使用生成式人工智能和霍比特来预测商业绩效。

多年来,华尔街利用他们能得到的任何数据来源,来预测股票市场的购买指引。起初仅仅是读报纸和股票行情报表,尽管这些公司通常不会分享他们的秘密,我们知道它已经发展到了复杂的手写算法、机器学习,当然现在是人工智能。然而,我想到,鉴于 ChatGPT 等生成性人工智能的成功,是否有一种新的方法?我很想知道这是否已经被尝试过,结果如何。就我个人而言,以下是我的想法。
如果你能够使用生成式AI来预测各行各业和企业的表现,那该多好呢?如果我们可以把企业表现视为由生成式AI写成的小说,看它随时间变化呈现出怎样的故事?目前,由于模型性能的限制,我们可能不太可能对皮秒级股票购买决策产生影响,但我们应该能够得出一些有趣的短期预测。
假设能够预测J.R.R.托尔金的小说《霍比特人》。如果开始是比尔博被甘道夫拜访,结束是指环被毁灭,那么在这两个时间点之间会有成千上万个事件(数据点)汇聚。但如果你知道了故事开始之前发生了什么,很多这些数据点都可以预测出来。
难道不是细节让我们如此热爱这个故事吗?随着故事的展开,我们了解了这段历史——这些数据点。我们了解了戒指是如何被创造出来的。我们了解了埃尔波尔、史矛革和孤山的历史。我们了解了那些最初拥有戒指的国王们的遭遇。我们了解了戈鲁姆以及他如何获得了那个可以统治所有戒指的戒指,以及它如何改变了他。
如果故事开始前我们知道所有的历史,我们会更能预测接下来会发生什么吗?我们现在对生成式人工智能(如ChatGPT)的实际使用经验表明我们会做到。虽然有些细节可能不同,但我认为故事会非常相似。
那么这与预测企业业绩有什么关系呢?嗯,如果我们把股票看作是历史和现状的结果,我们可以把它看作是隐藏在大量文本中的密集数学小说。
预测霍比特人的旅程
那么这在夏尔镇怎么工作呢?首先,让我们创建一个简单的线性图,列出从夏尔镇出发到返回途中发生的一系列事件。
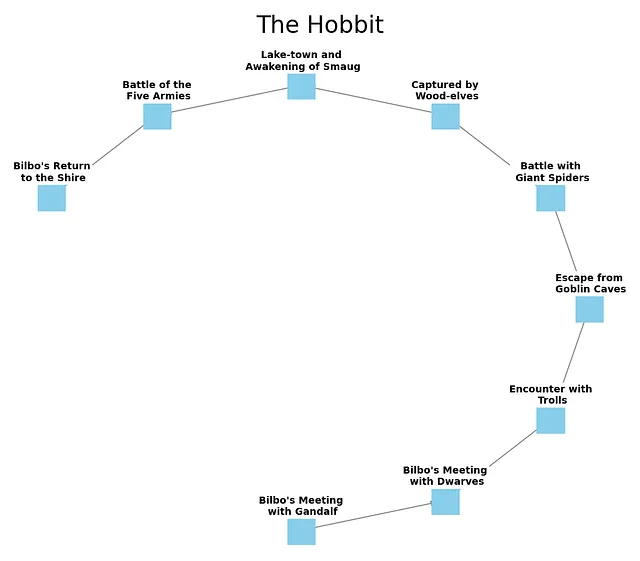
在图表中,我们可以看到故事中(即历史中)导致指环毁灭和回归家园的一些不同事件的呈现。但这并没有显示出导致故事开始的所有事情。我们随着故事的进展学到了这些事情,它们对事件以及它们发生的原因非常关键。因此,让我们在图表中添加一些历史。
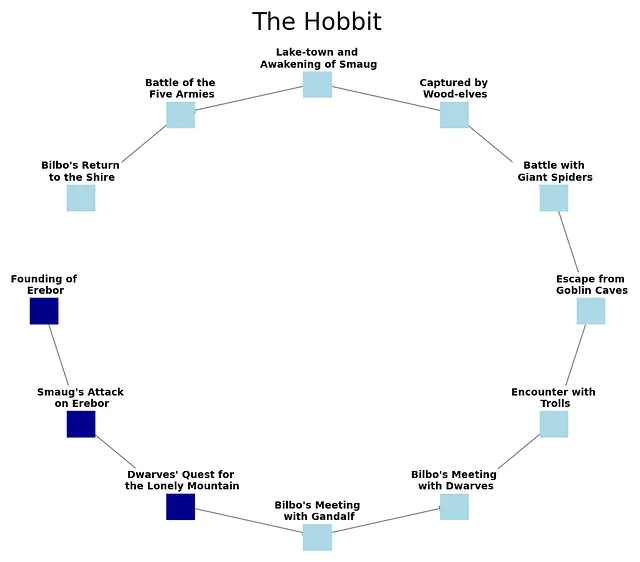
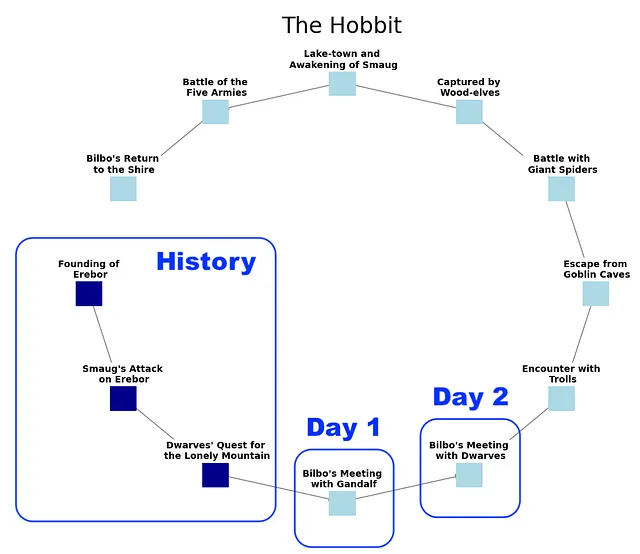
当然,这本小说还有更多细节。但你有了大概的想法。如果在读这本小说之前我们了解足够的历史细节,我们就可以预测像去莫尔多这样的事件。我们可以预测离开夏尔后每天发生的事件。
进入真实世界
现在,让我们把这个故事带进现实世界。如果我们的故事的结尾是预测一家公司或股票的价值,那么一切的前奏都是现实生活的历史,就像我们小说中的虚构历史一样,描述了这家公司是如何到达那里的。
注意:对于不熟悉的人,完成任务模型将像“从前有一个故事”一样使用输入,然后开始生成故事。您可以输入尽可能多的内容来启动它,但它会从那里继续。
注意:若你不熟悉,完成任务模型以“从前,有一个故事”之类的语句开头为输入并开始生成故事。你可以给它尽可能多的输入来启动它,但之后它将自行运作。
那么,从技术、生成式人工智能的角度来看,如果你拿着LLM并执行以下操作:
- 为完成一项任务进行微调。
- 在中土世界(《霍比特人》的世界)的所有历史上进行了微调。
- 用以下提示开始:「在地洞里住着一只霍比特。它的洞穴不是那种又脏又湿,到处都是虫子的味道发出难闻气味的,也不是干燥、赤裸、光秃秃的洞穴,连坐的地方和食物都没有:它是一个霍比特洞穴,这就意味着舒适。」
你可能会得到一个非常类似于我们都了解和喜爱的故事。
那么,如果我们对实际历史做类似的事情,可能会发生什么呢?你可能会问,这不就是我们已经有的 GPT4 吗?嗯,GPT4 真的很接近。这就是为什么它在很多事情上做得很出色。但是,还有一些差异:
- 它没有最新的信息。(它是用截止2020年的数据训练的。)
- 它是通过来自多个来源的非事实信息进行训练的。(社交媒体、小说、笑话等)
- 当它没有信息时,它会胡扯出来。(在行业中被称为“幻觉”).
因此,我们需要对其进行微调,设置一些防护栏,并不断为其提供新的内容。
对我们而言,历史将采取数百万数据点的形式,代表着:
- 有关公司以及其对销售、股价等的影响的新闻报道。
- 公司所在行业的新闻故事,以及它对销售、股价等的影响。
- 股票表现相对于新闻报道。
- Sorry, there is no English text provided for translation. Please provide the text for translation.
记住,霍比特人的图表只是对中土历史的简化。一个“真正”的图表根本不会是线性的。它很快就会变得难以阅读。因此,当我们把这个扩展到现实世界时,我们不会试图延伸那个视觉化。我认为我们会失去理智。
为我们的故事创造历史
那么我们该怎么做呢?嗯,我们已经列出了以上步骤。
- 首先,我们需要一个能完成优化的LLM。(想想我们完整的故事。)这方面有一些开源和商业的选择。
- 在世界金融和商业历史上进行微调。(好的,这很重要。)
- 设置一些路障。
第一步很简单。正如我所提到的,你可以找到很多可用的。如果你喜欢,也可以自己创建。如果你的使用情况像预测股票价值那样大,那么财务成本是值得的。然而,你需要决定花时间做这件事是否值得。推迟几个月让你的产品上线可能意味着你的竞争对手会先于你。而且,你始终可以稍后换上你的私人 LLM。
让我们从这篇文章开始:
“大众品牌首席表示,自2033年起,大众品牌将仅在欧洲生产电动汽车。” 链接
今天,我们可能会将这篇文章的情感分析作为标准ML算法(如XGBoost)的功能(输入),但更好的方法是获取整篇文章并利用其所有信息,例如:
"Schaefer说,未来十年内,大众品牌将缩减所提供的车型数量,并提高所有量产品牌(大众、西雅特、斯柯达和商用车)的利润率至2025年的8%。"
使用像这样的文章来进行微调,可以增加我们的“历史”,甚至让我们瞥见未来。这将有助于指导生成的IA进行预测,使我们生成的故事更准确。这项消息于2022年10月26日宣布,因此我们只能看到这将如何影响大众汽车的历史的开端。但是通过这种方法,包括所有行业和公司的文章,我们正在构建随着世界变化的世界图景。不仅是夏尔人之地,而是整个中土大陆。而且,这就是世界的运作方式,对吧?孤立地看待一个行业是太有限了。诸如燃料价格、全球供应问题、战争、稀有矿物、新发明/技术等问题。甚至AI也影响了电动汽车的采用。 (10年前谁能想到呢。)
生成训练数据
寻找、整理和清理可靠的训练数据总是创建出好的人工智能模型最重要的部分。数据的干净和准确也非常关键。然而,有几种方法可以使用人工智能实际上为我们创建训练数据。
一种方法是使用生成对抗网络(GAN)来帮助改善训练。简而言之,GAN涉及第二个模型,在训练期间对我们的模型进行“打分”。它会像这样工作:
- 第二个模型生成新文本(一篇新闻文章)可能或可能不反映过去的结果。
- 生成的(虚假的)文章将发送到第一个模型进行预测。
- 第二个模型已经知道第一个模型应该预测什么,因此如果预测出错,它会用来训练下一次的模型。
这个想法是让两个模型互相对抗,以帮助它们提高。这大大降低了您需要手动标记的训练数据的量。
另一种方法是使用人工智能来总结现有文章,以便我们可以消除不必要的噪音。我们甚至可以决定按主题将文章缩减为特定格式,如CSV文件或项目列表。人工智能在这方面表现得相当好,因此我们可以使用人工智能本身生成大量数据。
请在下方评论中告诉我您的想法。您认为这个想法可行吗?