绍如何开始规模化机器学习或联系我们,以讨论您的 ML 或 MLOps 需求!