利用OpenAI的LLM和Astra DB向量搜索来实现有效的问答文档搜索:Jupyter笔记本演示

在今天快节奏的数字时代,能够在恰当的时候找到正确的信息非常关键。无论你是学生在寻找研究论文的答案,专业人士寻找深入的洞察某个主题,还是开发人员希望找到特定功能的一段代码,一个良好结构化的问答文档搜索都可以节省你宝贵的时间和精力。
在本文中,我们将探讨如何利用OpenAI的大型语言模型(LLM)和Astra DB来实现有效的问答文档搜索。我已经创建了一个详细的Jupyter笔记本,托管在Github和Google Colab上,以指导您完成这个过程,您可以在这里访问它:
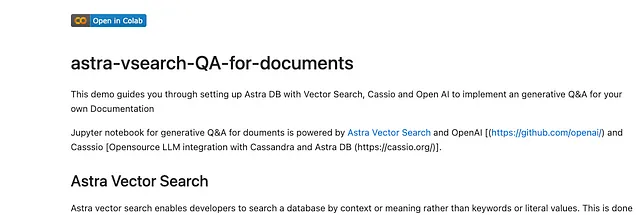
高层次概述:
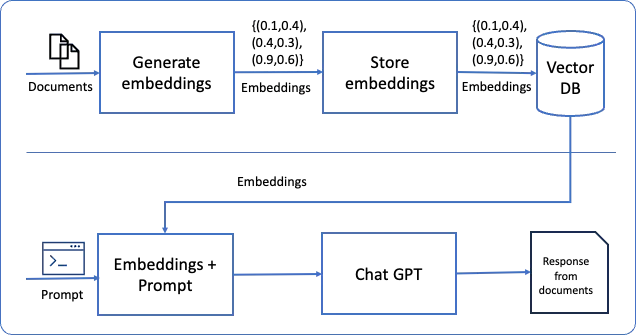
我们的项目利用OpenAI的LLM的能力来理解和分析文件的上下文,同时利用Astra DB强大的数据库功能来高效地管理和检索信息。本质上,我们结合了人工智能的能力和完全托管的云原生数据库,创建了一个强大的文件搜索解决方案。
旅程从使用OpenAI模型处理文件开始,该模型可以理解上下文、分解语义并创建最优化检索结构。然后将这些结构化数据存储在Astra DB中,这是一个可扩展、可靠且易于使用的多云数据库,来自DataStax,提供强大的向量搜索功能。
使用这个笔记本,您将拥有一个工作基线来构建您自己的问答文档搜索实现,能够高效地从文档数据库中检索信息,无论是 PDF、Word 文件还是纯文本文档。
预期结果:
通过完成本教程,您将会:
- 了解OpenAI最新LLM的原理和工作方式,以及如何将其与Astra DB相结合。
- 学习如何使用人工智能处理文档以获得语义理解。
- 使用Astra DB获得管理和检索结构化数据的实践经验。
- 开发一个功能性问答文档搜索引擎。
总之,这个样本为学习和实施人工智能和数据管理中一些最前沿的工具提供了绝佳的机会。你不仅能获得宝贵的技能,还能创造出一个实用的工具,可在从学术研究到商业洞见等多种场景中得到应用。
从今天开始,通过亲身实践探索人工智能和数据库的有趣交集。别忘了分享你的学习经验和任何你获得的见解!
快乐学习!