使用LangChain和ChatGPT构建客户支持系统
简介
人工智能和自然语言处理已经彻底改变了客户支持的方式。在本文中,我们将探讨如何利用LangChain构建一个自助客户支持系统,该框架旨在简化使用大型语言模型(LLMs)创建应用程序的过程,以及ChatGPT,一种由OpenAI开发的高级语言模型。在此示例中,我们构建一个系统,对公司的支持文档进行索引,以回答实时的客户查询。
LangChain: 概述
LangChain是一个框架,旨在简化使用大语言模型(LLM)创建应用程序的过程。它于2022年10月作为开源项目推出,并广泛被开发者社区采用。它与亚马逊、谷歌和微软Azure等各种系统集成,具有新闻、电影信息和天气的API包装器,代码分析和生成工具,文档摘要和提取工具,网络爬虫子系统,以及更多的功能。
以下是 LangChain 的使用示例:
1. 个人助手:LangChain 可以构建带有独特特征和行为的个人助手。该框架提供了工具来引导助手的行为(通过 PromptTemplate)、记忆过去的交互(Memory)和理解应该采取的行动(Agent)。您还可以指定助手应该知道如何使用的工具。一旦您拥有了工具和代理,您就可以使用代理执行器将其付诸实践。
2. 文档问答:LangChain可用于在未经训练的语言模型上回答文档上的问题。这是通过“检索增强生成”过程完成的,即在给定问题的情况下,系统检索任何相关文档,将其与原始问题一起传递给语言模型,然后生成响应。该过程涉及加载文档、拆分文本、创建嵌入并将文档存储在索引中以便于查询。
3. 聊天机器人:LangChain 可以用来创建能够与用户进行对话的聊天机器人。这些聊天机器人可以从标准语言模型或专门的聊天模型中构建,具有通过 PromptTemplate 定义的行为,可以记住过去的交互(记忆)。这些聊天机器人通常在与其他数据源结合使用时更加强大,例如使用“文档问答技术”来使聊天机器人访问特定数据。4.
这只是一些例子,LangChain支持许多其他用例,如查询表格数据,与API交互,提取,评估,总结等,具体取决于应用程序的特定需求和目标。
在这篇文章中,我们想进一步探讨“文档问答”用例来构建我们的客户支持系统。
挑战
使用语言模型回答特定文档的问题的挑战在于语言模型需要学习它需要训练的信息。这就是“检索增强生成”概念发挥作用的地方。
在“检索增强生成”中,当提出一个问题时,首先要执行检索步骤以获取任何相关文档。然后将这些文档和原始问题传递给语言模型以生成响应。但是,为了使其正常工作,这些文档需要以可查询的格式进行格式化。
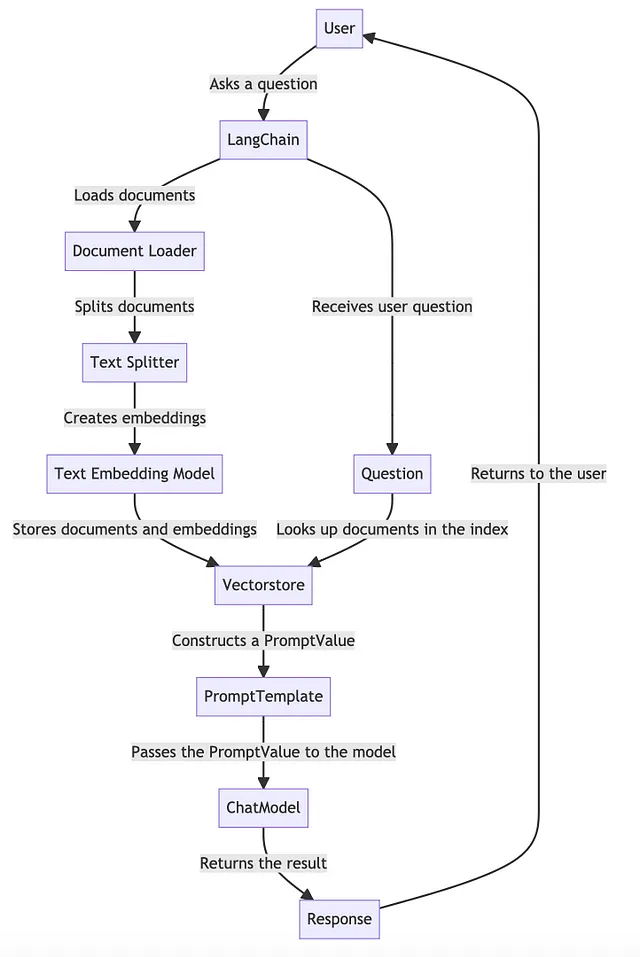
这个过程涉及的步骤如下:
1. 数据摄入:要使用语言模型与数据交互,必须将其以适当的格式保存。这个格式被称为索引。将数据放入索引中可以使下游操作更容易与其交互。使用最普遍的索引类型是向量存储。将文档摄入向量存储需要完成若干步骤:
- 加载文档(使用文档加载器)
- 分割文档(使用文本分割工具)
- 为文档创建嵌入(使用文本嵌入模型)
- 存储文档和嵌入向量到向量存储器。
2. 生成:一旦您拥有索引,就可以使用它来生成问题的答案。此过程涉及多个步骤:
- 收到用户问题
- 查找与问题相关的索引中的文件
- 构建一个PromptValue,使用PromptTemplate从问题和任何相关文档中获取信息。
- 将PromptValue传递给模型
- 获取结果并返回给用户1。
以上步骤提供了该过程的高层次想法。
让我们来看看实现可能会是什么样子。这并不是一个完全成熟的实现。它应该是一个起点,并展示高层次的方法:
索引支持文档
构建自助客户支持系统的第一步是索引所有支持文档。这包括加载文档,将它们分成各个部分,使用文本嵌入模型创建这些部分的嵌入,并将这些嵌入存储在Vectorstore中。本文末尾还添加了关于Vectorstores的更多信息。
让我们想象一下,您所有的支持文档都以文本文件的形式存储在一个目录中。首先,您需要将这些文档加载到您的系统中,将它们分成各个部分,使用文本嵌入模型嵌入这些部分,然后将这些嵌入存储到向量商店中。
以下是如何操作的实例:
from langchain import DocumentLoader, TextSplitter, TextEmbeddingModel, Vectorstore
# Step 1: Load documents
doc_loader = DocumentLoader(directory_path="path/to/support/documents")
documents = doc_loader.load()
# Step 2: Split documents
text_splitter = TextSplitter()
split_documents = text_splitter.split(documents)
# Step 3: Create embeddings
embedding_model = TextEmbeddingModel(model="gpt-3") # Assuming you have access to GPT-3
embeddings = embedding_model.embed(split_documents)
# Step 4: Store documents and embeddings in a vectorstore
vectorstore = Vectorstore()
for doc, emb in zip(split_documents, embeddings):
vectorstore.add(doc, emb)现在文件已经保存在Vectorstore中,您可以使用它来回答客户的问题。这是您可能会如何实现它:
from langchain import PromptTemplate, ChatModel
# Define a prompt template
prompt_template = PromptTemplate("{{user_question}}\n{{relevant_document}}")
# Load ChatGPT
chat_model = ChatModel(model="gpt-3")
def answer_question(user_question):
# Lookup documents in the index relevant to the question
relevant_documents = vectorstore.query(user_question)
# Construct a PromptValue from the question and any relevant documents
prompt = prompt_template.construct(user_question=user_question,
relevant_document=relevant_documents)
# Pass the PromptValue to the model
response = chat_model.generate(prompt)
# Return the result
return response在这个例子中,当用户提出一个问题时,系统从Vectorstore中获取所有相关文档。这些文档连同用户的问题一起被用来构建一个提示。然后这个提示被传递给ChatGPT,它会生成一个回答。
请注意,这只是一个简单的例子,旨在解释概念,可能仅涵盖LangChain的一些功能或构建客户支持系统的微妙之处。在实际情况下,您需要处理各种边缘情况,改进检索机制以返回最相关的文档,并调整提示和模型的参数以获得最佳响应。
现在轮到你了——用LangChain & ChatGPT建立一些非凡的东西,并分享你的经验。
Vectorestores的一些细节
一个向量存储库以高维向量空间存储文档,将每个文档表示为向量。这些向量通常通过称为嵌入的过程创建,该过程将文本转换为捕捉文本语义含义的数字向量。通常使用文本嵌入模型进行此转换,例如由大型语言模型如GPT-3提供的模型。
将文档存储为向量的优点在于可以根据语义相似性进行高效查询。当提出问题时,可以使用相同的文本嵌入模型将问题转换为向量,然后将这个向量与Vectorstore中的文档向量进行比较。最相似向量的文档(即余弦距离最小的文档)被认为与问题最相关。这个过程通常称为最近邻搜索。





